F値に調和平均を使う理由
 (
( )
)
追記 2010/8/15: 自分の頭の中で「必要な文書の数」 = 「検索結果の文書の数」としてしまっていたところを修正しました
追記 2010/11/20: F値に調和平均を使う理由(再)というエントリーを書きました.こっちの方がわかりやすいと思います!
検索結果の評価指標に適合率(precision)と再現率(recall)があります.
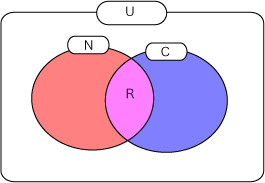
Wikipediaによれば
\[precision = \frac{R}{N}\]
適合率は検索結果として得られた集合中にどれだけ検索に適合した文書を含んでいるかという正確性の指標であり、再現率は検索対象としている文書の中で検索結果として適合している文書(正解文書)のうちでどれだけの文書を検索できているかという網羅性の指標である。適合率は、(R:検索された適合文書の数、N:検索結果の文書の数)
\[recall = \frac{R}{C}\]
によって、再現率は、(R:検索された適合文書の数、C:全対象文書中の正解文書の数)
によって求められる。適合率をあげれば再現率が下がり、再現率を上げれば適合率が下がる傾向にあるため、F値(F-measure)という尺度もよく用いられる。F値は適合率と再現率の調和平均であり、
\[\begin{align} F{\textit{-}}measure & = \frac{2 \cdot precision \cdot recall}{precision + recall} \\ & = \frac{R}{\frac{1}{2} (N + C)} \end{align}\]によって求められ、RをNとCの相加平均で割ったものに相当する。F値が高ければ、性能が良いことを意味する。
ここで出てくるF値ですが,どうして相加平均じゃなくて調和平均なんでしょう?
どの文献を見てみても,どうして調和平均を使うかについては言及されていないので,ちょっと考えてみました.
そもそも調和平均ってなんだろう?と思ったので典型的な例として平均速度を求める例を挙げてみます.
ある道を行きは a km/h,帰りはb km/hで走行しました.平均速度はいくつでしょう?
cf. 相乗平均、調和平均
(a + b) / 2 ではないですよ!
道のりを x kmとすると,行きにかかった時間は x / a,帰りにかかった時間は x / bです.
なので,全体で走行した距離は2x,全体でかかった時間は x/ a + x / b ということになり,平均速度は
ということになります.これが調和平均の典型的な例です.
速度の問題では
距離 = 速度 × 時間
ですが,情報検索の問題では
適合文書数 = 適合率 × 必要な文書数(検索結果の文書数)
または
適合文書数 = 再現率 × 必要な文書数(適合文書の総数)
となります.
※検索結果の文書数に関係なく再現率を一定とみなしています.あと,適合文書数は小数もあり得ます.適合率も一定とします.
平均速度の問題では,距離が行き帰り共通で,速度が異なる場合の平均を求めました.
時間が共通で距離が異なる場合の平均は単純に相加平均になります.
ということは,F値はある一定数の適合文書を取得したい場合を基準にしているんじゃないでしょうか?
検索結果の文書数や適合文書の総数はどうだっていいから,適合文書の数を確保したいわけです.
そういう場合に適合文書の割合がどうなるか?それがF値のような気がします.
つまり,適合文書数を x になるようにしたい.
いつもの検索結果の適合率で考えると,検索結果の文書は x / precision だけ必要.
一方,いつもの検索結果の再現率で考えると,検索結果の文書は適合文書の総数は x / recall だけ必要.
2つの指標に従って適合文書を 2x個取ってきた場合に検索結果の必要な文書(x / precision + x / recall個)に含まれる適合文書の割合はどうなるか?
平均速度の問題とアナロジーがとれています.
そもそも情報検索は適合文書だけを取り出すことが目的ではなく,
とにかく適合文書を取り出すことが目的だと思うので,この説明でしっくりきませんか?
2010/08/15追記
そもそも検索結果の文書数に関係なく再現率,適合率一定という仮定に無理があるかもしれませんが,
その場合,検索結果数をN,そのうちの適合文書数をR,適合文書数の総数をC,検索結果数を変えた場合の数をN’,そのうちの適合文書数をR’とすると,
適合率(検索の正確性)に従うと
が成り立ちます.これは適合率一定という仮定から問題ないかと思います.
再現率が一定という仮定は適合率一定という仮定よりも受け入れ難いかもしれませんが,
再現率が一定ということは適合文書がR’ほしい場合は適合文書数もそれに応じてC’に変えないといけないということを意味しています.
つまり,
が成り立つように適合文書の総数を変更しなければなりません.
これを変形すると
となるので,再現率(検索の網羅性)に従ってR’だけ適合文書がほしい場合,
検索する文書群の中にC’の適合文書が存在していなければならないことになります.
N’とC’をコストのようなものと考え,平均速度の問題でいう行きにかかる時間と帰りにかかる時間に相当するものとすると,
平均速度の問題とアナロジーがとれる気がします.
んー,だいぶ苦しい説明になった気が…