1 つの HiveQL でグループごとの集約結果上位のものを抽出する
 (
( )
)
数年前は Pig で鬼畜なことをしていましたが、最近は Hive とかを使うようになって四苦八苦しているところです。
今回は 1 つの HiveQL で key ごとの集約結果上位のものを抽出してみました。
この説明だけだと意味不明だと思うので、例えば、次のようなデータを扱うことにします。
かなりざっくりしたアクセスログみたいなものとしましょう。これに対して、8 月によくアクセスされた上位 2 ページ、9 月によくアクセスされた上位 2 ページ、全体でよくアクセスされた上位 2 ページを出したいとします。
これを 1 つの HiveQL で出します。
month,page
2014-08,a
2014-08,b
2014-08,a
2014-08,a
2014-08,c
2014-08,b
2014-09,c
2014-09,a
2014-09,c
2014-09,b
2014-09,a
2014-09,c
また、Treasure Data で Hive を使うことにします。つまり、Hive 0.10.0 の機能 + Treasure Data の提供している UDF しか使えないという制約が加わります。
Hive でグループごとに集約結果上位のものを抽出する例はググればすぐ出てくるですが(Treasure Data で動く例は出てこないですが)、グループの中に全体を 1 つのグループとしたものが含まれる例はないんじゃないかと思います。
完成した HiveQL
試行錯誤の結果、次のような HiveQL になりました。
SELECT
month,
page,
TD_X_RANK(month) AS page_rank,
access_count
FROM (
SELECT
month,
page,
access_count
FROM (
SELECT
page,
map(
'2014-08', SUM(IF(month = '2014-08', 1, 0)),
'2014-09', SUM(IF(month = '2014-08', 0, 1)),
'total', COUNT(1)
) access_count_map
FROM
access_logs
GROUP BY
page
) t1
LATERAL VIEW
explode(access_count_map) access_counts AS month, access_count
DISTRIBUTE BY
month
SORT BY
month,
access_count DESC
) t2
WHERE
TD_X_RANK(month) <= 2
;
結果は次のようになります。
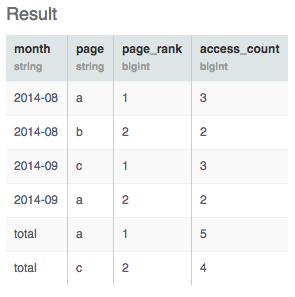
いい感じですねっ!
解説
まず、
SELECT
page,
map(
'2014-08', SUM(IF(month = '2014-08', 1, 0)),
'2014-09', SUM(IF(month = '2014-08', 0, 1)),
'total', COUNT(1)
) access_count_map
FROM
access_logs
GROUP BY
page
で、次のデータを
| month | page |
|---|---|
| 2014-08 | a |
| 2014-08 | b |
| 2014-08 | a |
| 2014-08 | a |
| 2014-08 | c |
| 2014-08 | b |
| 2014-09 | c |
| 2014-09 | a |
| 2014-09 | c |
| 2014-09 | b |
| 2014-09 | a |
| 2014-09 | c |
次のようなデータにしています。
| page | access_count_map |
|---|---|
| a | {“total”: 5, “2014-08”: 3, “2014-09”: 2} |
| b | {“total”: 3, “2014-08”: 2, “2014-09”: 1} |
| c | {“total”: 4, “2014-08”: 1, “2014-09”: 3} |
次に、
SELECT
month,
page,
access_count
FROM (
...
) t1
LATERAL VIEW
explode(access_count_map) access_counts AS month, access_count
で、先ほど処理したデータ
| page | access_count_map |
|---|---|
| a | {“total”: 5, “2014-08”: 3, “2014-09”: 2} |
| b | {“total”: 3, “2014-08”: 2, “2014-09”: 1} |
| c | {“total”: 4, “2014-08”: 1, “2014-09”: 3} |
を次のようなデータに変換しています。
| month | page | access_count |
|---|---|---|
| total | a | 5 |
| 2014-08 | a | 3 |
| 2014-09 | a | 2 |
| total | b | 3 |
| 2014-08 | b | 2 |
| 2014-09 | b | 1 |
| total | c | 4 |
| 2014-08 | c | 1 |
| 2014-09 | c | 3 |
最後に、
SELECT
month,
page,
TD_X_RANK(month) AS page_rank,
access_count
FROM (
...
DISTRIBUTE BY
month
SORT BY
month,
access_count DESC
) t2
WHERE
TD_X_RANK(month) <= 2
;
で、先ほど変換したデータ
| month | page | access_count |
|---|---|---|
| total | a | 5 |
| 2014-08 | a | 3 |
| 2014-09 | a | 2 |
| total | b | 3 |
| 2014-08 | b | 2 |
| 2014-09 | b | 1 |
| total | c | 4 |
| 2014-08 | c | 1 |
| 2014-09 | c | 3 |
をソートした上で page_rank を付与し、page_rank が 2 以下のものだけ抽出しています。
| month | page | page_rank | access_count |
|---|---|---|---|
| 2014-08 | a | 1 | 3 |
| 2014-08 | b | 2 | 2 |
| 2014-09 | c | 1 | 3 |
| 2014-09 | a | 2 | 2 |
| total | a | 1 | 5 |
| total | c | 2 | 4 |
TD_X_RANK は、指定したフィールドに関して同じ値が連続する場合に 1 から番号を振っていく UDF のようです。
DISTRIBUTE BY month で month が同じものは同じ reducer に割り振られることを保証し、SORT BY month, access_count DESC で reducer ごとに同じ month が連続し、access_count に関して降順になるようにソートします。
各 reducer では同じ month が続く限り 1 から番号を振ることで access_count の大きな順に番号が割り振られることになります。
余談
最初は次のような HiveQL を考えたんですが、reducer 側で処理するデータが無駄に増えるので良くなさそうです。
SELECT
exploded_month,
page,
TD_X_RANK(exploded_month),
access_count
FROM (
SELECT
exploded_month,
page,
COUNT(1) access_count
FROM
access_logs
LATERAL VIEW
explode(array(month, 'all')) months AS exploded_month
GROUP BY
exploded_month,
page
DISTRIBUTE BY
exploded_month
SORT BY
exploded_month,
access_count DESC
) t
WHERE
TD_X_RANK(exploded_month) <= 2
;
以上、物凄くマイナーな HiveQL の例でした!