潜在的意味インデキシング(LSI)徹底入門
 (
( )
)
LSI については「特異値分解とLSIの意味」でも触れたことがありますが、この時はまだ理解不足だったので改めて解説したいと思います。
LSI (Latent Semantic Indexing) 1は検索などに用いられる次元圧縮手法です。
例えば、「車で行く」と「自動車で行く」は意味として全く同じですが、単語そのものを見ると「車」と「自動車」が異なるため違う文として扱われてしまい、「車」で検索しても「自動車で行く」という文がヒットしません。
しかし、「車」も「自動車」も同じ意味なので同じ文として扱われるようにしたいですよね。
これを実現する手法の1つが LSI です。
ベクトル空間モデル
LSI では Bag of Words によるベクトル空間モデルが使用されます。
要は単語の出現順を考慮せず、単語の出現頻度などによって文書をベクトルで表現するモデルです。
例えば次の4つの文書があったとします。
- d1: 会場には車で行きます。
- d2: 会場には自動車で行きます。
- d3: 会場には自転車で行きます。
- d4: お店には自転車で行きます。
自立語のみを抽出し、それらの頻度からベクトルを作成すると、次のような単語・文書行列ができます。
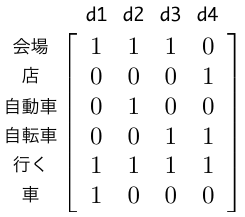
このように、単語という軸をとり、それらの出現頻度などを値とする空間の1点として文書を表現するのが Bag of Words によるベクトル空間モデルです。
上の例において、d1, d2 は「車」と「自動車」だけの違いであり、文の意味としては同じなのですが、d1 と d2 のコサイン類似度(コサインの値)は0.667と、それほど高い値ではありません。
単語を軸に取ると、このような言い換え表現や表記ゆれなどに対応できないので、単語の持つ潜在的な意味を軸に取ろうというのが LSI の発想です。2
単語・文書行列に対する特異値分解
LSI の肝は特異値分解で、特異値分解さえ理解できれば9割方理解したようなものです。
特異値分解はランク r の D という m x n の行列を次のような3つの行列に分解します。
(1)
ここで、U は m x r の列直交行列3、V は n x r の列直交行列、Σは対角要素に特異値σiを降順に並べた r x r の対角行列です。4
式 (1) に対して重み行列 W を導入すると、
(2)
となり、i番目の文書ベクトル(D のi番目の列ベクトル)は
(3)
と表すことができます。
U は列直交行列なので列ベクトルに関して1次独立であり、U が文書ベクトル空間の基底になっていることがわかります。
この各列ベクトルが潜在的意味という軸になります。
同様に、V は単語ベクトル空間(どの文書に何回現れたかで単語を表現する空間)の基底になっています。
具体例を挙げると、次のような単語文書行列があった場合、ランクが2というのはすぐにわかると思います。
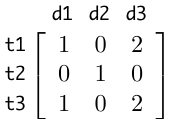
これを特異値分解すると、
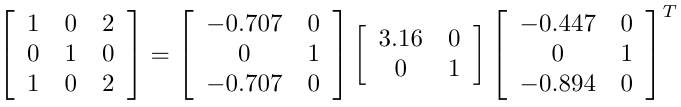
となり、確かに行列 U の各列ベクトルは文書ベクトルの基底になり、行列 V の各列ベクトルは単語ベクトルの基底になっています。
この単語文書行列の例では、例えば t1 が「医者」、t3 が「病院」だとすると、d1 と d3 の例から統計的に「医者」という単語が出現すると「病院」という単語も必ず同じだけ出現することがわかります。
特異値分解の結果では、「医者」と「病院」をセットにして「医療」という潜在的な意味を軸に取ることで1つの軸で表現できるということを意味しています。
LSIによる次元圧縮
式 (2) において、重み行列 W は
と表すことができるので、
が成り立ちます。
V が列直交行列なので vji は高々-1~1の値しか取りませんが、σj は特異値を降順に並べたものであるため、jが大きくなるにつれて確実に小さな値になります。
jが大きくなるにつれて wji が小さくなる傾向にあるので、式 (3) より、di を構築する上での基底 uj の重要度も小さくなると言えます。
この重要度の低い軸を削除するのが LSI による次元圧縮です。
LSI による次元圧縮方法には2種類あり、文書ベクトルの次元数はそのままでランク数(基底の数)を削減する方法と、文書ベクトルの次元数自体削減する方法がありますが、どちらも本質的には同じです。
便宜上、前者を「ランク削減による次元圧縮」、後者を「次元削減による次元圧縮」と呼ぶことにしますが、後者では当然ランク数も減りますし、そもそも本エントリーにおける「次元圧縮」とは「表現力を下げる」ぐらいの意味で捉えてください。
ランク削減
単語・文書行列 D が特異値分解によって
と分解されることは前述したとおりです。
ここで、分解した各行列の k + 1 列目以降を削除した行列 U(k), Σ(k), V(k) を考えると,
と近似できます5。これでランクが r から k に削減されます。
文書ベクトル単位で見ると、式 (3) より次のように近似したことになります。
このように、ランク削減による LSI では、文書ベクトルを座標系は元のまま(m 次元)で U(k) の張る低次元空間(つまりk 個の潜在的意味から成る空間)に射影します。
LSI はインデキシングと呼ばれるぐらいなので検索にも使われますが、検索クエリを q とすると、文書iとの類似度は
で算出できます。
文書iは基底の数を減らしているのにクエリはそのままというのは気持ち悪いですが・・・
次元削減
ランク削減による LSI では次元数はそのままで基底ベクトルの数を減らしましたが、次元削減による LSI では、U(k) の座標系(k 次元)に変換します。つまり、ベクトル空間の軸が潜在的意味になるように変換します。
潜在的意味の中でも重要な k 個の軸だけを取るようにします。
具体的には次のように左から UT(k) を掛けます。
文書ベクトル単位で見ると次のように表されます。6
検索クエリ q と文書iとの類似度は、q を同じ座標系に変換した上で算出するので、次のようになります。
LSIまとめ
LSI の意味するところですが、機械学習でいう過学習を緩和するようなものだと思います。
表現力が豊富なために文書を詳細まで表現できすぎて、本来似ている文書も違った文書として表現できてしまう。
そこで、重要度の低い情報を削減することで、本来似ている文書の類似度を上げることができる。
そんな感じかと思います。
全然違う文書を分けるために使われる情報(例えば特定のトピックに現れる単語のセット)は文書を構成する上で重要度が高い情報のはずです。
「車」と「自動車」のように表現の違いを分けるために使われる情報というのはそれに比べて重要度が低くなるでしょう。
ここで注意したいのは、単語頻度から文書ベクトルを構成すると「日常的によく使われる言葉」のような、どの文書でも頻繁に表れるような潜在的意味が最も重要な軸になるかもしれないということです。よって、単語頻度ではなく TF-IDF 値などから文書ベクトルを構成するのが一般的のようです。
以上、「ランク削減」と「次元削減」の2つの LSI について説明しましたが、既存の文書(単語・文書行列を構成する文書)をコサイン類似度でクラスタリングしたいといった用途ではどちらを用いても全く同じ結果が得られます。検索クエリに対して類似した文書を抽出したい場合もほぼ同じ結果が得られると思われます。証明は最後に載せておいたので興味のある方はご覧ください。
RによるLSIの例
これまでの説明からわかるように、SVD と行列演算が手軽にできる言語・ライブラリを使えばプログラミングが苦手でも LSI を実装することは簡単です。
理解を深めるためにも簡単な実例で締めたいと思います。
ベクトル空間モデルの説明で使った文と、検索クエリとして「会場 車」と入力された場合を想定してサンプルコードを書いてみます。
- d1: 会場には車で行きます。
- d2: 会場には自動車で行きます。
- d3: 会場には自転車で行きます。
- d4: お店には自転車で行きます。
- q: 会場 車
以下に R の例を記します。7
lsi_sample.R
library(RMeCab)
# 文書間の類似度を算出する関数
sim <- function(mat) {
mat <- t(mat)
ret <- list()
for (i in seq(length = ncol(mat) - 1)) {
a <- mat[, i]
b <- mat[, -(1:i), drop = FALSE]
ret[[i]] <- colSums(a * b) / sqrt(sum(a^2) * colSums(b^2))
}
ret <- unlist(ret)
attr(ret, "Size") <- ncol(mat)
attr(ret, "Labels") <- colnames(mat)
class(ret) <- "dist"
ret
}
makeDocMatrix <- function(doc, pos) {
D <- docMatrixDF(doc, pos = pos)
colnames(D) <- paste("d", seq(along = doc), sep = "")
D
}
lsi <- function(D, k) {
docsvd <- svd(D)
index <- 1:k
Dk <- docsvd$d[index]
Uk <- docsvd$u[, index, drop = FALSE]
Vk <- docsvd$v[, index, drop = FALSE]
list(Dk = Dk, Uk = Uk, Vk = Vk)
}
docs <- c("会場には車で行きます。",
"会場には自動車で行きます。",
"会場には自転車で行きます。",
"お店には自転車で行きます。")
pos <- c("形容詞", "動詞", "副詞", "名詞", "連体詞")
D <- makeDocMatrix(docs, pos)
cat("単語・文書行列\n")
print(D)
k <- 2
ret <- lsi(D, k)
cat("\n検索クエリq「会場 車」との類似度\n")
q <- (rownames(D) %in% c("会場", "車")) + 0
cat("元々の文書の類似度\n")
print(sim(t(cbind(D, q))))
cat("\nランク削減版の類似度\n")
lsi.rank <- t(t(ret$Uk) * ret$Dk) %*% t(ret$Vk)
dimnames(lsi.rank) <- dimnames(D)
print(sim(t(cbind(lsi.rank, q))))
cat("\n次元削減版の類似度\n")
lsi.dim <- t(ret$Uk) %*% D
print(sim(t(cbind(lsi.dim, q = c(t(ret$Uk) %*% q)))))
lsi_sample.R を実行すると次のような結果が得られます。
$ Rscript lsi_sample.R
to make data frame
単語・文書行列
d1 d2 d3 d4
会場 1 1 1 0
店 0 0 0 1
自動車 0 1 0 0
自転車 0 0 1 1
行く 1 1 1 1
車 1 0 0 0
検索クエリq「会場 車」との類似度
元々の文書の類似度
d1 d2 d3 d4
d2 0.6666667
d3 0.6666667 0.6666667
d4 0.3333333 0.3333333 0.6666667
q 0.8164966 0.4082483 0.4082483 0.0000000
ランク削減版の類似度
d1 d2 d3 d4
d2 1.000000000
d3 0.837087619 0.837087619
d4 0.349599386 0.349599386 0.805193724
q 0.678298315 0.678298315 0.431130039 0.003082754
次元削減版の類似度
d1 d2 d3 d4
d2 1.00000000
d3 0.83708762 0.83708762
d4 0.34959939 0.34959939 0.80519372
q 0.93838173 0.93838173 0.59644045 0.00426479
元のベクトル空間であれば「会場には車で行きます。」と「会場には自動車で行きます。」の類似度が0.667でしたが、LSI を適用することで類似度が1になっています。
また、検索クエリ「会場 車」と「会場には自動車で行きます。」の類似度も元のベクトル空間では0.408でしたが、0.678や0.938に改善されていることがわかります。
さて、特異値分解によってどのような基底が抽出されたかですが、行列 U は次のような行列になっていました。
u1 u2 u3 u4
会場 -0.5523710 0.44178757 2.775558e-16 -0.3688817
店 -0.1479718 -0.51379213 -4.440892e-16 0.5920183
自動車 -0.1771487 0.27430719 -7.071068e-01 0.3473423
自転車 -0.3460454 -0.62061893 2.220446e-16 -0.4715479
行く -0.7003427 -0.07200456 -5.551115e-17 0.2231366
車 -0.1771487 0.27430719 7.071068e-01 0.3473423
どのような潜在的意味の軸が抽出されたのか私なりの解釈を加えると、
- u1: イベントという軸(「会場」は「行く」もの)
- u2: 行き先&移動手段(多数派)という軸(「会場」には「車」で行くもの、「店」には「自転車」で行くもの)
- u3: 車の表現方法という軸(車を表す「車」と「自動車」を分ける)
- u4: 行き先&移動手段(少数派)という軸(「会場」には「自転車」で行くもの、「店」には「車」で行くもの)
となりました。今回は k = 2 としているので、車の表現方法という軸と少数派の行き先&移動手段という軸がなくなり、「自動車」と「車」が同一のものとして扱われたと解釈できます。
以上、簡単ですね!!
参考
「情報検索アルゴリズム」では LSI の解説をする上で線形代数の基礎的な部分から丁寧に説明してあります。

ランク削減による LSI は行列 D(k) を作成するとメモリを大量に消費してしまいますが、いちいち D(k) を作成しなくてもコサイン類似度を計算する方法についても触れています。
最後に載せてあるおまけに出てくる式の一部もこちらの本の内容を使わせていただきました。
検索の基礎的な内容を知りたいという方にはオススメです!
おまけ
ランク削減による LSI と次元削減による LSI に関して、既存の文書をクラスタリングしたいといった用途ではどちらを用いても全く同じ結果が得られるし、検索クエリに対して類似した文書を抽出したいといった用途でもほぼ同じ結果が得られると思われる、と述べましたがその証明を行います。
ここではi番目の文書ベクトルを
と表すことにします。
そうすると、 ランク削減で述べたように検索クエリ q とのコサイン類似度は次のように展開できます。
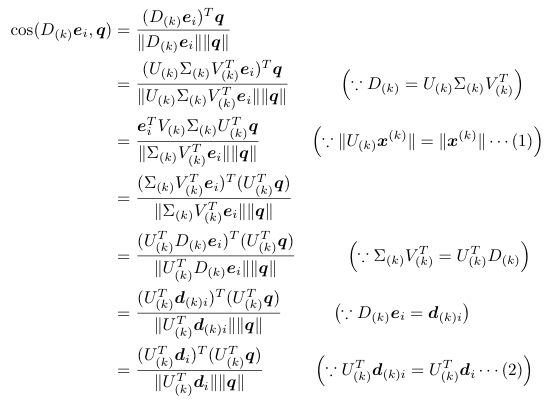
途中の式の (1) と (2) について証明します。
(1) に関しては U(k) が列直交行列であることを思い出すと、
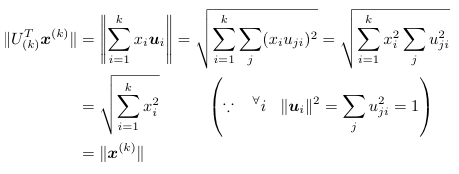
のように証明できます。
(2) に関しては
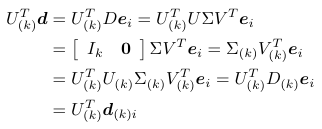
となります。2行目がちょっとインチキ臭いですが・・・
以上より、ランク削減による LSI の類似度は
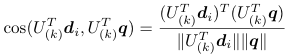
ということがわかりました。
一方、次元削減によるコサイン類似度は次のようになります。
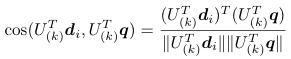
これはランク削減で出てきた類似度と微妙に分母が違うだけということになります。これが、検索クエリに対して類似した文書を抽出したいといった用途でもほぼ同じ結果が得られると思われる根拠です。
また、
の場合はどちらの式もちょっとした式展開で全く同じ式になることがわかります。
よって、既存の文書(単語・文書行列を構成する文書)をコサイン類似度でクラスタリングする場合はどちらの手法も全く同じ結果になります。