正規表現の先読み・後読みを極める!
 (
( )
)
柔軟性の高い正規表現を書こうとすると、避けて通れないのが先読み・後読みです。
先読み・後読みに関して、いままではとりあえず的な理解をしていたのですが、それだと説明できない正規表現に遭遇したので、説明できるまで理解を深めてみました。
とりあえず的な理解
正規表現を使って間もない人が先読み・後読みを理解するための説明です。
肯定的先読み (?=pattern)
次の正規表現では直後に def がある abc(def は含まない)に一致します。
abc(?=def)
否定的先読み (?!pattern)
次の正規表現では直後に def がない abc(def は含まない)に一致します。
abc(?!def)
肯定的後読み (?<=pattern)
次の正規表現では直前に def がある abc(def は含まない)に一致します。
(?<=def)abc
否定的後読み (?<!pattern)
次の正規表現では直前に def がない abc(def は含まない)に一致します。
(?<!def)abc
先読み・後読みはアンカー
上記程度の理解だと次の内容を説明できません。1
abcで始まらない任意の文字列を抽出したい場合,/^(?!abc).*/のような正規表現を記述します.
これは「『abcで始まらない』を正規表現で表記すると?」という質問に対する回答です。2
この内容を理解するためには「先読み・後読みはアンカー」という考え方が必要になってきます。
アンカーとは文字列内の特定の位置を表す物であり、文字列の先頭を表す ^ や末尾を表す $ がそれにあたります。普通の正規表現では文字に対してマッチしますが、アンカーは位置に対してマッチします。
たとえ空文字列であっても全ての文字列には先頭が存在するので、/^/ という正規表現は全ての文字列にマッチします。
$ node
Welcome to Node.js v20.11.0.
Type ".help" for more information.
> /^/.test('')
true
> /^/.test('abcdef')
true
※test メソッドでは正規表現にマッチすると true を返します
下の図では赤矢印がアンカーのマッチした位置を示しています。
![]()
先読み・後読みがアンカーだという考え方の下、改めてそれぞれの表現を見ていきましょう。
肯定的先読み (?=pattern)
直後に pattern の現れる位置にマッチします。文字列を最初から走査していって、pattern が現れたら、その直前の位置にマッチするとも言えます。実際にマッチする位置より後に pattern が出現する、つまり先を読まないとマッチするか判断できないことが「先読み」の由来なんじゃないかと思います。
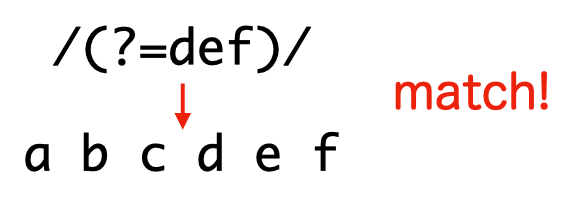
> /(?=def)/.test('abcdef')
true
上記の正規表現では def の手前の位置にマッチしているので、def の直前の文字列を全て抽出するには次のように正規表現を変更します。
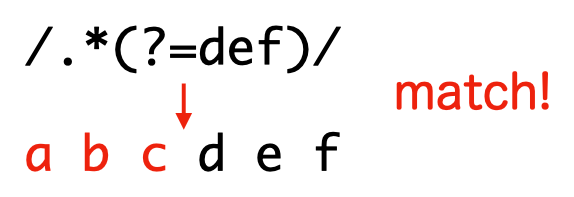
> /.*(?=def)/.exec('abcdef')[0]
'abc'
次のように (?=def) の前後の文字列も抽出すると、より一層理解が深まるかもしれません。
> Array.from(/(.*)(?=def)/.exec('abcdef'))
[ 'abc', 'abc' ]
> Array.from(/(.*)(?=def)(.*)/.exec('abcdef'))
[ 'abcdef', 'abc', 'def' ]
2 つ目の (.*) によって def が抽出されていることから、(?=def) はあくまで位置を表していることがわかるかと思います。
否定的先読み (?!pattern)
直後に pattern の現れない全ての位置にマッチします。つまり、肯定的先読みでマッチする位置以外にマッチします。
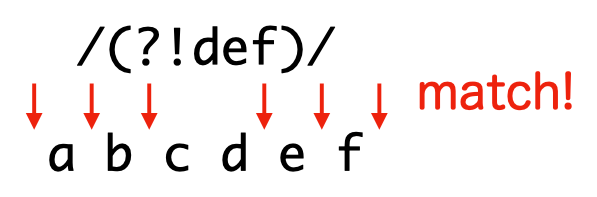
> /(?!def)/.test('abcdef')
true
次の正規表現では直後に def が現れない 1 文字を抽出します。上記の説明から、(?!def) は def の直前の位置にはマッチしないため、def の直前にある c は抽出されません。

> Array.from('abcdef'.matchAll(/.(?!def)/g)).map((m) => m[0])
[ 'a', 'b', 'd', 'e', 'f' ]
ちなみに次の正規表現は絶対にマッチしない正規表現となっています。def の手前の位置にマッチしないにも関わらず、マッチした位置の直後に def が存在する必要があるからです。
> /(?!def)def/.test('abcdef')
false
肯定的後読み (?<=pattern)
直前に pattern の現れるの位置にマッチします。文字列を最初から走査していって、pattern が現れたら、その直後の位置にマッチするとも言えます。
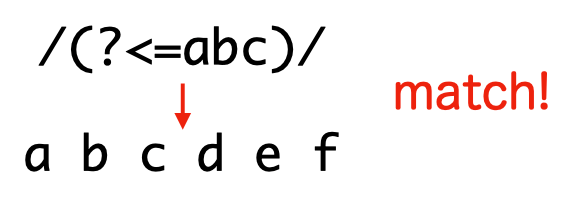
> /(?<=abc)/.test('abcdef')
true
否定的後読み (?<!pattern)
直前に pattern の現れない全ての位置にマッチします。つまり、肯定的後読みでマッチする位置以外にマッチします。
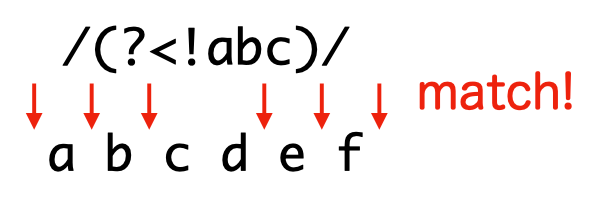
> /(?<!abc)/.test('abcdef')
true
先読みを使って abc で始まらない文字列かを判定する
まず、任意の位置に対して直後に abc が現れない位置を表現するには否定的先読みを使うことで実現できます。
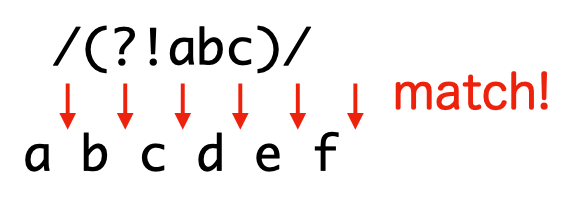
この結果に対して、文字列の先頭を表すアンカーである ^ も併用し、/^(?!abc)/ とすることで、先頭の直後に abc が現れない、つまり abc で始まらない文字列を表現することができます。
![]()
![]()
> /^(?!abc)/.test('abcdef')
false
ちなみに def で始まらない文字列かを判定するには /^(?!def)/ になります。
![]()
![]()
> /^(?!def)/.test('abcdef')
true
参考
「詳説正規表現」の序盤の方に、この辺の内容がかなり丁寧に説明されています。正規表現エンジンの仕組みなどにも触れられていて、普段正規表現を書く方は絶対に読んでおくべき一冊だと思います!!

-
「直後にabcがない先頭」と言うこともできますが、執筆当時の私の理解度では意味不明でした ↩
-
執筆当時の質問の URL が http://questionbox.jp.msn.com/qa2113057.html で、今は https://okwave.jp/qa/q2113057.html と思われますが、全く同じ回答はもう存在しませんでした ↩