CloudWatch Alarms の暗黙の仕様(予想)

CloudWatch Alarms でアラームを設定しようと思って動作確認をしていたら、ドキュメントを読んでも理解できない挙動がいくつかあったのでまとめてみました。もしかしたらドキュメントに書いてある内容もあるかもしれません。また、バグじゃないかと思う挙動もあるので、その辺はそのうち修正されるかもしれません。
period に関係なく 1 分間隔で metric をチェックしている
High-Resolution アラームだと指定した 1 分より短い間隔でチェックしているかもしれませんが、普通のアラームだと指定した period に関係なく 1 分間隔でチェックしているようです。
アラームの基本的な考え方は Creating Amazon CloudWatch Alarms を見てもらうと何となく理解できると思いますが、具体例を挙げて説明してみます。
次のコードでは、3 分間に起きたエラーの合計数が 4 を超えることが 2 回繰り返されると ALARM になるアラームを作成しています。
Aws::CloudWatch::Client.new.put_metric_alarm(
alarm_name: "Alarm for Error count",
metric_name: "Error count",
namespace: "Test",
statistic: "Sum",
period: 60 * 3, # seconds
evaluation_periods: 2,
threshold: 4,
comparison_operator: "GreaterThanThreshold",
)
ここで、次のように、1 分間隔でエラー数を metric として取得できている状況を考えます。

この場合、アラームの統計値は次のように変化していきます。1 分ずつ window が移動していくイメージです。startDate, queryDate は History に含まれる情報に相当します。
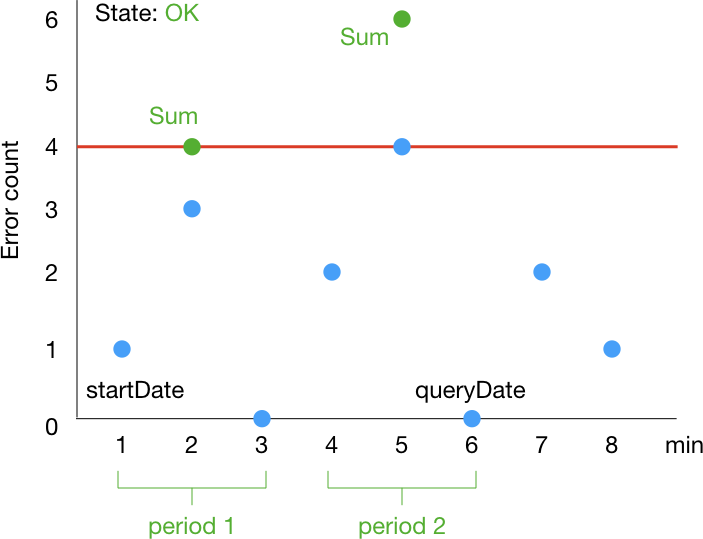
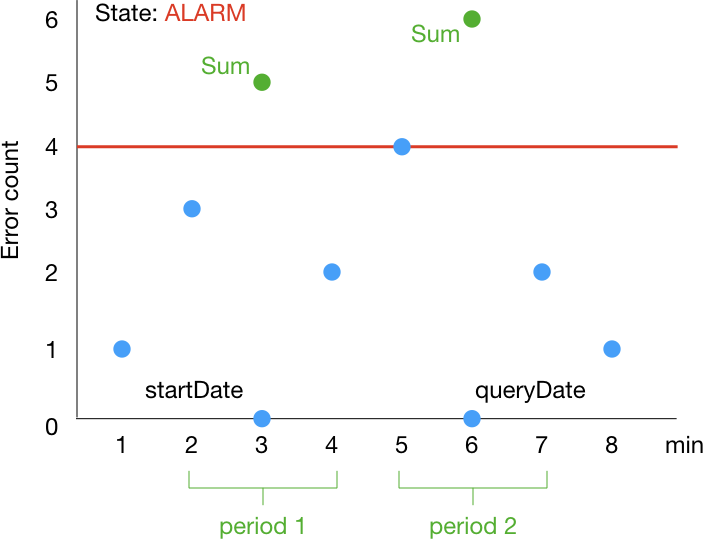
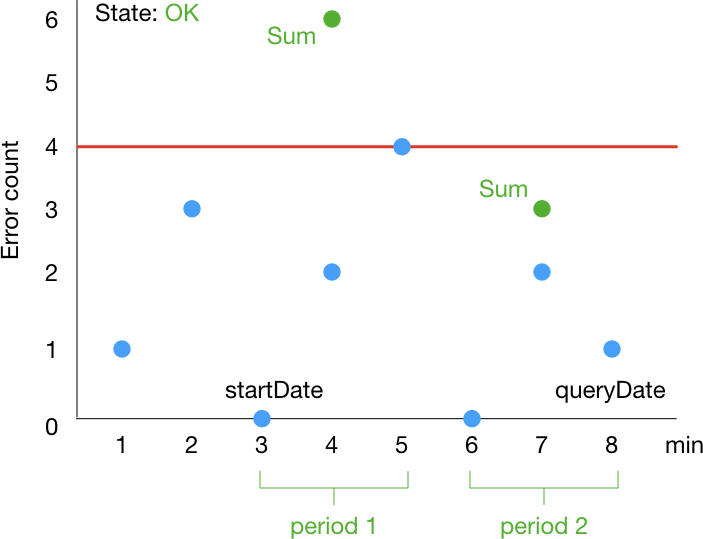
period が 3 分なのに ALARM になってから 1 分で OK に戻るのは意外に感じるかもしれません。
実際に次のコードを実行して確認してみます。
require "aws-sdk-cloudwatch"
NAMESPACE = "Test"
METRIC_NAME = "Error count"
BASE_METRIC_DATUM = {
metric_name: METRIC_NAME,
unit: "Count",
storage_resolution: 60,
}
def build_metric_datum(value: 1)
{ namespace: NAMESPACE,
metric_data: [BASE_METRIC_DATUM.merge(timestamp: Time.now, value: value)] }
end
client = Aws::CloudWatch::Client.new
client.put_metric_alarm(
alarm_name: "Alarm for #{METRIC_NAME}",
metric_name: METRIC_NAME,
namespace: NAMESPACE,
statistic: "Sum",
period: 60 * 3, # seconds
evaluation_periods: 2,
threshold: 4,
comparison_operator: "GreaterThanThreshold",
)
[1, 3, 0, 2, 4, 0, 2, 1].each do |error_count|
client.put_metric_data(build_metric_datum(value: error_count))
sleep 60
end
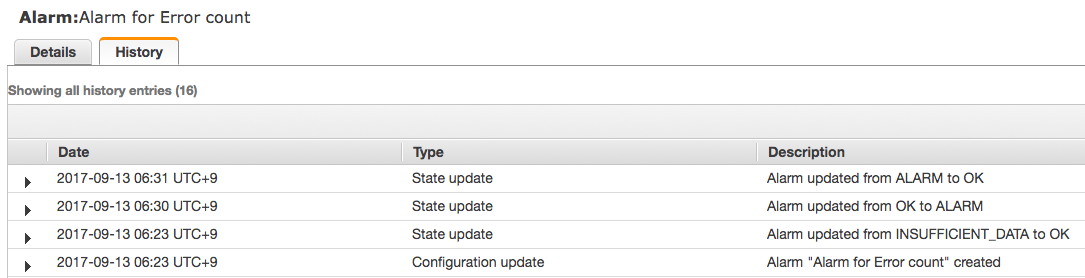
1 分で ALARM から OK に切り替わってますね!
同様に、evaluation_periods が 1 であれば period で指定した時間に関係なく合計エラー数が一定数を超えた時点で ALARM になります。
client.put_metric_alarm(
alarm_name: "Alarm for #{METRIC_NAME}",
metric_name: METRIC_NAME,
namespace: NAMESPACE,
statistic: "Sum",
period: 60 * 10, # seconds
evaluation_periods: 1,
threshold: 10,
comparison_operator: "GreaterThanThreshold",
treat_missing_data: "notBreaching",
)
client.put_metric_data(build_metric_datum(value: 11))
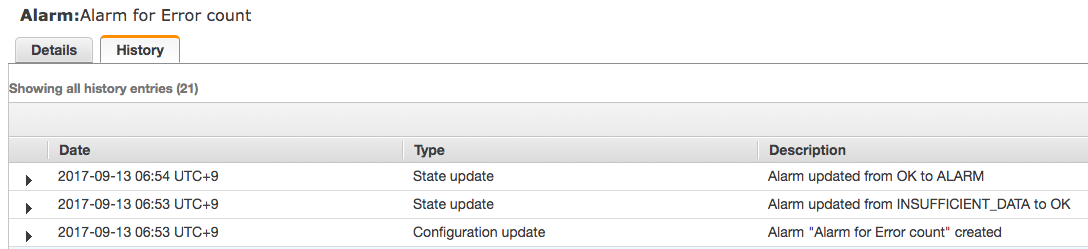
period が 10 分であるにも関わらず、アラームが作成されてから 1 分後に ALARM になっていますね!
missing data point があるとなかなか OK にならない
今まで data point がないと INSUFFICIENT_DATA という状態になっていましたが、今年の 3 月に data point がない場合の扱い方を指定できるようになりました。
cf. CloudWatch Alarms releases two new alarm configuration settings
これによって、Treat missing data as good (not breaching threshold) を指定すると、data point がない場合に閾値に収まっているものとみなすことができるようになりました。HTTPCode_ELB_5XX_Count や Errors のように data point がないことが正常なメトリックでも INSUFFICIENT_DATA にならずに OK になって便利ですね!
ところが、一度 ALARM になると data point がなくてもなかなか OK にならないようなので、そこは注意が必要です。
試しに、エラーがあった時のみエラー数を送る metric (Error count) と、エラーがあってもなくてもエラー数を送る metric (Error count with 0 value) に対して 1 分間にエラーが 1 つでもあれば ALARM になるようなアラームを設定して状態の変化を見てみます。
require "aws-sdk-cloudwatch"
NAMESPACE = "Test2"
BASE_METRIC_DATUM = {
value: 1,
unit: "Count",
storage_resolution: 60,
}
METRIC_NAMES = ["Error count", "Error count with 0 value"]
client = Aws::CloudWatch::Client.new
METRIC_NAMES.each do |metric_name|
client.put_metric_alarm(
alarm_name: "Alarm for #{metric_name}",
metric_name: metric_name,
namespace: NAMESPACE,
statistic: "Sum",
period: 60,
evaluation_periods: 1,
threshold: 0,
comparison_operator: "GreaterThanThreshold",
treat_missing_data: "notBreaching",
)
end
METRIC_NAMES.each do |metric_name|
client.put_metric_data(
namespace: NAMESPACE,
metric_data: [BASE_METRIC_DATUM.merge(metric_name: metric_name, timestamp: Time.now)]
)
end
sleep 60
client.put_metric_data(
namespace: NAMESPACE,
metric_data: [BASE_METRIC_DATUM.merge(metric_name: METRIC_NAMES[1], timestamp: Time.now, value: 0)]
)
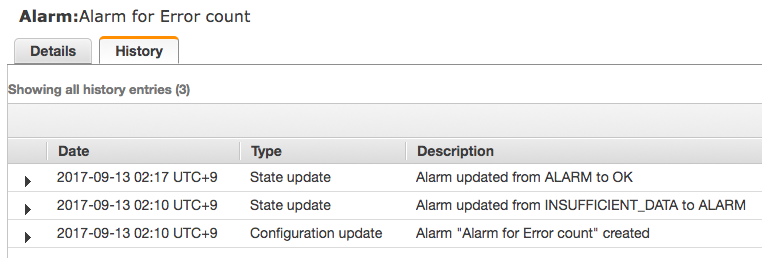
Alarm for Error count
エラーがあった場合のみエラー数を送ると、エラーがなくなってから OK になるまで 5 分程度かかっています。
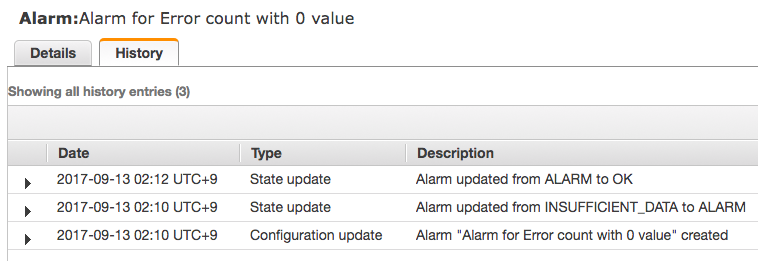
Alarm for Error count with 0 value
エラーがあってもなくてもエラー数を送ると、エラーがなくなってから OK になるまで 1 分しかかかっていないことがわかります。
なお、period を長くするとそれだけ ALARM から OK になるまでにかかる時間は長くなるようです。
missing data point を極力避けて評価する
バグなんじゃないかと思うんですが、Treat missing data as good としていても過去に遡って極力 data point の存在する期間で統計値を出そうとするみたいです。
次のように、3 分間に起きたエラーの合計数が 4 を超えることが 2 回繰り返されると ALARM になるアラームを作成したとします。
Aws::CloudWatch::Client.new.put_metric_alarm(
alarm_name: "Alarm for Error count",
metric_name: "Error count",
namespace: "Test",
statistic: "Sum",
period: 60 * 3, # seconds
evaluation_periods: 2,
threshold: 4,
comparison_operator: "GreaterThanThreshold",
treat_missing_data: "notBreaching",
)
ここで、エラー数の metric が次のように取得できたとします。
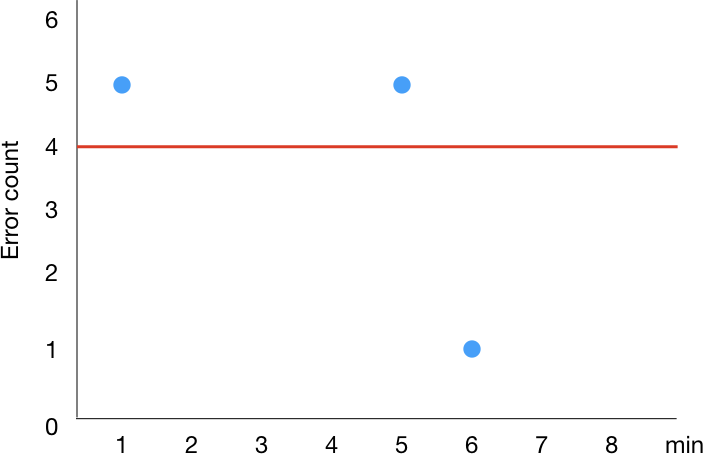
そうすると次のように早い段階で ALARM になります。
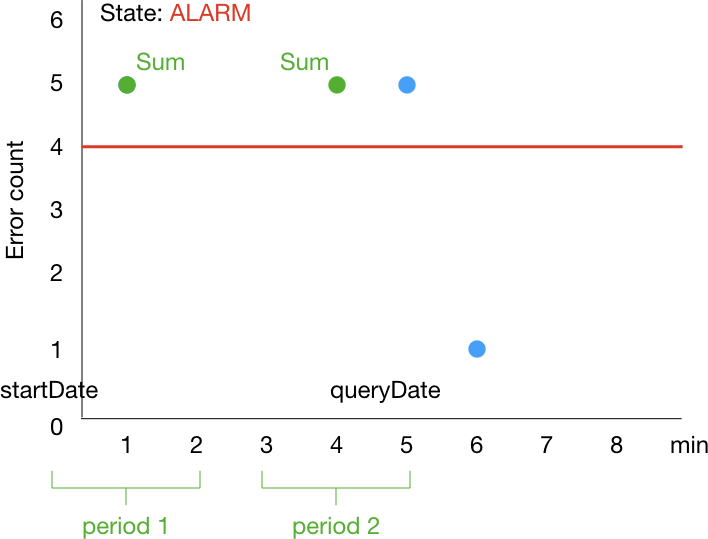
そして、個人的には次のように時刻が 7 のところに来た時点で OK になることを期待します。
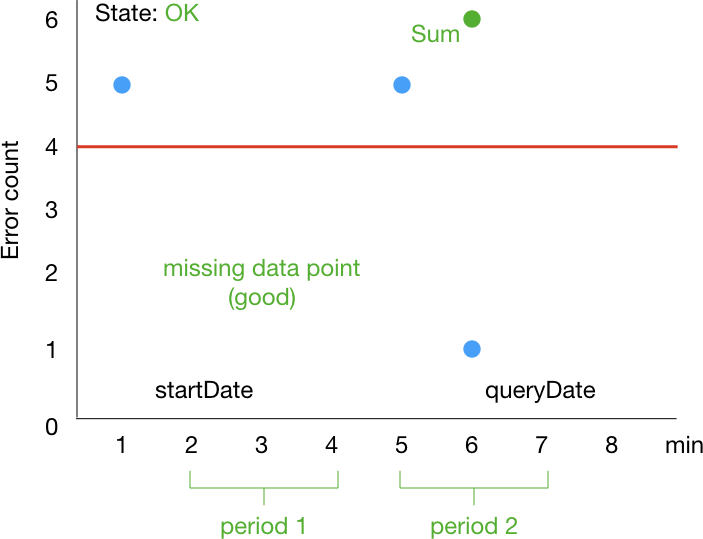
ところが、実際は次のように 8 のところに来るまで OK になりません。
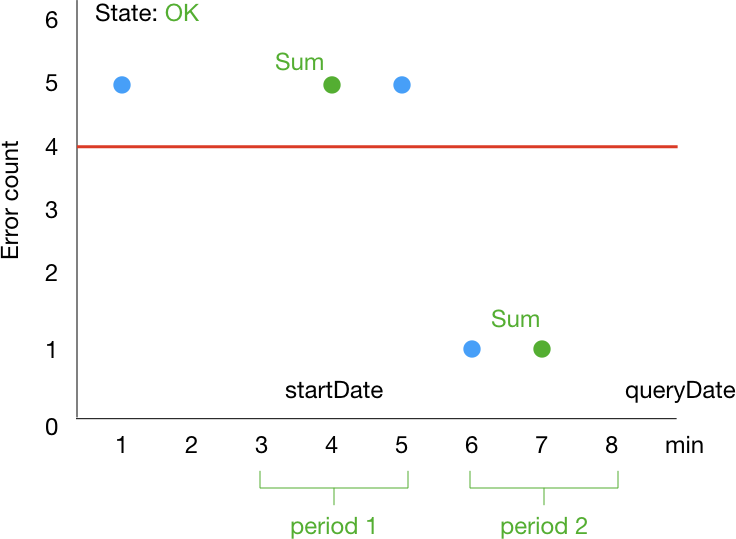
実際に次のコードで確認してみます。
require "aws-sdk-cloudwatch"
NAMESPACE = "Test3"
METRIC_NAME = "Error count"
BASE_METRIC_DATUM = {
metric_name: METRIC_NAME,
unit: "Count",
storage_resolution: 60,
}
def build_metric_datum(value: 1)
{ namespace: NAMESPACE,
metric_data: [BASE_METRIC_DATUM.merge(timestamp: Time.now, value: value)] }
end
client = Aws::CloudWatch::Client.new
client.put_metric_alarm(
alarm_name: "Alarm for #{METRIC_NAME}",
metric_name: METRIC_NAME,
namespace: NAMESPACE,
statistic: "Sum",
period: 60 * 3, # seconds
evaluation_periods: 2,
threshold: 4,
comparison_operator: "GreaterThanThreshold",
treat_missing_data: "notBreaching",
)
client.put_metric_data(build_metric_datum(value: 5))
sleep 60 * 4
client.put_metric_data(build_metric_datum(value: 5))
sleep 60
client.put_metric_data(build_metric_datum(value: 1))
ALARM から OK になるまでに 3 分かかってますね。
これぐらいならまだ良いんですが、metric が更新されない限り次のようにしばらく OK と ALARM を行き来するようです。
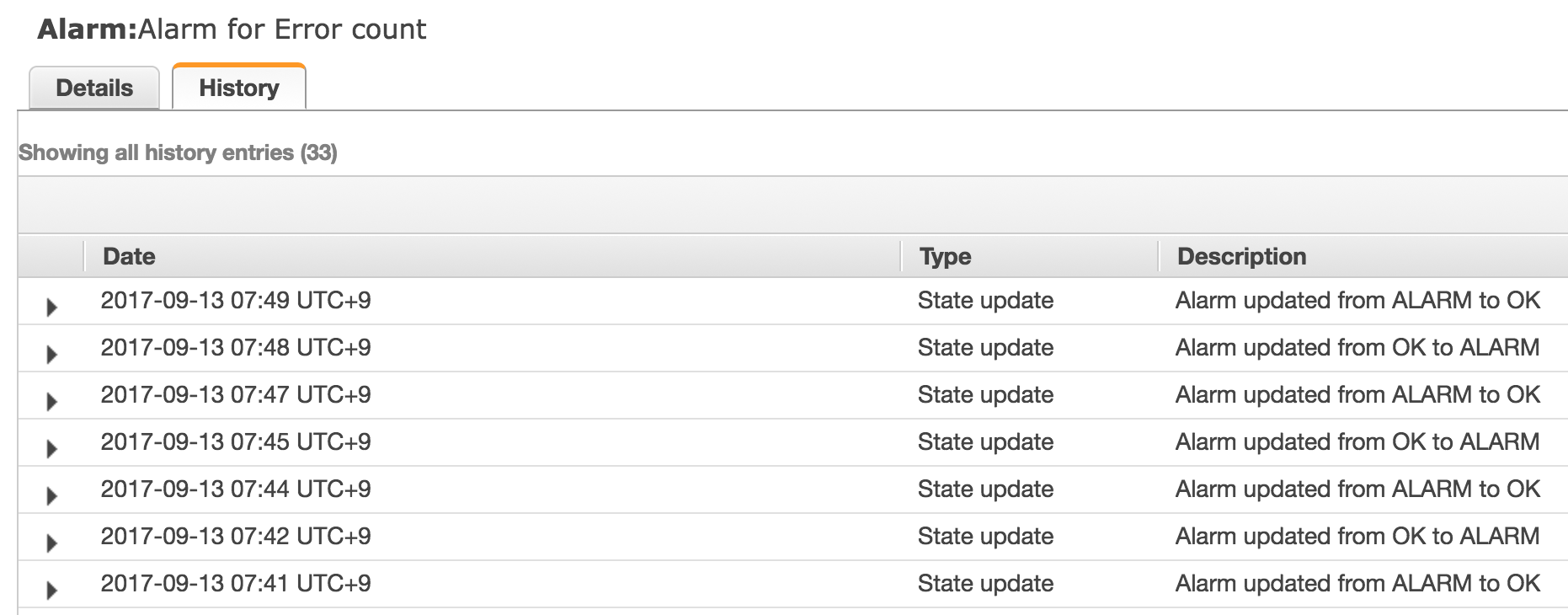
2017-09-13 07:42 UTC+9 の history data は次のとおりです。
{
"version": "1.0",
"oldState": {
"stateValue": "OK",
"stateReason": "Threshold Crossed: 1 datapoint [1.0 (12/09/17 22:38:00)] was not greater than the threshold (4.0).",
"stateReasonData": {
"version": "1.0",
"queryDate": "2017-09-12T22:41:21.433+0000",
"startDate": "2017-09-12T22:35:00.000+0000",
"statistic": "Sum",
"period": 180,
"recentDatapoints": [
5,
1
],
"threshold": 4
}
},
"newState": {
"stateValue": "ALARM",
"stateReason": "Threshold Crossed: 2 datapoints [6.0 (12/09/17 22:36:00), 5.0 (12/09/17 22:33:00)] were greater than the threshold (4.0).",
"stateReasonData": {
"version": "1.0",
"queryDate": "2017-09-12T22:42:21.435+0000",
"startDate": "2017-09-12T22:33:00.000+0000",
"statistic": "Sum",
"period": 180,
"recentDatapoints": [
5,
6
],
"threshold": 4
}
}
}
oldState.stateReasonData.startDate > newState.stateReasonData.startDate になってる??
2017-09-13 07:44 UTC+9 の history data は次のとおりです。
{
"version": "1.0",
"oldState": {
"stateValue": "ALARM",
"stateReason": "Threshold Crossed: 2 datapoints [6.0 (12/09/17 22:36:00), 5.0 (12/09/17 22:33:00)] were greater than the threshold (4.0).",
"stateReasonData": {
"version": "1.0",
"queryDate": "2017-09-12T22:42:21.435+0000",
"startDate": "2017-09-12T22:33:00.000+0000",
"statistic": "Sum",
"period": 180,
"recentDatapoints": [
5,
6
],
"threshold": 4
}
},
"newState": {
"stateValue": "OK",
"stateReason": "Threshold Crossed: 1 datapoint [1.0 (12/09/17 22:38:00)] was not greater than the threshold (4.0).",
"stateReasonData": {
"version": "1.0",
"queryDate": "2017-09-12T22:44:21.435+0000",
"startDate": "2017-09-12T22:35:00.000+0000",
"statistic": "Sum",
"period": 180,
"recentDatapoints": [
5,
1
],
"threshold": 4
}
}
}
元に戻った感じがしますね。
そして 2017-09-13 07:45 UTC+9 の history data は次のとおりです。
{
"version": "1.0",
"oldState": {
"stateValue": "OK",
"stateReason": "Threshold Crossed: 1 datapoint [1.0 (12/09/17 22:38:00)] was not greater than the threshold (4.0).",
"stateReasonData": {
"version": "1.0",
"queryDate": "2017-09-12T22:44:21.435+0000",
"startDate": "2017-09-12T22:35:00.000+0000",
"statistic": "Sum",
"period": 180,
"recentDatapoints": [
5,
1
],
"threshold": 4
}
},
"newState": {
"stateValue": "ALARM",
"stateReason": "Threshold Crossed: 2 datapoints [6.0 (12/09/17 22:36:00), 5.0 (12/09/17 22:33:00)] were greater than the threshold (4.0).",
"stateReasonData": {
"version": "1.0",
"queryDate": "2017-09-12T22:45:21.435+0000",
"startDate": "2017-09-12T22:33:00.000+0000",
"statistic": "Sum",
"period": 180,
"recentDatapoints": [
5,
6
],
"threshold": 4
}
}
}
queryDate 以外は 2017-09-13 07:42 UTC+9 と同じ・・・
以上から、なんとなく次の特性があるように思いました。
- missing data point は極力無視する
- 現在の state の
startDateより後に data point が存在しない場合は過去に遡って metric data の最も多い期間で統計値を計算する - 同じ
oldStateとnewStateを 2 回連続で行き来した場合は状態遷移しない
上記の例では
OKになった後に data point が存在しないので metric data の最も多い期間に戻ったらALARMになるstartDateより後の data point の存在する期間は元のOKになった期間なので元の状態に戻る- 1, 2 を繰り返す
- 2 回連続で同じ状態を行き来したのでこれ以上は状態遷移をしない
みたいな感じなのかなぁと。
まぁ、OK になってほしいのに ALARM になることはあってもその逆はなさそうなので、そこは安心ですね!
おわりに
CloudWatch Alarms の挙動をちゃんと理解して適切なアラームを設定したいですね!