コロケーション抽出に使われる C-value とは何か?
 (
( )
)
コロケーションの定義が割りと曖昧な気がしますが、ここでは「よく利用される連続した単語列」とします。
例えば「辞書を引く」(イディオム)、「濃いコーヒー」(形容詞+名詞)、「交通安全」(複合名詞)とかです。
以下、[1] の要約みたいなものです。1996 年の論文なので、コロケーション抽出に使われる最新指標ってわけではないはずです。
コロケーション抽出の難しさ
例えば、”New York Stock Exchange”, “York Stock”, “New York”, “Stock Exchange” という単語列があったとします。
“New York Stock Exchange”, “New York”, “Stock Exchange” はコロケーションとして抽出されてほしいですが、”York Stock” は抽出されてほしくないですよね。
なので、単純に単語列の出現頻度だけを見ると上手くいきません。
そこで、コロケーションを抽出する指標として n(“York Stock”) - n(“New York Stock Exchange”) のように、”York Stock” の出現頻度から “New York Stock Exchange” のように “York Stock” を内包する単語列の出現頻度を引いてやることで不適切な候補を除くことを提案している論文もあります。
ところが、これも上手くいかないケースがあります。
例えば、”The Wall Street Journal” と “Wall Street” が出てくる文書からこの指標を使ってコロケーションを抽出しても “Wall Street” は抽出されません。
というわけで、C-value1 という指標を提案します。
C-value
C-value の定義は次のようになっています。
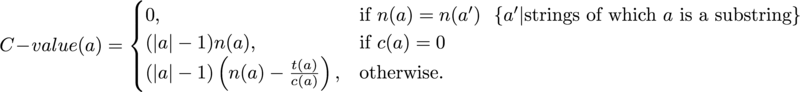
それぞれの記号の意味は次のとおりです。
- a: コロケーション
- |a|: a の単語数
- n(a): a の出現頻度
- t(a): a よりも単語数が多くて a を内包するコロケーションの出現頻度の合計(ちょっとわかりにくいので具体例を見てください)
- c(a): a よりも単語数が多くて a を内包するコロケーションの種類数
要は、
- a の単語数が多いと重要度が高い
- a の出現頻度が高いと重要度が高い
- a を内包する単語列の出現頻度が高く、それらの単語列の種類数が少ないと重要度が低い
- つまり、”Wall Street” が “The Wall Street Journal” と “Wall Street is” の 2 種類にしか含まれていない場合は微妙だけど、”The Wall Street Journal”, “Wall Street is”, “Wall Street analysts”, “The Wolf of Wall Street” のように色んな単語列に含まれる場合はコロケーションである可能性が高いということ
具体例
とあるコーパスから 3 回以上出現する単語列のうち “Wall Street” を含むものを抽出すると次のようになりました。これらの情報から C-value(“Wall Street”) を計算すると 33 になります。
| 単語列 | 出現頻度 |
|---|---|
| Staff Reporter of The Wall Street Journal | 19 |
| Wall Street Journal) | 26 |
| The Wall Street Journal) | 22 |
| Wall Street) | 38 |
| The Wall Street) | 23 |
| Wall Street analysts) | 3 |
| of The Wall Street Journal) | 20 |
| Reporter of The Wall Street) | 19 |
| of The Wall Street) | 20 |
各単語列の C-value などの値は次のとおりです。
| C-value | |a| | n(a) | t(a) | c(a) | Candidate Collocations |
|---|---|---|---|---|---|
| 114 | 7 | 19 | 0 | 0 | Staff Reporter of The Wall Street Journal |
| 112/3 | 3 | 26 | 22 | 3 | Wall Street Journal |
| 36 | 4 | 22 | 20 | 2 | The Wall Street Journal |
| 33 | 2 | 38 | 30 | 6 | Wall Street |
| 94/3 | 3 | 23 | 22 | 3 | The Wall Street |
| 6 | 3 | 3 | 0 | 0 | Wall Street analysts |
| 4 | 5 | 20 | 19 | 1 | of The Wall Street Journal |
| 0 | 5 | 19 | 19 | 1 | Reporter of The Wall Street |
| 0 | 4 | 20 | 20 | 2 | of The Wall Street |
“of The Wall Street Journal” の t(a) は 20 です。”of The Wall Street” を内包する単語列として “Staff Reporter of The Wall Street Journal”, “of The Wall Street Journal”, “Reporter of The Wall Street” の 3 つがありますが、t(“of The Wall Street”) ≠ n(“Staff Reporter of The Wall Street Journal”) + n(“of The Wall Street Journal”) + n(“Reporter of The Wall Street”) = 58 ではないことに注意です。
n(“Reporter of The Wall Street”) = 19、n(“Staff Reporter of The Wall Street Journal”) = 19 であることから、”Reporter of The Wall Street” は必ず “Staff Reporter of The Wall Street Journal” に内包されていることがわかります。
一方、n(“of The Wall Street Journal”) = 20 なので、”Staff Reporter of The Wall Street Journal” に内包されない形で 1 回出現していることがわかります。
よって、”of The Wall Street” は “Staff Reporter of The Wall Street Journal” に内包される形で 19 回、(”Staff Reporter of The Wall Street Journal” に内包されない)”of The Wall Street Journal” に内包される形で 1 回出現していることになり、t(“of The Wall Street”) = 19 + 1 = 20 となります。
c(“of The Wall Street”) が 2 であるのも “Staff Reporter of The Wall Street Journal” に完全に内包されている “Reporter of The Wall Street” はカウントしていないからです。
上記の値は論文の次の説明を愚直に Ruby で実装して出力しているので、導出方法に興味のある方は参考にどうぞ。

#!/usr/bin/env /ruby
n_grams = {
# n-gram => freq
%w(Staff Reporter of The Wall Street Journal) => 19,
%w(Wall Street Journal) => 26,
%w(The Wall Street Journal) => 22,
%w(Wall Street) => 38,
%w(The Wall Street) => 23,
%w(Wall Street analysts) => 3,
%w(of The Wall Street Journal) => 20,
%w(Reporter of The Wall Street) => 19,
%w(of The Wall Street) => 20,
}
class CandidateCollocations
include Enumerable
def initialize(n_grams)
@collocations = []
@c_value = {}
@n = Hash.new{ |h, k| h[k] = 0 }
@t = Hash.new{ |h, k| h[k] = 0 }
@c = Hash.new{ |h, k| h[k] = 0 }
longer_string_freqs = Hash.new{ |h, k| h[k] = [] }
max_size = n_grams.keys.map(&:size).max
n_grams.sort_by { |n_gram, _freq| -n_gram.size }.each do |a, freq|
@n[a] = freq
if a.size == max_size
@c_value[a] = (a.size - 1) * @n[a]
all_substrings(a).each do |b|
revise_t!(a, b)
revise_c!(a, b)
longer_string_freqs[b] << @n[a]
end
next
end
if longer_string_freqs[a].include?(freq)
@c_value[a] = 0
else
if @c[a].zero?
@c_value[a] = (a.size - 1) * @n[a]
else
@c_value[a] = (a.size - 1) * (@n[a] - Rational(@t[a], @c[a]))
end
all_substrings(a).each do |b|
revise_t!(a, b)
revise_c!(a, b)
longer_string_freqs[b] << @n[a]
end
end
end
n_grams.keys.each do |a|
@collocations << Collocation.new(a, @c_value[a], @n[a], @t[a], @c[a])
end
end
def each
@collocations.each do |collocation|
yield(collocation)
end
end
private
def all_substrings(a)
substrings = []
(2..(a.size - 1)).to_a.reverse.each do |size|
(a.size - size + 1).times do |i|
substrings << a[i, size]
end
end
substrings.uniq
end
def revise_t!(a, b)
@t[b] += @n[a] - @t[a]
end
def revise_c!(a, b)
@c[b] += 1
end
class Collocation
attr_reader :c_value, :n, :t, :c
def initialize(n_gram, c_value, n, t, c)
@n_gram = n_gram
@c_value = c_value
@n = n
@t = t
@c = c
end
def string
@n_gram.join(' ')
end
def size
@n_gram.size
end
end
end
puts "C-value\t|a|\tn(a)\tt(a)\tc(a)\tCandidate Collocations"
CandidateCollocations.new(n_grams).sort_by(&:c_value).reverse.each do |col|
puts [col.c_value, col.size, col.n, col.t, col.c, col.string].join("\t")
end
以上、C-value の説明でした!
参考
-
Wikipedia で C-value を調べると「一倍体ゲノムのDNA 量」の意味での C-value の説明が出てきますが全く別物です ↩