Datadog メトリクスモニター作成入門

Datadog はモニタリング関連の SaaS ではおそらく最も利用されているサービスでしょうが、公式ドキュメントが豊富にある割には何から読み始めれば良いかわかりにくく、慣れるまでの道が険しい印象です。
本エントリーでは、Datadog が既に導入されている組織で、Datadog モニターを使って監視をしたいけど、モニターの設定方法がよくわからないといった方を対象に、メトリクスモニターの作成に焦点を絞って解説していきます。なお、あくまで Datadog の使い方についての解説であり、どのようなモニターを設定すべきかについては触れません。
メトリクスの収集についても触れたかったんですが、力尽きたので、メトリクスの収集については気が向いたら別エントリーを書きます。
アジェンダ
- メトリクスモニターの作成方法の基本
- Terraform で Datadog モニターを管理する際の注意点
- 知っておくと良いかもしれない豆知識
- おまけ 〜定期的に負荷のかかるサーバのメトリクスを収集する〜
メトリクスモニターの作成方法の基本
モニターは Terraform などで管理している組織も多いかと思いますが、慣れないうちは Web UI で項目を埋めて確認するのが良いです。下部に “Export Monitor” というボタンがあり、これをクリックすることでモニターの JSON 表現を確認できます。Terraform などでモニターを作成する際は、JSON の内容を参考にそれぞれのフィールドの値を指定すると良いでしょう。
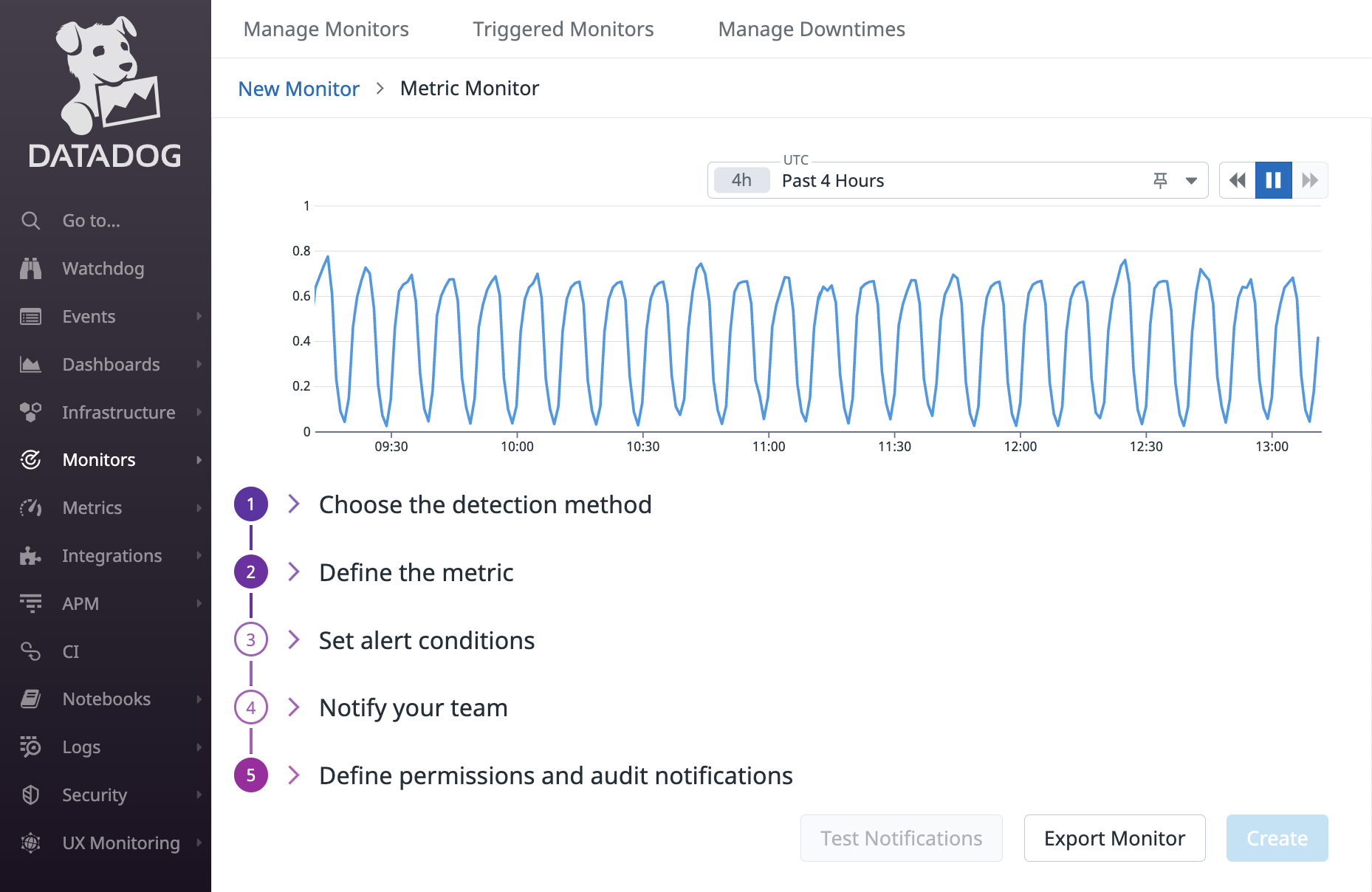
Web UI からもわかるとおり、モニターを作成するには最低限次のことを行わなければなりません。
- 検知方法の選択
- クエリの定義・評価期間と評価方法の指定
- アラート条件の指定
- 通知方法の指定
以降、検知方法は Threshold Alert を選択するものとして、残りの作業を滞りなく行えるようになるのに必要な知識について次の順で解説します。
- クエリの定義
- クエリの評価期間・評価方法・アラート条件の指定
- 通知方法の指定
なお、本文で言及するものもありますが、それぞれの作業について読むべき公式ドキュメントはおそらく次の辺りです。本エントリーと合わせて読むことで理解が深まると思います。
- メトリクスモニター作成の Getting Started
- Getting Started with Monitors
- メトリクスモニター作成の一連の流れはわかるが、それぞれの作業の詳細を理解するのは難しいかも
- Getting Started with Monitors
- クエリの定義について
- Metrics
- クエリの定義をしっかり理解するには必読
- Advanced Filtering
- メトリクスのスコープを指定する方法についての説明
- Advanced と言いつつ、かなり基本的な内容かつ量も少ないので、クエリの定義を理解するのに合わせて読むべき
- Metrics
- クエリの評価期間・評価方法・アラート条件の指定について
- Configure Monitors
- クエリの評価期間、評価方法、アラート条件の指定方法についての説明
- Configure Monitors で触れられていない full window の概念については Data Window 参照
- Configure Monitors
- 通知方法の指定について
- Notifications
- モニターの Notification の指定方法についての説明
- Variables
- 通知メッセージで使える変数についての説明
- Notifications
クエリの定義について
モニターで使うクエリの指定方法については Querying metrics に書かれています。本項を読んだ後に一読すると理解が深まるかもしれません。
上記のドキュメントに載っている用語を使うと、Web UI 上のクエリの各項目の意味は次のようになります。
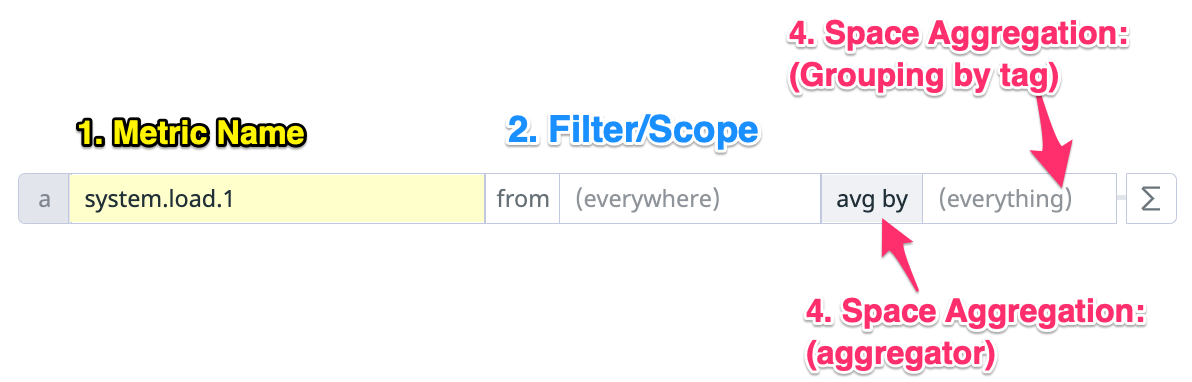
上図には Time Aggregation は載っていませんが、Time Aggregation で使われている rollup は関数であり、Σを押さないと指定できません。次のとおり、通常の用途では rollup 関数をモニターのクエリに指定することはないので、ここでは説明を割愛します。
Rollups should usually be avoided in monitor queries, because of the possibility of misalignment between the rollup interval and the evaluation window of the monitor.
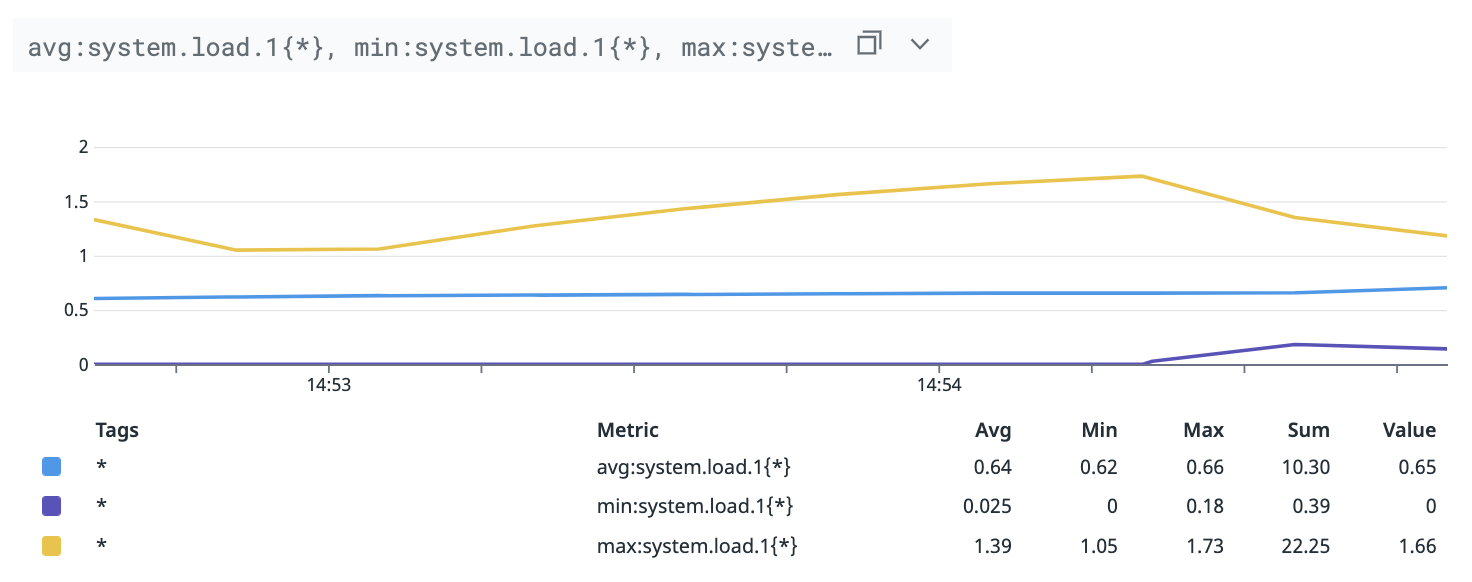
各項目の詳細はドキュメントを読んでもらうとして、理解を深めてもらうために具体例を出します。例えば次のクエリを考えます。
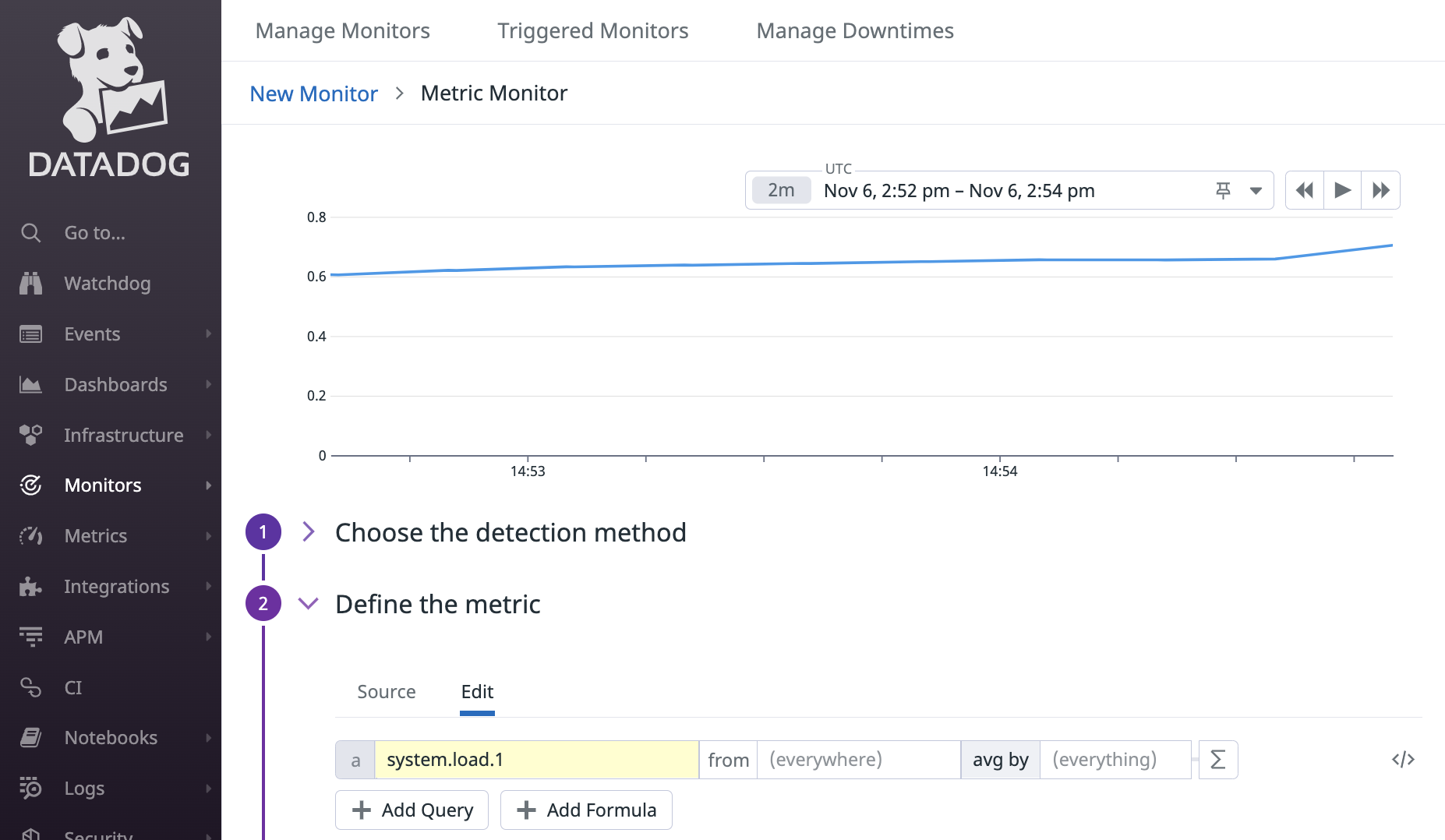
式で表現すると avg:system.load.1{*} です。
system.load.1 の部分はメトリクス名で、過去 1 分間のロードアベレージです。uptime で確認できるやつですね。
[ec2-user@ip-172-31-4-62 ~]$ uptime
15:53:16 up 1:15, 1 user, load average: 1.27, 0.54, 0.42
上記の出力結果だと過去 1 分間のロードアベレージは 1.27 で、過去 5 分が 0.54、過去 15 分が 0.42 です。
* の部分はスコープ(フィルター条件)で、* は全てのメトリクスを対象にすることを意味します。例えば本番で稼働しているサーバのメトリクスに env:production というタグが付与されている場合、env:production を指定することで本番のメトリクスに限定することができます。複雑なスコープの指定方法については Advanced Filtering を一読すると良いでしょう。分量も少ないのでサクッと読めるはずです。
avg の部分は同時刻のメトリクスをどのように集約するかを意味し、他に min, max, sum があります。
例えば、3 つのホストがあり、それぞれのメトリクスの値が次のようになっていたとします。
| datetime | i-0ba82eddc862f3795 | i-0da62b250aad43710 | i-0f05b9b48bcbba766 |
|---|---|---|---|
| 2022-11-06T14:52:36Z | 0.000 | 1.350 | 0.463 |
| 2022-11-06T14:52:50Z | 0.000 | 1.070 | 0.790 |
| 2022-11-06T14:52:51Z | 0.000 | 1.050 | 0.808 |
| 2022-11-06T14:53:05Z | 0.000 | 0.835 | 1.060 |
| 2022-11-06T14:53:06Z | 0.000 | 0.820 | 1.074 |
| 2022-11-06T14:53:20Z | 0.000 | 0.643 | 1.270 |
| 2022-11-06T14:53:21Z | 0.000 | 0.630 | 1.281 |
| 2022-11-06T14:53:35Z | 0.000 | 0.499 | 1.430 |
| 2022-11-06T14:53:36Z | 0.000 | 0.490 | 1.439 |
| 2022-11-06T14:53:50Z | 0.000 | 0.387 | 1.560 |
| 2022-11-06T14:53:51Z | 0.000 | 0.380 | 1.567 |
| 2022-11-06T14:54:05Z | 0.000 | 0.305 | 1.660 |
| 2022-11-06T14:54:06Z | 0.000 | 0.300 | 1.665 |
| 2022-11-06T14:54:20Z | 0.000 | 0.235 | 1.730 |
| 2022-11-06T14:54:21Z | 0.029 | 0.230 | 1.705 |
| 2022-11-06T14:54:35Z | 0.440 | 0.183 | 1.350 |
| 2022-11-06T14:54:36Z | 0.463 | 0.180 | 1.339 |
| 2022-11-06T14:54:50Z | 0.790 | 0.143 | 1.180 |
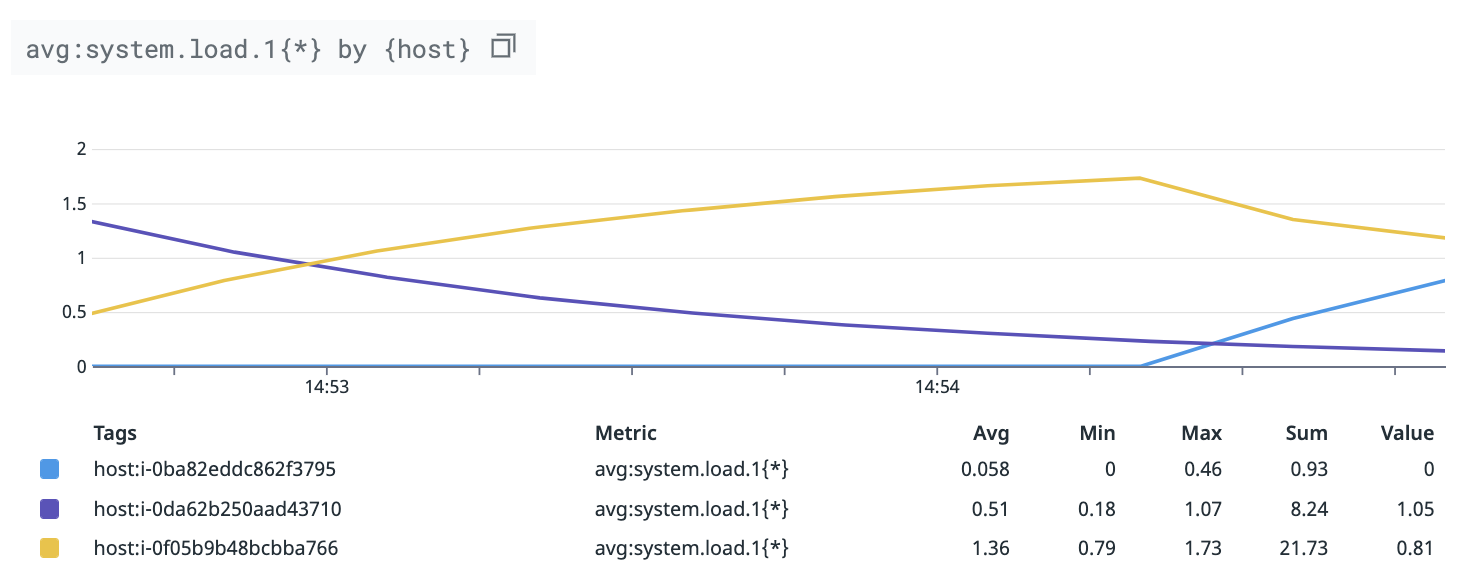
min:system.load.1{*}, avg:system.load.1{*}, max:system.load.1{*} は、これら 3 ホストのメトリクスの最小値、平均値、最大値を取って次のようになります。
| datetime | min | avg | max |
|---|---|---|---|
| 2022-11-06T14:52:36Z | 0.000 | 0.604 | 1.350 |
| 2022-11-06T14:52:50Z | 0.000 | 0.620 | 1.070 |
| 2022-11-06T14:52:51Z | 0.000 | 0.619 | 1.050 |
| 2022-11-06T14:53:05Z | 0.000 | 0.632 | 1.060 |
| 2022-11-06T14:53:06Z | 0.000 | 0.631 | 1.074 |
| 2022-11-06T14:53:20Z | 0.000 | 0.638 | 1.270 |
| 2022-11-06T14:53:21Z | 0.000 | 0.637 | 1.281 |
| 2022-11-06T14:53:35Z | 0.000 | 0.643 | 1.430 |
| 2022-11-06T14:53:36Z | 0.000 | 0.643 | 1.439 |
| 2022-11-06T14:53:50Z | 0.000 | 0.649 | 1.560 |
| 2022-11-06T14:53:51Z | 0.000 | 0.649 | 1.567 |
| 2022-11-06T14:54:05Z | 0.000 | 0.655 | 1.660 |
| 2022-11-06T14:54:06Z | 0.000 | 0.655 | 1.665 |
| 2022-11-06T14:54:20Z | 0.000 | 0.655 | 1.730 |
| 2022-11-06T14:54:21Z | 0.029 | 0.655 | 1.705 |
| 2022-11-06T14:54:35Z | 0.183 | 0.658 | 1.350 |
| 2022-11-06T14:54:36Z | 0.180 | 0.661 | 1.339 |
| 2022-11-06T14:54:50Z | 0.143 | 0.704 | 1.180 |
次に、grouping by tag が指定されているケースを考えます。ここでは、指定するタグは host とします。
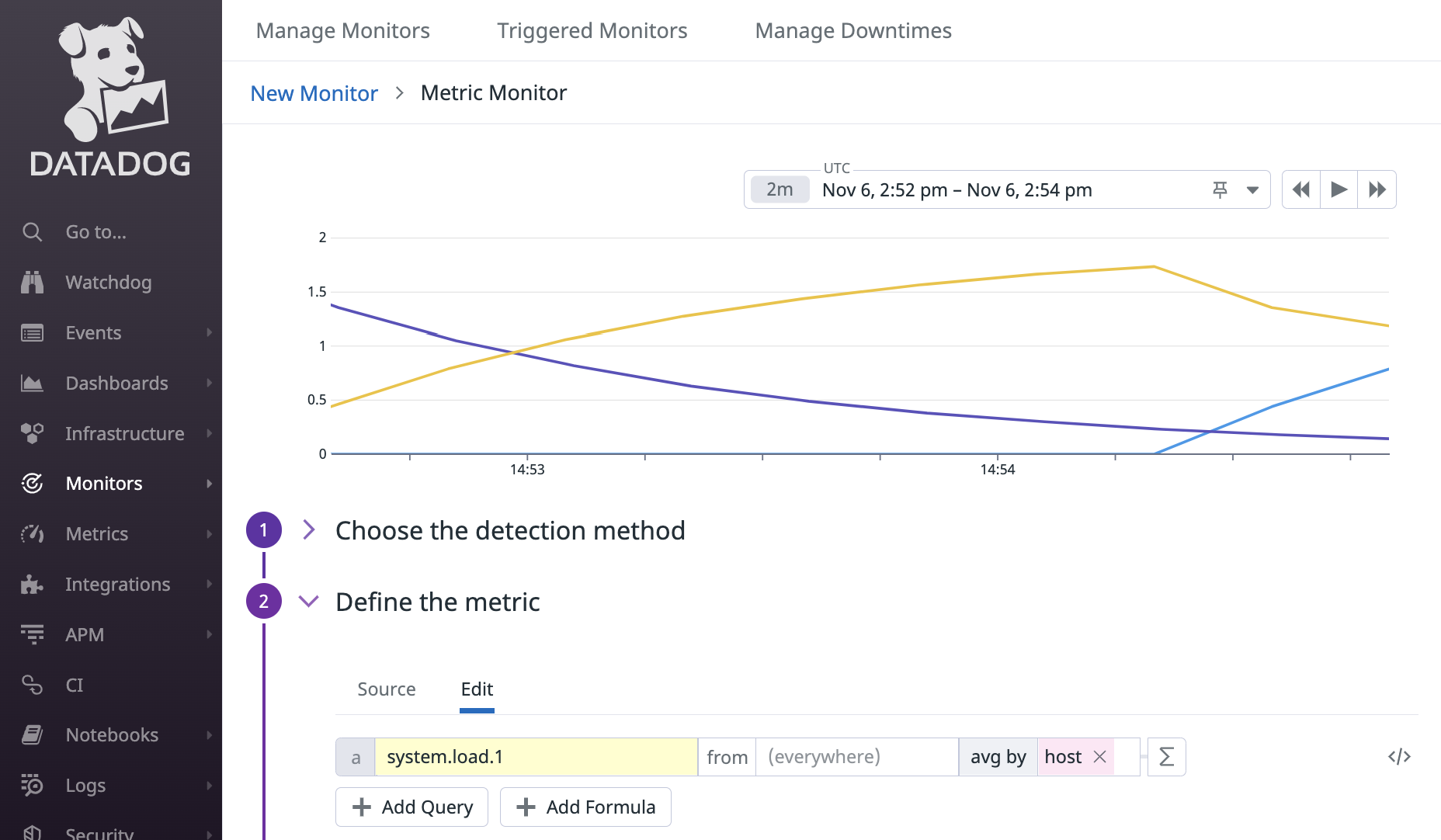
式で表現すると avg:system.load.1{*} by {host} です。
avg は host タグが同じメトリクスごとに適用されます。system.load.1 の場合、ホストごとに同時刻のメトリクスは 1 つしかないので、avg, min, max, sum のいずれを指定しても結果は同じになります。万が一同時刻に同じメトリクスが複数送られてきた場合、後の値が採用されます。同じメトリクスとは、メトリクス名とタグの値が全て同じメトリクスのことです。
Any metrics with fractions of a second timestamps are rounded to the nearest second. If any points have the same timestamp, the latest point overwrites the previous ones.
一方で、avg:system.load.1{*} by {availability-zone} のように grouping by tag が availability-zone で、各 availability zone に複数のホストが存在すれば、同時刻に複数のメトリクスが存在するので、avg, min 等で結果が異なります。また、grouping by tag が host でも、system.core.user のように、同一ホストから同時刻にコアの数だけメトリクスが送られてくる場合も結果が異なります。
なお、モニターを作成する際に grouping by tag を指定すると、そのグループごとにアラートを受け取ることになります。よって、grouping by tag として host を指定した上でシステム全体が高負荷になると、ホストの数だけアラートを受け取ることになります。
クエリの評価期間・評価方法・アラート条件の指定
モニタリングすべきクエリを決めたら、次は評価期間、評価方法、アラートの条件を指定する必要があります。
これらについては、まずは Configure Monitors を一読してください。
以下、ドキュメントの内容に対する補足です。
クエリの結果はどう処理されるのか?
クエリにも avg 等の集約関数が出てきましたが、モニターを作成する際にはクエリの結果の評価方法でも avg などが出てくるのが初心者にとってわかりにくい内容かと思います。
例えば、avg:system.load.1{*} というクエリの結果が 2 分間ずっと 1 を超えていたらアラートを受け取りたいとします。つまり、2 分間の最小値が 1 を超えた場合ですね。
Web UI 上だと次のように指定します。
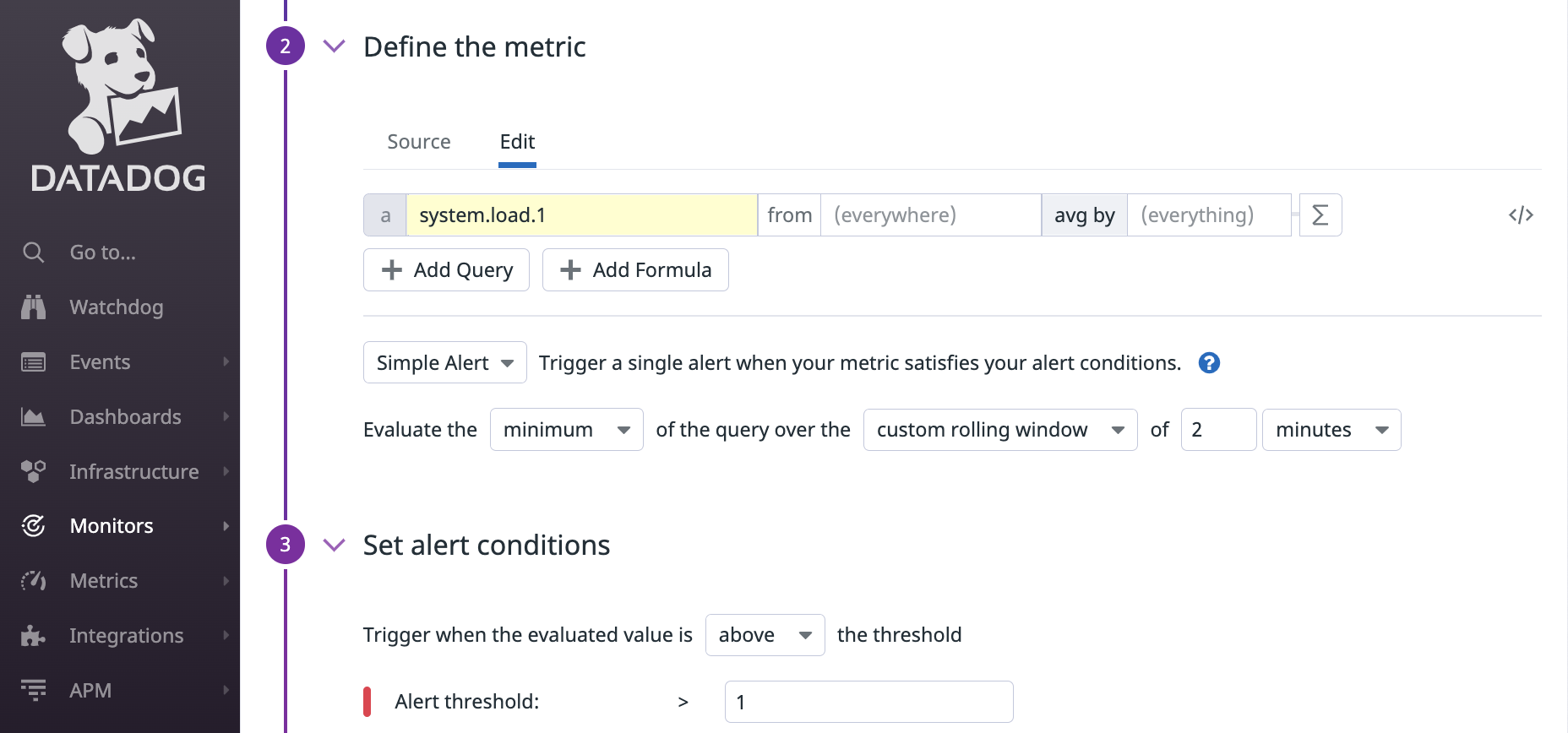
式で表現すると min(last_2m):avg:system.load.1{*} > 1 です。
例えば、3 つのホストが存在し、それぞれのホストのメトリクスが次のようになっていたとします。
| datetime | i-0ba82eddc862f3795 | i-0da62b250aad43710 | i-0f05b9b48bcbba766 |
|---|---|---|---|
| 2022-11-06T14:52:36Z | 0.000 | 1.350 | 0.463 |
| 2022-11-06T14:52:50Z | 0.000 | 1.070 | 0.790 |
| 2022-11-06T14:52:51Z | 0.000 | 1.050 | 0.808 |
| 2022-11-06T14:53:05Z | 0.000 | 0.835 | 1.060 |
| 2022-11-06T14:53:06Z | 0.000 | 0.820 | 1.074 |
| 2022-11-06T14:53:20Z | 0.000 | 0.643 | 1.270 |
| 2022-11-06T14:53:21Z | 0.000 | 0.630 | 1.281 |
| 2022-11-06T14:53:35Z | 0.000 | 0.499 | 1.430 |
| 2022-11-06T14:53:36Z | 0.000 | 0.490 | 1.439 |
| 2022-11-06T14:53:50Z | 0.000 | 0.387 | 1.560 |
| 2022-11-06T14:53:51Z | 0.000 | 0.380 | 1.567 |
| 2022-11-06T14:54:05Z | 0.000 | 0.305 | 1.660 |
| 2022-11-06T14:54:06Z | 0.000 | 0.300 | 1.665 |
| 2022-11-06T14:54:20Z | 0.000 | 0.235 | 1.730 |
| 2022-11-06T14:54:21Z | 0.029 | 0.230 | 1.705 |
| 2022-11-06T14:54:35Z | 0.440 | 0.183 | 1.350 |
| 2022-11-06T14:54:36Z | 0.463 | 0.180 | 1.339 |
| 2022-11-06T14:54:50Z | 0.790 | 0.143 | 1.180 |
すると、クエリの結果(平均値)は次のとおりです。
| datetime | avg |
|---|---|
| 2022-11-06T14:52:36Z | 0.604 |
| 2022-11-06T14:52:50Z | 0.620 |
| 2022-11-06T14:52:51Z | 0.619 |
| 2022-11-06T14:53:05Z | 0.632 |
| 2022-11-06T14:53:06Z | 0.631 |
| 2022-11-06T14:53:20Z | 0.638 |
| 2022-11-06T14:53:21Z | 0.637 |
| 2022-11-06T14:53:35Z | 0.643 |
| 2022-11-06T14:53:36Z | 0.643 |
| 2022-11-06T14:53:50Z | 0.649 |
| 2022-11-06T14:53:51Z | 0.649 |
| 2022-11-06T14:54:05Z | 0.655 |
| 2022-11-06T14:54:06Z | 0.655 |
| 2022-11-06T14:54:20Z | 0.655 |
| 2022-11-06T14:54:21Z | 0.655 |
| 2022-11-06T14:54:35Z | 0.658 |
| 2022-11-06T14:54:36Z | 0.661 |
| 2022-11-06T14:54:50Z | 0.704 |
そして、このクエリの結果の 2 分間の最小値は 0.604 です。これが 1 分ごとに評価されて、その時に 2 を超えていたらアラートを受け取ることになります。あくまで、先にクエリの結果を計算することに注意してください。
1 分ごとに評価されるという話については Evaluation frequency を参照してください。
Notify No Data
Configure Monitors - NO DATA でも言及されているように、notify no data を有効にすることで、モニタリング対象のメトリクスが届かなくなった時にアラートを受け取ることができるので、メトリクスを収集する仕組みが動いてなくて監視できていなかったといった事態を防ぐことができます。grouping by tag を指定している場合はグループごとに no data アラートを受け取ることができます。
どれだけの期間メトリクスが届かなかったらアラートを受け取るようにするかの期間は no_data_timeframe と呼ばれ、評価期間の 2 倍以上を指定することが推奨されています。
次の内容はドキュメントからの引用です。
Note: It is recommended that you set the missing data window to at least two times the evaluation period.
これに従うと評価期間が 1 時間の場合は no_data_timeframe に 2 時間を指定することになるわけですが、流石に長過ぎると思い、2020 年 9 月に問い合わせたところ、次のような回答をもらいました。2 倍を推奨しているのは誤検知防止のためで、評価期間が長い場合は必ずしも 2 倍じゃなくて良さそうです。
It is a general rule of thumb, especially with shorter evaluation windows, as a way to account for any delays or latencies that may not actually mean data is truly missing.
For instance, if you are using a 1 minute evaluation it’s better to have a 2 minute no data window. If you have an hour eval window, having a no data window of 1.5 hours is probably enough
What we really don’t want is to see customers set the same No Data period as the Evaluation Window. This will definitely lead to unwanted behaviour.
なお、no_data_timeframe は大きすぎる値もダメです。次の内容はドキュメントからの引用です。
This option does not work if it is enabled at a time when data has not been reporting for a long period.
Web UI 上では 1440 分より大きな値を指定すると warning が出ます。無視して作成することはできますが…。

1440 分より大きな値を指定した場合の挙動については不明ですが、今の挙動が将来も保証されるとは限らないので 1440 分以下にした方が良いでしょう。
なお、Datadog の AWS 連携には EC2 automuting という機能があり、これを有効にすることで、EC2 インスタンスが terminate する時にそのホストに関するモニターを自動で mute することができます。つまり、auto-scaling するようなクラスタのサーバのメトリクスモニターに対して notify no data を有効にしても、terminate したインスタンスから no data アラートを受け取らずに済むということですね。
もし grouping by tag にホストごとに値が異なるようなタグ(e.g. IP アドレス)を指定した場合、通常であればインスタンスが terminate した後に no data アラートを受け取ることになります。このような場合、冗長ではありますが、grouping by tag に host タグも追加すれば EC2 automuting が効いてアラートを受け取らずに済みます。
ただ、EC2 automuting は時々 mute されるまでに数十分かかることがあったりと、それなりに誤検知があるので、個人的には Event Bridge と Lambda でインスタンスが terminate した時に自前で mute するのが良いと思います。
なお、EC2 automuting があるなら container automuting もあることを期待するかもしれませんが、2018 年 8 月に問い合わせた時点では存在しませんでした。問い合わせた当時は backlog にはあると回答がありましたが、今も存在しない気がします。
The feature you’ve described is currently one that we have in our backlog. I don’t know if it’s scheduled for delivery short-term however, I will follow-up after reviewing with product management.
アラートのメッセージの設定
アラートのメッセージや通知先の設定方法については Notifications のうち、Title、Message、Notifications は最低限読むべき内容です。メッセージの内容に変数を埋め込みたい場合や、alert、warn、no data 等モニターの状態の変化に応じてメッセージの内容や通知先を変えたい場合は Variables も読むと良いでしょう。
Web UI 上だと補完が効くので、慣れるまでは Web UI を使うことを推奨します。
ここではよく連携されているであろう Slack と PagerDuty について注意点を補足します。
Slack
Slack では @slack-<channel-name> をメッセージに含めることで、指定した Slack チャンネルにメッセージを流すことができますが、Slack 連携でチャンネルを追加しない限り通知されません。既存のモニターの設定をコピペして雰囲気で修正するとハマるので注意してください。
次の例では Slack 連携として notification チャンネルしか追加されていないので、他のチャンネルの名前を指定すると warning が表示されています。
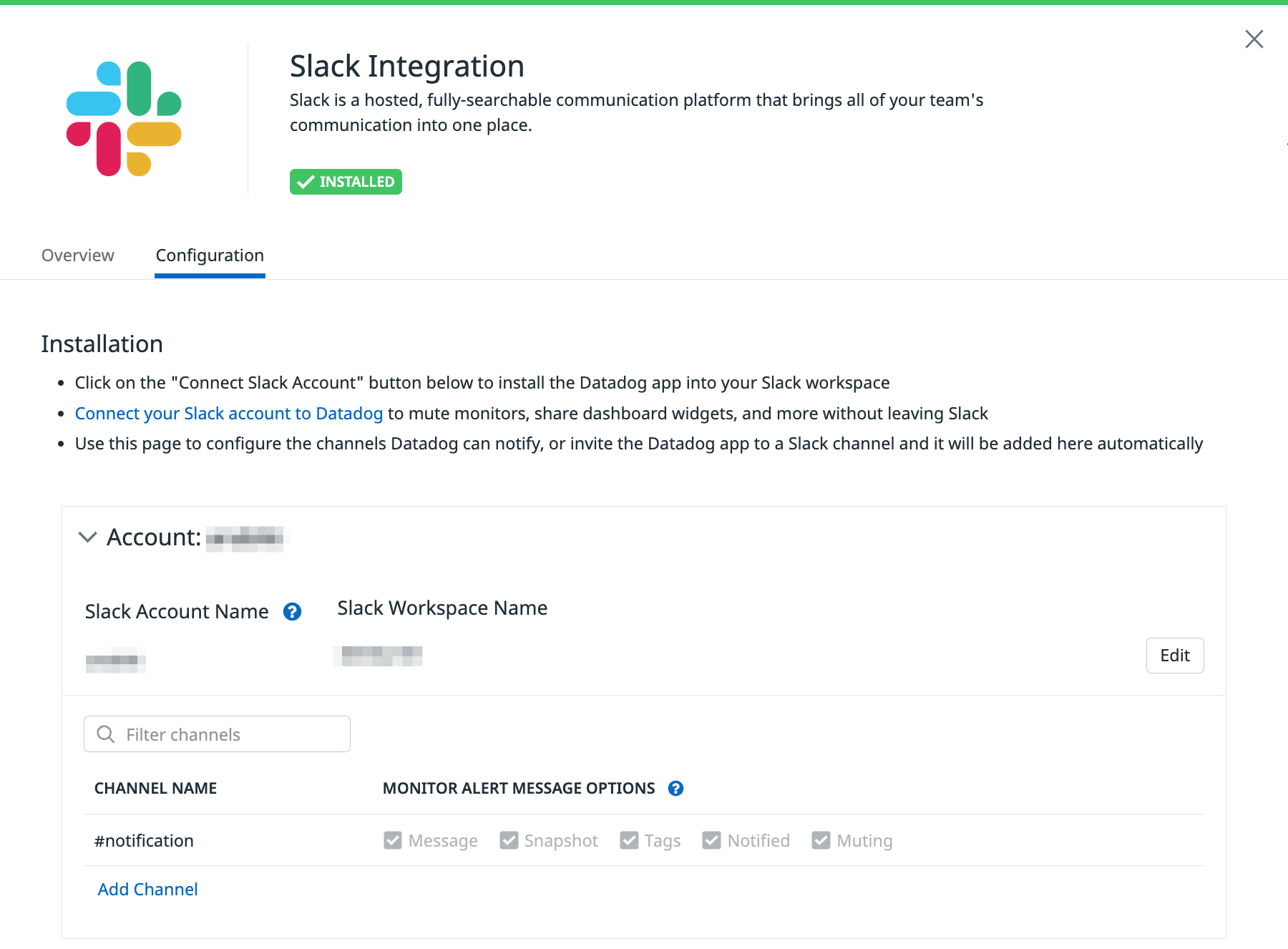
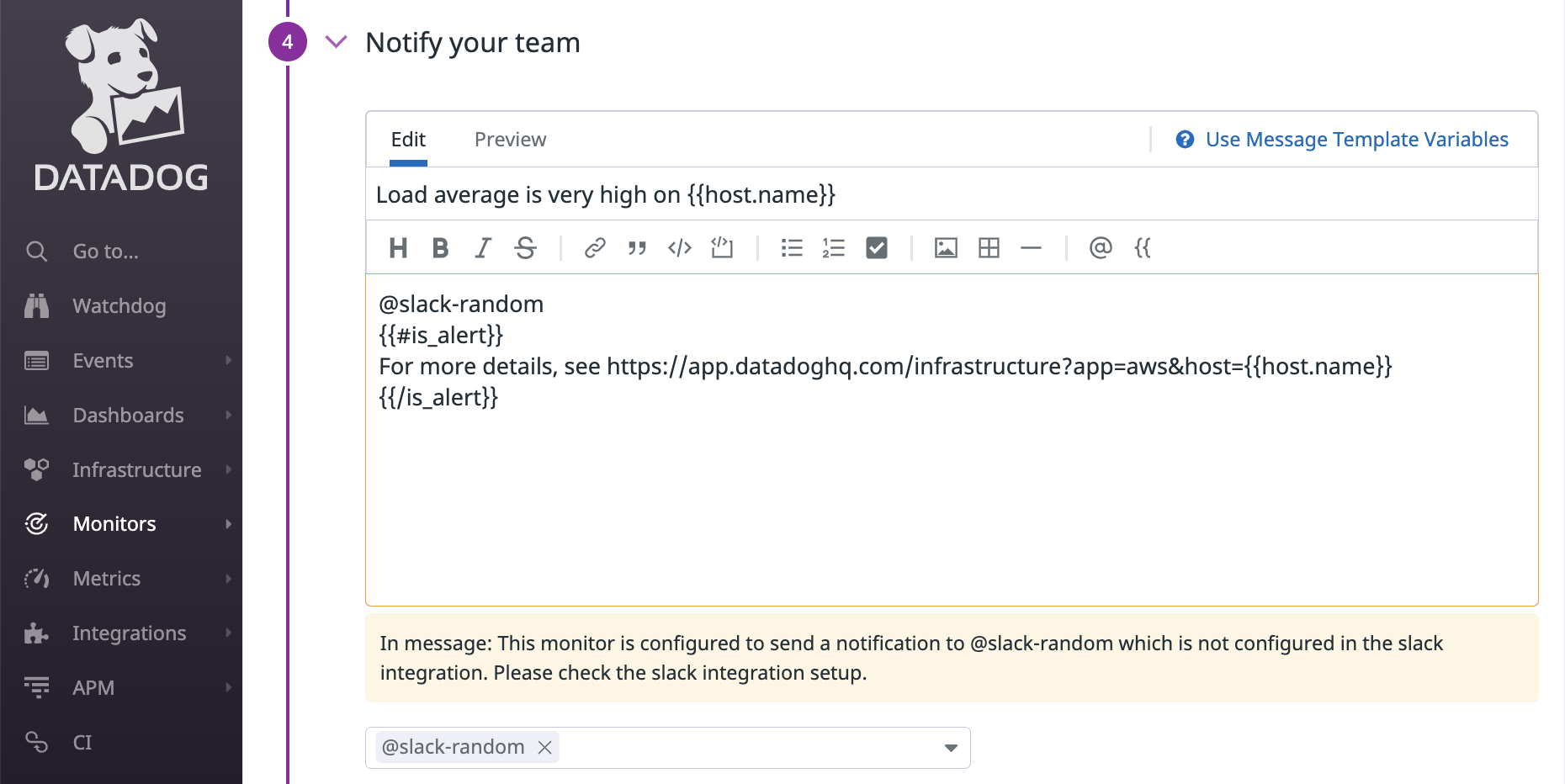
こういったミスに気付けるのも Web UI の良いところです。
なお、追加されているチャンネルであれば、次のように variable が展開された内容を受け取ることができます。
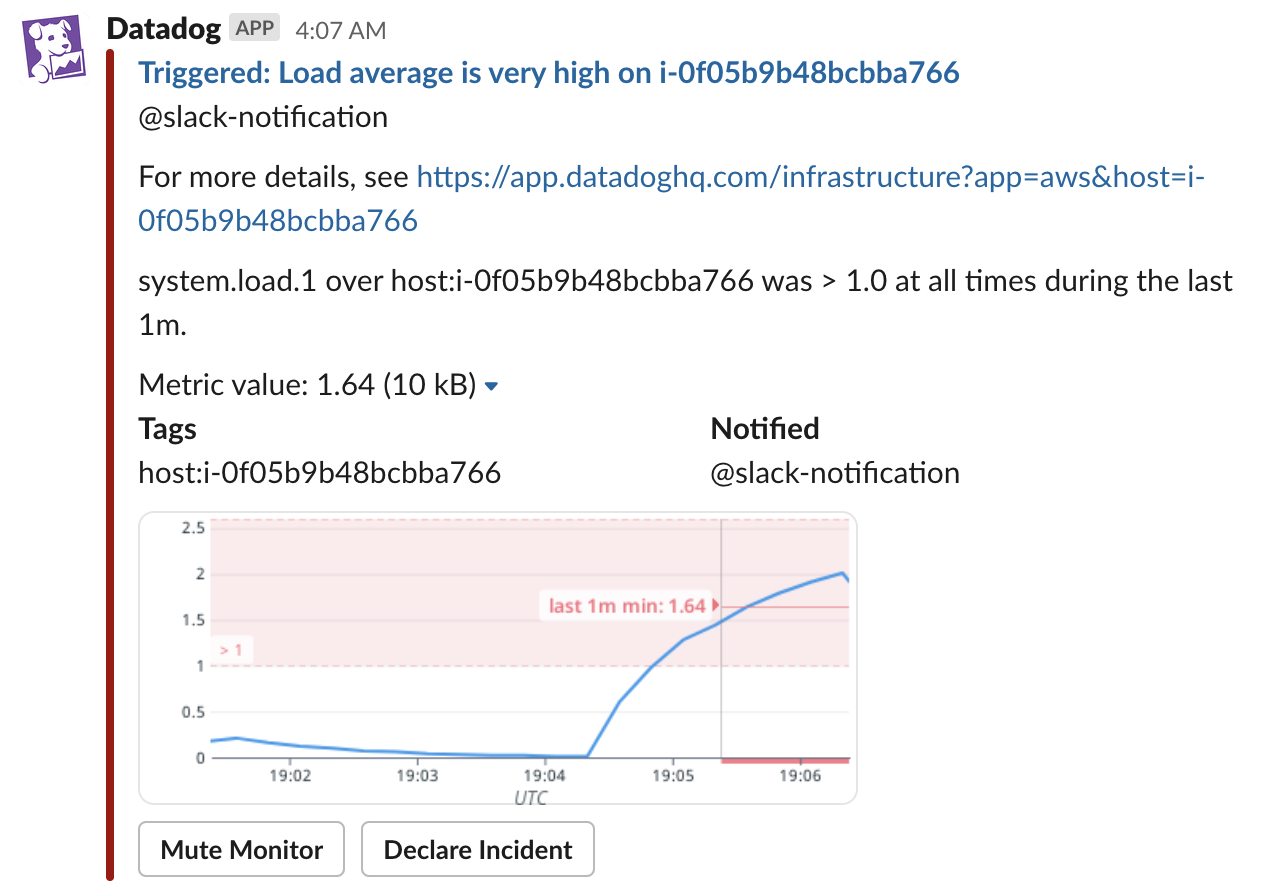
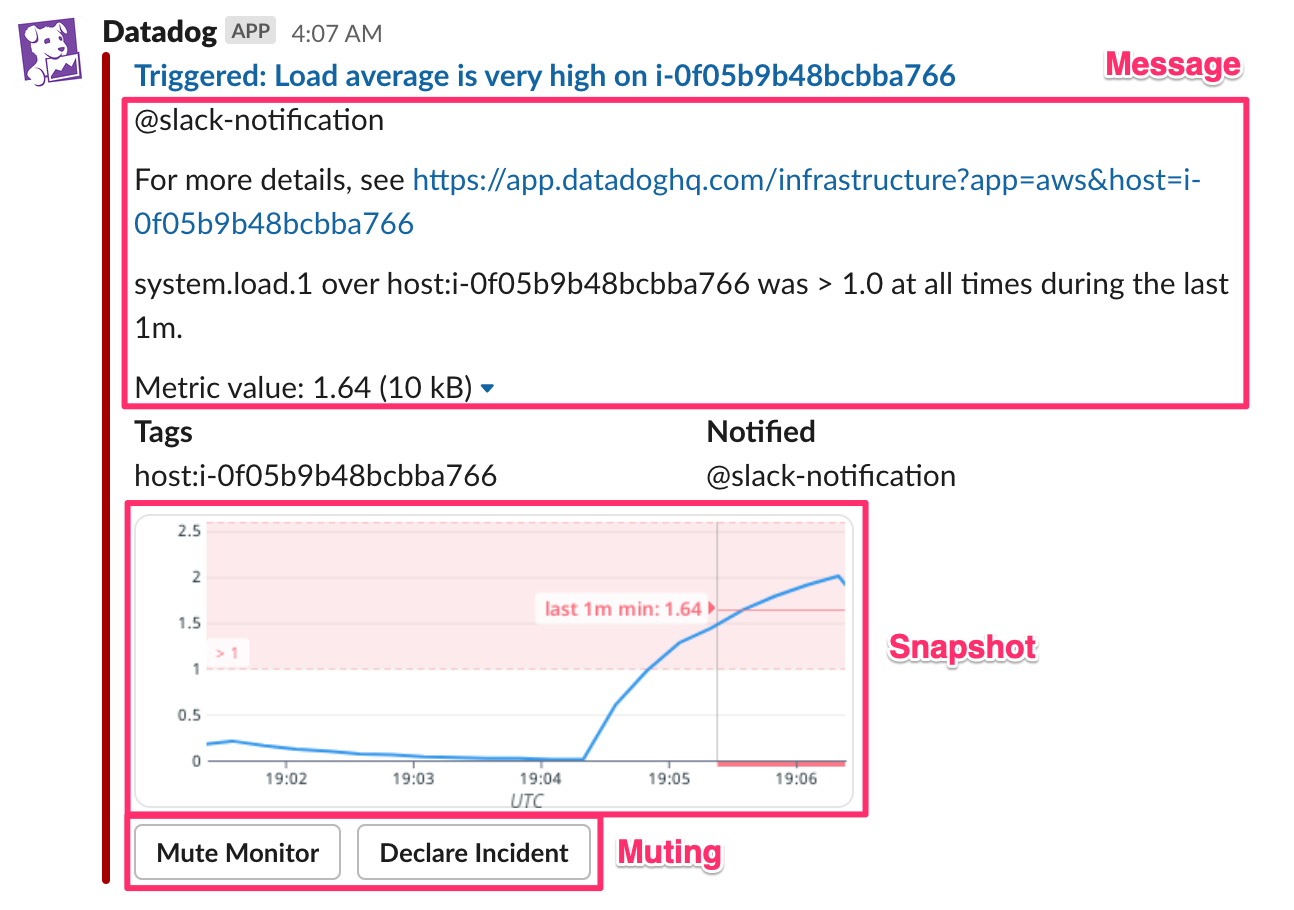
Slack 連携のページでは、メッセージに含まれる内容をチャンネルごとに選択できます。Message、Snapshot、Tags、Notified、Muting のうち、Tags、Notified は一目瞭然だと思うので、残りの項目がどの内容に対応するかを下図に示します。
PagerDuty
PagerDuty も PagerDuty 連携 で service を追加しないといけません。
service を追加すると、@pagerduty-<service-name> に通知することで incident が作成され、@pagerduty-resolve に通知することで incident が resolve されます。
よって、メッセージの基本形は次のようになるでしょう。
{{#is_alert}} @pagerduty-<service-name> {{/is_alert}}
{{#is_recovery}} @pagerduty-resolve {{/is_recovery}}
incident を作成する際にはサービスごとに通知先を変える必要がありますが、resolve する際には @pagerduty-resolve だけで大丈夫なことに注意してください。
ただし、次のように alert と warn で別々の incident が作成されるようにした場合、@pagerduty-resolve で resolve されるのは最後に作成された incident だけで、最初に作成された incident は resolve されません。
{{#is_alert}} @pagerduty-<service-name> {{/is_alert}}
{{#is_warn}} @pagerduty-<another-service-name> {{/is_warn}}
{{#is_recovery}} @pagerduty-resolve {{/is_recovery}}
Terraform で Datadog モニターを管理する際の注意点
Terraform で Datadog のモニターを管理する場合は datadog_monitor resource を使います。
Web UI による補助がなかったり、terraform-provider-datadog 特有の設定があったりするので、次のことに注意してください。
no_data_timeframeのデフォルトが評価期間に関係なく 10 で固定になる- Web UI や API では評価期間の 2 倍 (cf. Monitor API Options)
no_data_timeframeに 1440 より大きな値を指定してもモニターを作成できてしまう- Web UI からも 1440 より大きな値でモニターを作成できるが、warning が表示されるので気付くことができる
require_full_windowのデフォルト値が true- cf. datadog/resource_datadog_monitor.go#L263-L268
- フィールドの description には評価方法によってデフォルト値が代わるようなことが書いてあるが、無条件でデフォルト true であることに注意
- Web UI や API では false (cf. Monitor API Options)
- full window の概念については Data Window 参照
- cf. datadog/resource_datadog_monitor.go#L263-L268
- Slack 等のメンションで存在しないメンションを指定できてしまう
- 指定したメンションが本当に存在するか確認すべき
- クエリの閾値と
monitor_thresholdsのcriticalは同じ値にしなければならないmonitor_thresholds.criticalだけ変更してクエリの修正を忘れがち
- datadog_downtime resource で recurrence を指定すると、繰り返す度に新しい ID の downtime が作成されるので terraform でまともに管理できない
知っておくと良いかもしれない豆知識
最後に、自分が今までにモニターを作成する際に役に立った知識やハマった内容などを共有します。
メトリクスの定義の調べ方
メトリクスの意味について知りたい場合、まずは Datadog のドキュメントを参照すると思うんですが、メトリクスの定義を読んでもよく理解できないことがあると思います。そんな時は次のリポジトリを覗いてみると良いです。
例えば、MySQL integration を有効にすると Data Collected に載っているようなメトリクスが収集されるわけですが、InnoDB 関係のメトリクスは innodb_metrics.py で取得していることが雰囲気でわかると思います。
ところで、会社名やサービス名は Datadog なのにリポジトリの organization が DataDog なのは紛らわしいですね…
クエリの結果はメトリクスが届かなくなった場合に 5 分間最後の値が外挿される
Datadog はデータが届かなくても、デフォルトで 5 分間最後の値を外挿します。
cf. Interpolation and the Fill Modifier
例えば、高負荷な状態で EC2 インスタンスが terminate すると、高負荷な状態が 5 分間続いているように見えるわけです。これが原因で、terminate した後のインスタンスのアラートを受け取ってしまうかもしれません。
これを避けるには fill(null) を指定したり、fill(last, 60) 等、デフォルトの 5 分より短い間補完するようにしたりすると良いでしょう。
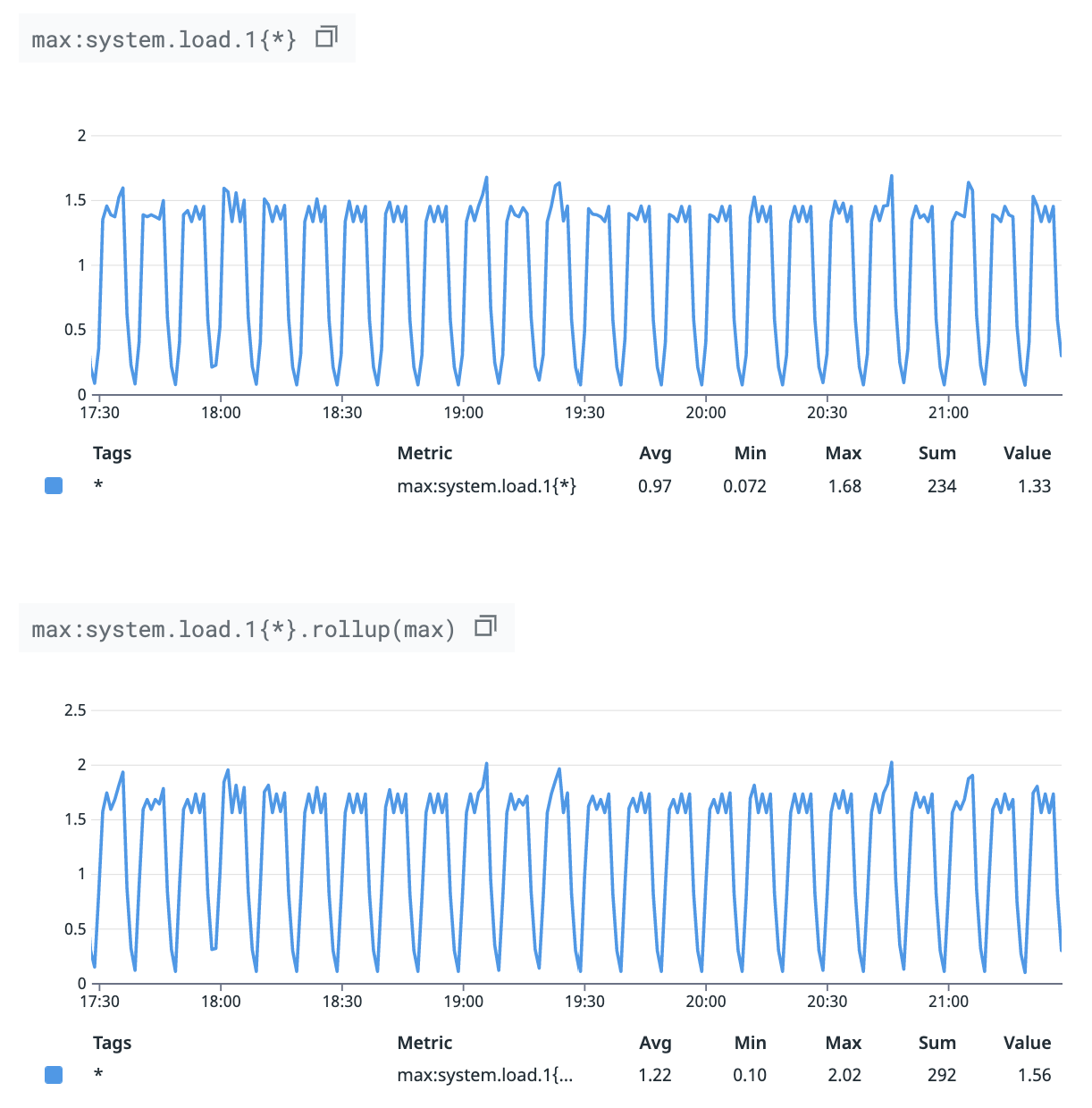
Datadog のグラフはデフォルトで平均値が表示される
例えば system.load.1 のモニターの閾値を決めるために、直近 1 週間の最大値を確認するとします。その場合、まずは notebook 等で max:system.load.1{*} のグラフを作成して、直近 1 週間のグラフを確認するかもしれませんが、それでは最大値を確認することはできません。Datadog は長期間のメトリクスを表示する際にデータポイントを間引くからです。その際にデフォルトで平均値が使われます。
When graphing, Datadog imposes a limit on the number of points per graph. To respect this limit, Datadog rolls up data points automatically with the avg method, effectively displaying the average of all data points within a time interval for a given metric.
cf. Rollup interval: enforced vs custom
もし最大値を確認したいなら max:system.load.1{*}.rollup(max) とする必要があります。
次のグラフは上が max:system.load.1{*} で、下が max:system.load.1{*}.rollup(max) で、グラフの形はほぼ同じですが、上記の理由から縦軸が異なります。
CloudWatch から取得しているメトリクスの評価期間の推奨値は 1 時間以上
Datadog では AWS の連携を有効にすると、CloudWatch のメトリクスを取り込むことができます。このメトリクスに対して 1 時間未満の評価期間を指定すると次のような warning が出ます。
Note: The selected metric provides data at low frequencies. We strongly recommend alerting on at least a 1 hour time frame.

CloudWatch のメトリクス自体は解像度が 1 分なので疑問に思い問い合わせたところ、これは Datadog が CloudWatch のメトリクスを 10 分間隔で取得していることから、そのタイムラグを考慮しての推奨値みたいです。2018 年 7 月に問い合わせた時の回答は次のとおり。
This is related to the delay from the AWS integration.
If you receive 5-minute metrics from CloudWatch, there can be up to ~15-20 min delay in receiving your metrics. This is because CloudWatch makes your data available with a 5-10 minute latency, and we run the crawler every 10 minutes. More information related to this can also be found here https://docs.datadoghq.com/integrations/faq/are-my-aws-cloudwatch-metrics-delayed/
評価期間を 1 時間にすることが許容できない場合は、誤検知を覚悟の上で評価期間を短くするか、AWS CloudWatch Metric Streams with Kinesis Data Firehose を検討すると良いかもしれません(未検証)。
なお、クローリング間隔はサポートにお願いすれば短くしてもらえるかもしれません。短くすることで CloudWatch のコストはかかるようになりますが。
モニターで使われているクエリの結果と評価値がずれることがある
モニターには History という項目と、EVALUATION GRAPGH という項目がありますが、History がクエリの結果で、枠で囲まれた範囲の評価値が EVALUATION GRAPGH に表示されています。
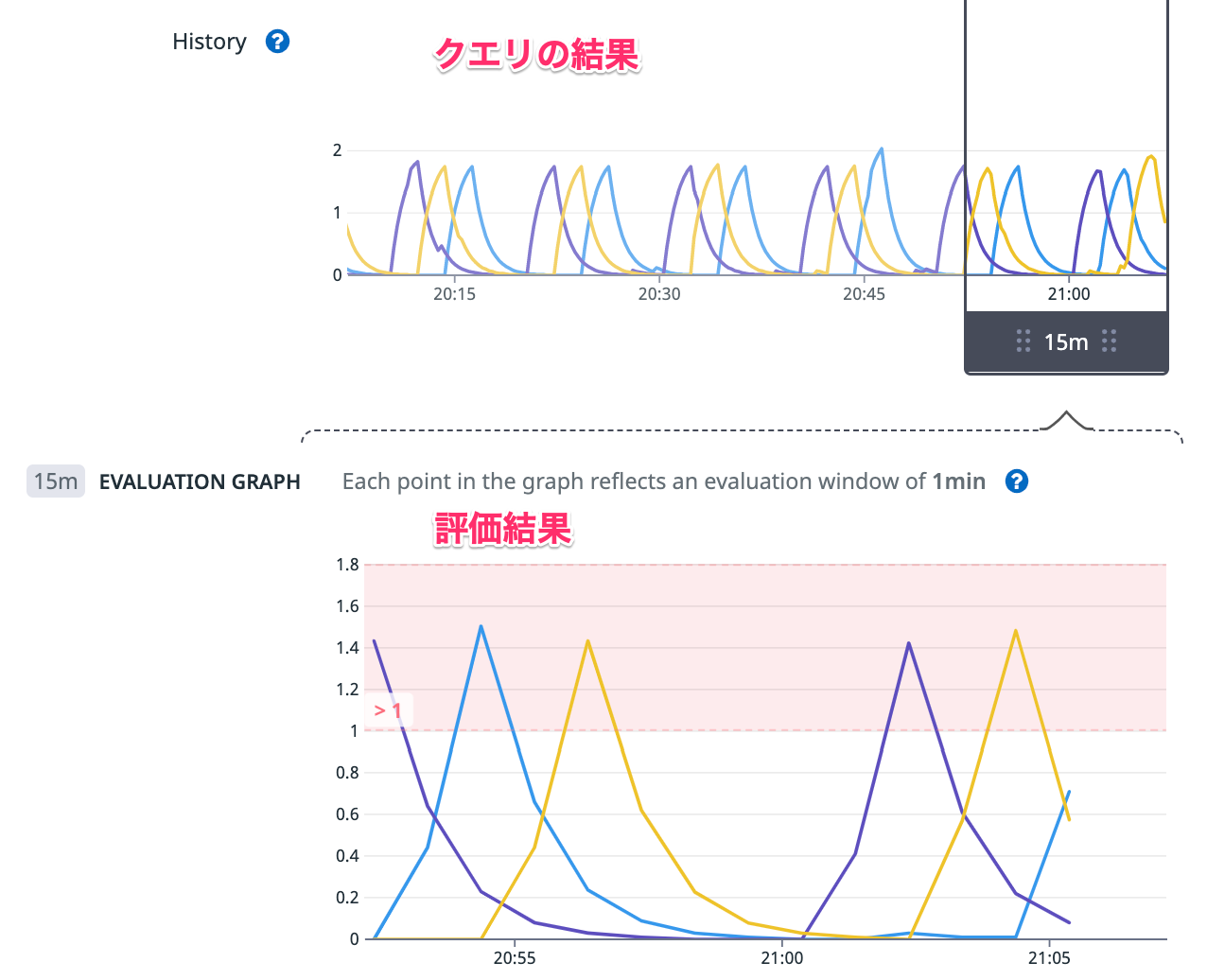
つまり、評価値がアラートの条件に引っかかった場合に、History の内容から原因を調査できるんですが、過去に、History の内容的にあり得ない EVALUATION GRAPGH になることがありました。サポートに問い合わせたところ、このクエリは 4 つのクエリの結果を組み合わせたものであったこともあり、クエリの結果が出揃う前に評価してしまうことがあったようです。この時はサポートのアドバイスに従って、Evaluation options でモニターの評価を遅らせたことで意図した結果が得られるようになりました。
質問内容
I have a monitor to detect the increase of a certain ratio.
It monitors “min(last_10m): ( the current ratio / the ratio 1 hour before )”.
Its historical values displayed in the graph are usually less than 2.0, but the evaluated value, in other words, the minimum value for 10 minutes, is sometimes greater than 4.0.Why do evaluated values significantly differ from historical values?
回答
Thanks for your patience on this! After digging into the issue you’re experiencing and running some commands in our backend, I believe these random spikes that are happening are due to the size of the query. The full query has four sets of metrics and a formula which can take an extra bit of time to fully query and compute this request and then have the monitor evaluate.
To avoid these unintended spikes, I suggest delaying the evaluation by 30-60 seconds to provide adequate time for the data to be computed before the evaluation happens.
Docker コンテナの CPU 使用率のモニタリングは難しい
ECS などを利用している場合、タスクやコンテナの負荷を見るのに docker.cpu.usage を使っている方もいるでしょう。このメトリクスが少しわかりにくいので補足します。
注意点は次の 2 点です。
docker.cpu.usageの最大値はコア数 x 100system.cpu.userはコア数が何個でも最大値は 100 だが、docker.cpu.usageはコア数によって変わることに注意
- ECS タスク等で各コンテナへの CPU の割当が少なかったとしても、最大値は コア数 x 100 になり得る
- ECS の task definition の cpu は docker コマンドの
--cpu-sharesに相当し、cgroup の cpu.shares に相当するので、CPU が空いていれば無制限に使用する
- ECS の task definition の cpu は docker コマンドの
例えば、ある ECS タスクに A, B, C の 3 つのコンテナが存在し、それぞれ CPU の割当が 1024、512、512 だったとします。この ECS タスクが 2 コアの ECS インスタンスで動いていて、コンテナ A がマルチスレッドで動くことができる場合、docker.cpu.usage は 100 を超えて 200 になる可能性があります。仮にコンテナ A、B、C の docker.cpu.usage がそれぞれ 150、0、0 だった場合、コンテナインスタンスの CPU 使用率は 75% です。一方で、全コンテナが全力で CPU を使うと、コンテナインスタンスの CPU 使用率は 100% になり、cpu.shares が効いてくるので、A、B、C の docker.cpu.usage はそれぞれ 100、50、50 になります。
コンテナ A だけの docker.cpu.usage に着目した場合、150 の時の方が高負荷に見えますが、ECS タスク全体として見た場合、実は 100 の時の方が高負荷なわけです。
じゃあ、sum:docker.cpu.usage{*} by {host,task_name} をモニタリングすれば良いと思うかもしれませんが、これも複数のタスクが同じコンテナインスタンスに同居する場合に上手く行きません。
また、Docker のメトリクスにはロードアベレージに相当するものがないので、docker.cpu.usage が高いのは 1 プロセスが CPU を専有しているのか、run queue が詰まっているのか判断が付きません。
というわけで、個人的に負荷をモニタリングしたいのであれば、100 - system.cpu.idle や system.load.norm.1 をモニタリングしつつ、問題が起きた時の調査に docker.cpu.usage を使うだけにとどめて、docker.cpu.usage をメトリクスモニターに使うのはやめた方が良いんじゃないかと思います。
おまけ 〜定期的に負荷のかかるサーバのメトリクスを収集する〜
今回例に出したメトリクスの値は、次の tf ファイルでリソースを作成することで収集しました。3 つの EC2 インスタンスを起動し、Datadog agent をインストールし、maintenance window で 10 分に 1 回順番に 2 分間 stress コマンドで負荷をかけています。
provider "aws" {
region = "ap-northeast-1"
}
variable "datadog_api_key" {}
variable "key_name" {}
variable "security_group_id" {}
resource "aws_iam_role" "StressTest" {
name = "StressTest"
assume_role_policy = <<-EOF
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Principal": {
"Service": [
"ec2.amazonaws.com"
]
},
"Action":"sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_role_policy" "datadog" {
name = "Datadog"
role = aws_iam_role.StressTest.id
policy = <<-EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances",
"ec2:DescribeSecurityGroups",
"ec2:DescribeTags"
],
"Resource": "*"
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "AmazonSSMManagedInstanceCore" {
role = aws_iam_role.StressTest.id
policy_arn = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}
resource "aws_iam_instance_profile" "StressTest" {
name = "StressTest"
role = aws_iam_role.StressTest.id
}
data "aws_ami" "amazon_linux_2" {
most_recent = true
filter {
name = "name"
values = ["amzn2-ami-kernel-5.10-hvm-2.0.*-x86_64-gp2"]
}
owners = ["amazon"]
}
resource "aws_launch_template" "stress" {
image_id = data.aws_ami.amazon_linux_2.id
instance_type = "t3.micro"
iam_instance_profile {
name = aws_iam_instance_profile.StressTest.id
}
key_name = var.key_name
vpc_security_group_ids = [var.security_group_id]
instance_market_options {
market_type = "spot"
}
user_data = base64encode(<<-EOF
#!/bin/bash
DD_AGENT_MAJOR_VERSION=7 DD_API_KEY=${var.datadog_api_key} DD_SITE="datadoghq.com" bash -c "$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script.sh)"
sed -i 's/^# collect_ec2_tags: false/collect_ec2_tags: true/' datadog.yaml
systemctl restart datadog-agent
yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
yum install -y stress
EOF
)
}
data "aws_subnet" "subnet_1a" {
filter {
name = "default-for-az"
values = ["true"]
}
filter {
name = "availability-zone"
values = ["ap-northeast-1a"]
}
}
data "aws_subnet" "subnet_1c" {
filter {
name = "default-for-az"
values = ["true"]
}
filter {
name = "availability-zone"
values = ["ap-northeast-1c"]
}
}
data "aws_subnet" "subnet_1d" {
filter {
name = "default-for-az"
values = ["true"]
}
filter {
name = "availability-zone"
values = ["ap-northeast-1d"]
}
}
resource "aws_autoscaling_group" "stress" {
name = "stress"
desired_capacity = 3
min_size = 3
max_size = 3
vpc_zone_identifier = [data.aws_subnet.subnet_1a.id, data.aws_subnet.subnet_1c.id, data.aws_subnet.subnet_1d.id]
tag {
key = "MaintenanceTarget"
value = "true"
propagate_at_launch = true
}
launch_template {
id = aws_launch_template.stress.id
version = "$Latest"
}
}
resource "aws_iam_role" "AmazonSSMMaintenanceWindowRole" {
name = "AmazonSSMMaintenanceWindowRole"
assume_role_policy = <<-EOF
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Principal": {
"Service": [
"ssm.amazonaws.com"
]
},
"Action":"sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "AmazonSSMMaintenanceWindowRole" {
role = aws_iam_role.AmazonSSMMaintenanceWindowRole.id
policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonSSMMaintenanceWindowRole"
}
resource "aws_ssm_maintenance_window" "mw_stress" {
name = "mw-stress"
schedule = "cron(0 */10 * * * ? *)"
schedule_timezone = "Etc/UTC"
duration = 2
cutoff = 1
}
resource "aws_ssm_maintenance_window_task" "mw_stress" {
window_id = aws_ssm_maintenance_window.mw_stress.id
name = "mw_stress"
task_type = "RUN_COMMAND"
task_arn = "AWS-RunShellScript"
priority = 1
service_role_arn = aws_iam_role.AmazonSSMMaintenanceWindowRole.arn
max_concurrency = 1
max_errors = "100%"
targets {
key = "WindowTargetIds"
values = ["${aws_ssm_maintenance_window_target.mw_stress.id}"]
}
task_invocation_parameters {
run_command_parameters {
parameter {
name = "commands"
values = [
"stress -c 2 -t 120"
]
}
}
}
}
resource "aws_ssm_maintenance_window_target" "mw_stress" {
window_id = aws_ssm_maintenance_window.mw_stress.id
resource_type = "INSTANCE"
targets {
key = "tag:MaintenanceTarget"
values = ["true"]
}
}
なお、本文中のテーブルは次のようなスクリプトで生成しています。
# https://docs.datadoghq.com/api/latest/metrics/
require 'datadog_api_client'
%w[DD_API_KEY DD_APP_KEY].each do |env|
ENV.fetch(env) { raise %Q{"#{env} is required} }
end
AGGS = %w[min avg max]
api_instance = DatadogAPIClient::V1::MetricsAPI.new
from = Time.parse('2022-11-06T14:52:36Z').to_i
to = from + 135
AGGS.each do |agg|
resp = api_instance.query_metrics(from, to, "#{agg}:system.load.1{*} by {host}.rollup(max, 20)")
time_to_values = Hash.new { |h, v| h[v] = {} }
resp.series.each do |series|
host = series.scope.split(':').last
series.pointlist.each do |t, v|
time_to_values[t][host] = '%.3f' % v
end
end
puts agg
puts ''
hosts = %w[i-0ba82eddc862f3795 i-0da62b250aad43710 i-0f05b9b48bcbba766]
puts "datetime | #{hosts.join(' | ')}"
puts "--------|--------|--------|--------"
time_to_values.sort_by(&:first).each do |t, values|
puts [Time.at(t / 1_000).utc.iso8601, *values.values_at(*hosts)].join(' | ')
end
puts ''
end
time_to_values = Hash.new { |h, v| h[v] = {} }
AGGS.each do |agg|
resp = api_instance.query_metrics(from, to, "#{agg}:system.load.1{*}.rollup(max, 20)")
resp.series[0].pointlist.each do |t, v|
time_to_values[t][agg] = '%.3f' % v
end
end
puts "datetime | #{AGGS.join(' | ')}"
puts "--------|--------|--------|--------"
time_to_values.sort_by(&:first).each do |t, values|
puts [Time.at(t / 1_000).utc.iso8601, *values.values_at(*AGGS)].join(' | ')
end