Fluentd 入門 〜運用に必要な基礎知識〜

最近業務で Fluentd を触ることが出てきて入門したんですが、最初のうちはトラブルが起きた時に何が起きているのか、どう対処したら良いのかがさっぱりわからなかったので、「Fluentd ってログの収集とかに使われるやつでしょ?」程度の知識しかなかった過去の自分に向けて「とりあえずこれぐらいは知っておけ!」と言いたい内容をまとめてみました。
トラブルが起きた時にどの処理で問題が起きているのか素早くコードを追うことができて、データの消失を最小限に抑えつつ適切に対処できるようになることを目的としています。
なお、現時点で最新版の Fluentd v0.14.21 を対象にしています。
アジェンダ
Getting Started
サクッと試すには docker イメージを使うのもありですが、ruby の環境がある場合は gem でインストールするのが手っ取り早いでしょう。
% gem install fluentd
次に設定ファイルを作成します。fluentd --setup を実行することで指定したディレクトリにサンプルとなる設定ファイルが作成されます。
% fluentd --setup .
Installed ./fluent.conf.
作成した設定ファイルを指定して起動します。オプションで指定しない場合は /etc/fluent/fluent.conf が使われます。
% fluentd -c ./fluent.conf
起動したらイベントを送ってみます。{"message":"hello"} がイベントの内容で、debug.log がイベントのタグです。タグについては後述します。
% echo '{"message":"hello"}' | fluent-cat debug.log
そうすると Fluentd の標準出力として次のような内容が表示されるはずです。
2017-10-22 02:46:50.231440000 +0900 debug.log: {"message":"hello"}
Fluentd のアーキテクチャ
Fluentd では input plugin と output plugin 等、plugin を色々組み合わせることによって様々な入力元からのデータを様々な出力先に送ることを実現します。What is Fluentd? | Fluentd の図はそれを表しています。
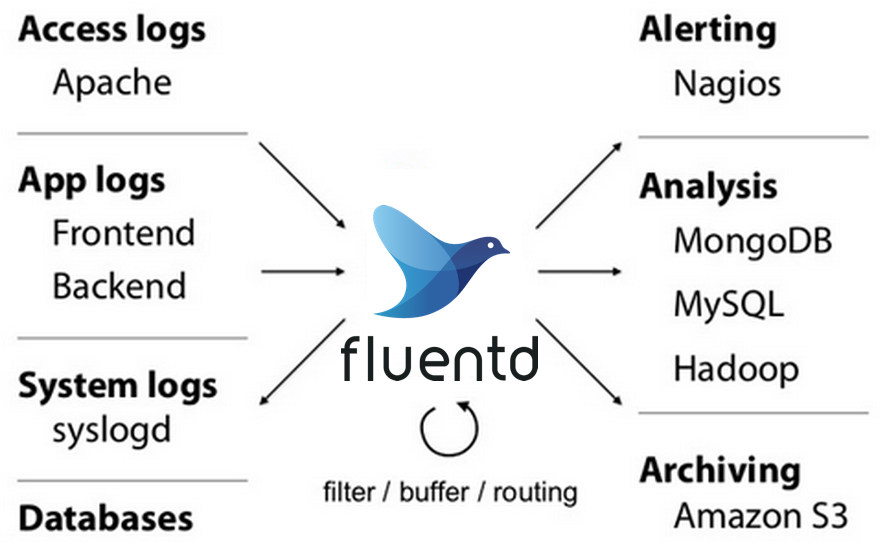
先ほどの例では forward input plugin と stdout output plugin を使っています。関連する設定だけ抽出すると次のようになります。
## built-in TCP input
## $ echo <json> | fluent-cat <tag>
<source>
@type forward
@id forward_input
</source>
## match tag=debug.** and dump to console
<match debug.**>
@type stdout
@id stdout_output
</match>
source タグは input plugin の設定で、match タグはルールにマッチしたタグのイベントを処理する output plugin の設定です。いずれも @type は使用する plugin の名前で、@id は識別子で Fluentd 自身のログ等に使われます。
forward input plugin はおそらく最もよく使われる input plugin で、fluent-logger、docker、forward output plugin 等からのデータを受け付けるのはこれです。
設定ファイルの詳細は Configuration File | Fluentd を参照してください。
具体的なデータの流れについては Buffer Plugin Overview | Fluentd に載っている次の図が非常にわかりやすいです。コードを読む時はこの図を頭に入れておくと良いでしょう。
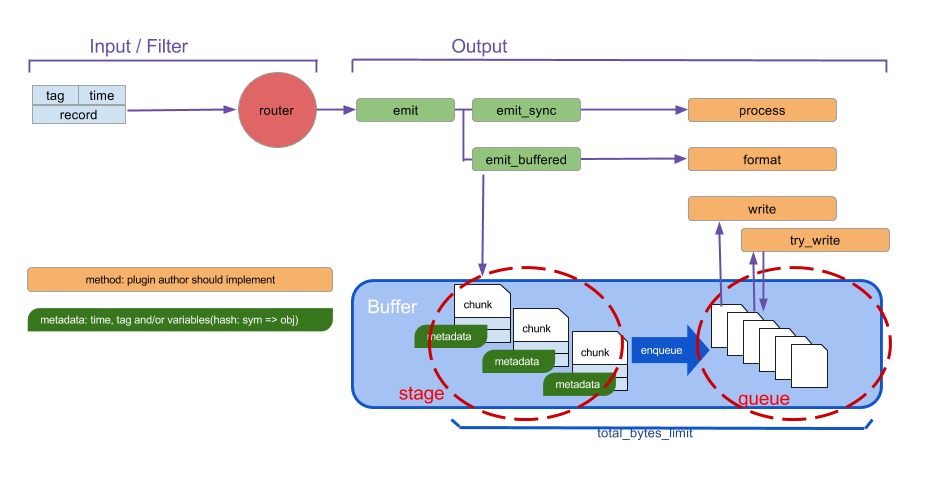
それでは主要な構成要素について見ていきます。
Processes
Fluentd には supervisor process と worker process の 2 種類が存在します。
Supervisor process
severengine を使って worker process が死んだ場合に新しい worker を立ち上げたりシグナルをハンドリングしたりします。fluentd コマンドを実行して起動するのはこれです。
エントリーポイントは Fluent::Supervisor#run_supervisor です。
Worker process
Fluentd のメインの処理を行います。ps コマンドでプロセスを表示した時に --under-supervisor option 付きで起動しているプロセスがこれです。
エントリーポイントは Fluent::Supervisor#run_worker です。
Threads
worker process には主に input thread、enqueue thread、flush thread の 3 種類の thread が存在します。input thread は便宜的に付けた名称です。
以下、各 thread について説明します。
Input thread
次の一連の処理を行います。
- イベントを受け取る
- イベントを router に流す
- イベントを output plugin に流す
- イベントを buffer に書き込む
- non-buffered output plugin であれば
processメソッドを実行する
- non-buffered output plugin であれば
chunk_limit_sizeやchunk_limit_recordsに到達した chunk を enqueue する
thread は input plugin ごとに割り当てられ、各 plugin の thread 数は実装次第です。
ソースコードを読む場合は対象となる input plugin の start メソッドを起点に読むと良いです。あるいは、router.emit* を実行しているメソッドを読めば雰囲気が掴めます。input plugin は lib/fluent/plugin/in_*.rb という命名規則で配置されるようになっています。forward input plugin であれば lib/fluent/plugin/in_forward.rb です。
典型的なケースのシーケンス図は次のとおりです。

上記のシーケンス図に関連するクラス図は次のとおりです。EventRouter::Rule はシーケンス図に出していませんが、タグに対応する output plugin を決定する際に使われます。

Enqueue thread
input thread のクラス図にも示したように、buffer は複数の chunk から成ります。chunk には主に staged と queued の 2 つの状態があり、staged は buffering 状態、queued は flush 待ちの queue に入っている状態という認識で差し支えないでしょう。
enqueue thread では staged 状態の chunk のうち、chunk が作成されてから flush_interval を経過したものを queued 状態にします。<buffer time> のように chunk keys に time が指定されている場合は timekey, timekey_wait 的にこれ以上新しいイベントを受け付ける必要のない chunk も queued 状態にします。
enqueue thread は buffered output plugin につき 1 thread 存在します。
なお、file buffer の場合、buffer の path として prefix.*.suffix を指定すると、ファイル名は prefix.#{state}#{chunk_id}.suffix になるので、ファイル名を見ることで staged 状態か queued 状態かがわかります。state の部分が b であれば staged 状態、q であれば queued 状態です。
cf. fluent/plugin/buffer/file_chunk.rb#L185-L204
ソースコードを読む場合は Fluent::Plugin::Output#enqueue_thread_run を起点に読むと良いです。
おおまかなシーケンス図を次に示します。

Flush thread
queued 状態の chunk を flush する thread です。ここで言う flush は file output plugin であればファイルへの出力、S3 output plugin であれば S3 へのアップロード (PUT) を意味します。出力が成功したら chunk は削除されます。
flush thread は buffered output plugin につき flush_thread_count の数だけ thread が存在します。
ソースコードを読む場合は Fluent::Plugin::Output#flush_thread_run を起点に読むと良いです。
おおまかなシーケンス図を次に示します。

Buffers
buffer には memory buffer と file buffer の 2 種類あります。buffer としてメモリを使うかファイルを使うかですが、両者を比較すると次のような特徴があると思います。
| 項目 | Memory buffer | File buffer |
|---|---|---|
| 速度 | 速い | I/O が発生する分若干遅い |
| 許容サイズ | 小(メモリ容量に依存) | 大(ディスク容量に依存) |
| 運用しやすさ | X | O |
| 実装 | 単純 | 複雑 |
特に重要なのは「運用しやすさ」で、file buffer だとデータをファイルに書き込むので worker が突然死んでもファイルに書き込まれているデータは消失しないことと、buffering されている様子がファイルを通して確認できることが大きなメリットです。
なお、file buffer の場合は起動時に buffer の path に対応するファイルがあれば chunk として認識するので、特別な復旧作業も必要ありません。
RootAgent によるライフサイクルの管理
worker process において、プラグインのライフサイクルを管理しているのが Fluent::RootAgent です。例えば、起動時に Fluent::RootAgent は output plugins、filter plugins、labels、input plugins の順に各インスタンスの start、after_start メソッドを呼び出し、終了時にはその逆の順番で stop、before_shutdown、shutdown、after_shutdown、close、terminate メソッドを呼び出します。
関連するクラスを簡略化すると次のようなクラス図になります。

シグナル
どのようなシグナルがあるかを理解しておくことは Fluentd を運用する上で必須と言っても過言ではないぐらい重要なことです。以下の内容は Fluentd’s Signal Handling | Fluentd の内容 + α です。
SIGINT or SIGTERM
graceful stop したい場合に supervisor に対して送ります。supervisor は SIGINT or SIGTERM を受け取ると worker に SIGTERM を送り、worker は SIGTERM を受け取ると Engine.stop を実行します。これにより、memory buffer の場合や file buffer で flush_at_shutdown が true の場合は shutdown する前に一度だけ try_flush が実行されます。リトライされないので、flush に失敗した場合 memory buffer の内容は消失します。
また、flush した後もしばらくはデータを受け取り続けるみたいなので、memory buffer の場合それらのデータは消失します。1
余談ですが、docker container の main process として Fluentd を動かしている場合、docker stop では SIGTERM が送られるので、timeout 以内に処理されれば flush 後にたまったデータ以外の消失はありません。
cf. docker stop | Docker Documentation
SIGUSR1
buffer を強制 flush したい場合に supervisor に対して送ります。
supervisoer は SIGUSR1 を受け取ると worker に SIGUSR1 を送り、worker は SIGUSR1 を受け取ると Fluent::Engine.flush! を実行します。これにより、staged 状態の chunk も queued 状態の chunk も全て flush されます。
なお、flush するために新しくスレッドを作るので、既存の enqueue thread や flush thread には影響を与えません。
SIGHUP
設定ファイルの更新等、worker を graceful restart したい場合に supervisor に対して送ります。supervisor は SIGHUP を受け取ると worker に SIGTERM を送ります。よって、worker の挙動は SIGINT or SIGTERM を送った時の挙動と同じです。supervisor が生きているので、worker が死ぬと supervisor が新しい worker を起動します。
SIGCONT
signal を送った supervisor or worker プロセスの全 thread の状態等を /tmp/sigdump-${pid}.log に出力します。これは sigdump の機能です。
どのような thread が存在するか確認したい時や worker process は生きてるのにイベントが全く処理されない時(deadlock の可能性がある時)に worker に送ると便利です。
SIGKILL
worker が deadlock で機能していない場合に worker を再起動するために worker に送ります。公式の見解ではないですが、そうするか supervisor ごと再起動するしか deadlock から復旧する方法はないと思います。SIGTERM と違って強制終了するので、memory buffer の内容や file buffer に書き込まれていない内容は全て消失するので注意してください。worker に SIGKILL を送る前に supervisor に SIGHUP や SIGUSR1 を送れば、一部の buffer は flush されるので被害を少なくすることができます。
fluent/fluentd#1723 のような問題もあるので、deadlock からは次の手順で復旧するのが良さそうです。
- supervisor に SIGHUP を送る
- これによって可能な限り flush しつつ worker の情報をクリアする
- deadlock に陥っているので worker 自体はいつまで経っても死なない
- worker に SIGKILL を送る
- supervisor が新しい worker を起動する
利用例
BufferOverflowError の解消
BufferOverflowError には主に total_limit_size を超えた時のエラー ("buffer space has too many data") と file descriptor を使い切った時のエラー ("Too many open files @ rb_sysopen") の 2 種類があります。
前者の場合は supervisor に SIGUSR1 を送ることで解決します。後者の場合は file descriptor を使い切っているので、新しい chunk も作れないし、enqueue もできないし、flush もできないということもあります。ダメ元で supervisor に SIGUSR1 を送ってみて、状況が改善しなければ supervisor に SIGHUP を送って worker を再起動すると良いでしょう。
なお、"Too many open files @ rb_sysopen" が出た場合は恒久対応として Increase Max # of File Descriptors に書いてあるように利用可能な file descriptor の数を増やすのが良いです。
Deadlock の解消
プロセスは生きているのに一部のイベントが処理されないということがあります。そんな時は worker に SIGCONT を送って deadlock が起きてないか確認します。
出力された sigdump の中に lock より先を処理している thread がなければ deadlock が起きていると言えます。よって SIGKILL の説明で述べたような手順で復旧すれば良いです。
なお、sigdump の内容は issue を報告する上で貴重な情報なので破棄しないようにしましょう。
cf. 実例: fluent/fluentd#1549
データが消失するケース
Failure Scenarios や Failure Case Scenarios でも言及されていますが、データが消失するケースについて考えてみます。
ここでは Fluentd High Availability Configuration に従って、app (fluent logger) -> log forwarder -> log aggregator -> log destination のような構成を考えます。また、全ての output plugin で file buffer を使う前提とします。
なお、fluentdでログが欠損する可能性を考える - sonots:blog も非常に参考になると思います。
app -> log forwarder 間での消失
log forwarder が一時的にダウンした場合、fluent logger は一定量まで送信できなかったデータをメモリに蓄え、次に送信する際にまとめて送信します。よって、メモリに蓄えられる上限に収まっているうちに log forwarder が復旧すれば消失しませんが、上限を超えると fluent logger はためていたログを全て破棄するので、ダウンしていた間のデータは全て消失します。
また、app と log forwarder が同じサーバに存在している場合、サーバを停止する際には app を停止した後に log forwarder を停止しなければ log forwarder 停止後に送信しようとしたデータは消失します。
log forwarder 内での消失
input thread が buffer に書き込むまでの間にエラーが発生した場合、そのログは消失します。例えば overflow_action が throw_exception (default) で BufferOverflowError が起きるとこのケースに該当します。
また、サーバの停止と共にストレージも削除するような設定になっていると、file buffer といえども flush_at_shutdown を true にしておかなければ、サーバの停止時に flush されていないデータは消失します。
log forwarder -> log aggregator 間での消失
log aggregator が一時的にダウンした場合、log forwarder は設定に応じてデータの送信をリトライします。retry_timeout か retry_max_times に到達するまでの間に log aggregator が復旧しなければログは消失します。もし secondary に file output plugin を指定しておけば、復旧時に手動で log aggregator へ送ることもできます。
log aggregator 内での消失
「log forwarder 内での消失」と同様のことが考えられますが、log forwarder の forward output plugin の require_ack_response を true にしておけば、消失を防ぐことができます。
require_ack_response が true だと、log aggregator は buffer に書き込んだ後に ack response を返します。log forwarder は ack response が一定時間内に返ってこなければリトライするので、log aggregator の input thread でエラーが起きた場合や deadlock で処理できない状態になっている場合でもログは消失しません。一方で、単に log aggregator 側の処理で時間がかかっている場合は二重にログを送信してしまうことになります。
log aggregator -> log destination 間での消失
「log forwarder -> log aggregator 間での消失」と同様のことが言えます。
おわりに
以上、最近学んだことをざっくりまとめてみました。
このエントリーを通じて Fluentd 周りでトラブルが起きた時に自信を持って行動できる人が増えると幸いです。
-
cool.io のバグなんじゃないかと思っています cf. https://github.com/tarcieri/cool.io/issues/61 ↩