GDBM で学ぶ Extendible Hashing

最近仕事で GDBM を使う機会があり、GDBM で使われている extendible hashing に興味を持ったのでまとめてみました。
なお、今回対象にしている GDBM のバージョンは 1.12 です。
アジェンダ
GDBM とは
http://www.gnu.org.ua/software/gdbm/ 曰く
GNU dbm (or GDBM, for short) is a library of database functions that use extensible hashing and work similar to the standard UNIX dbm.
とのことです。
個人的には次のような特徴があると思っています。
- extendible hashing を採用した disk-based hash table
- binary-safe
- キー、値共に扱えるのは文字列のみ
- ネットワークを経由しないので高速
- Ruby 組み込みで使える1
Ruby からは次のように使うことができます。
require 'gdbm'
filename = '/tmp/gdbm.db'
GDBM.open(filename, 0666, GDBM::NEWDB) do |db|
db['k1'] = 'value1'
db['k2'] = 'value2'
end
db = GDBM.open(filename, 0666, GDBM::READER | GDBM::NOLOCK)
db['k1'] #=> 'value1'
db['k2'] #=> 'value1'
db.close
というわけで、ハッシュテーブル、extendible hashing についてざっくり説明し、GDBM で extendible hashing がどのように実装されているか簡単に見ていこうと思います。
ハッシュテーブルの基礎
ハッシュテーブルはキーのハッシュ値をインデックスに使用する配列で、ハッシュ値の衝突がなければ検索や挿入を O(1) で行えるのが特徴です。
value = hash_table[h(key)]
hash_table[h(another_key)] = another_value
実際にはハッシュ値を配列のサイズで割った時の余りがインデックスとして使われることが多いように思います。
value = hash_table[h(key) % hash_table.size]
hash_table[h(another_key) % hash_table.size] = another_value
ハッシュ関数
ハッシュ関数と言うと MD5 や SHA-1 等の暗号学的ハッシュ関数が有名ですが、速度の面からこれらのハッシュ関数がハッシュテーブルに使われることはありません。
例えば DJBX33A と呼ばれるハッシュ関数は Ruby で書くと次のようなシンプルな関数です。
def h(key)
hash = 5381
key.each_byte do |byte|
hash = (33 * hash + byte) & 0xffffffff # unsigned 32-bit int
end
hash
end
“abc” という文字列は上記のハッシュ関数に通すことで 193485963 に変換されます。
ただ、DJBX33A のようなハッシュ関数は Hash-flooding DoS(ハッシュ値の衝突を意図的大量に発生させて CPU 資源を枯渇させる攻撃)が可能なので、Ruby を始め、多くの言語で SipHash が採用されているようです。2
衝突処理
予め使用されるキーがわかっていて h(key) % hash_table.size の結果を一意にできるのであれば次のように単純な処理で挿入・検索を実現できます。
def insert(hash_table, key, value)
hash_table[h(key) % hash_table.size] = value
end
def lookup(hash_table, key)
hash_table[h(key) % hash_table.size]
end
そうでない場合、異なるキーでも同じインデックスになること(衝突)を考慮する必要があります。
衝突処理として、主なものに開番地法 (Open Addressing) と分離連鎖法 (Separate Chaining) があります。
開番地法は配列の空いている他の箇所を探す方法で、探し方には linear probing、quodratic probing, double hashing などがあります。linear probing は求めたインデックスからシーケンシャルに他の要素を探していく方法で、Ruby で表現すると次のようなイメージです。
def insert(hash_table, key, value)
idx = h(key) % hash_table.size
while entry = hash_table[idx]
break if entry[:key] == key
idx = (idx + 1) % hash_table.size
end
hash_table[idx] = { key: key, value: value }
end
def lookup(hash_table, key)
idx = h(key) % hash_table.size
while entry = hash_table[idx]
return entry[:value] if entry[:key] == key
idx = (idx + 1) % hash_table.length
end
end
分離連鎖法は配列の各要素に連結リストを格納する方法で、Ruby で表現すると次のようなイメージです。
def insert(hash_table, key, value)
idx = h(key) % hash_table.size
entry = hash_table[idx]
if entry.nil?
hash_table[idx] = { key: key, value: value }
return
end
while entry[:next]
if entry[:key] == key
entry[:value] = value
return
end
entry = entry[:next]
end
entry[:next] = { key: key, value: value }
end
def lookup(hash_table, key)
idx = h(key) % hash_table.size
entry = hash_table[idx]
while entry
return entry[:value] if entry[:key] == key
entry = entry[:next]
end
end
全て衝突する場合、どちらの衝突処理も要素数 n に対して検索も挿入も O(n) になります。
リハッシュ
ハッシュテーブルの配列の密度が高くなってくると衝突回数が多くなります。ハッシュテーブルの密度の指標として、次の式で表される load factor が使われます。
load factor = ハッシュテーブルの要素数 n ÷ 配列のサイズ k
衝突回数を減らすため、load factor が一定値以上になれば配列のサイズを増やします。これをリハッシュと呼びます。3
リハッシュの方法にもいくつかありますが、配列のサイズを 2 倍にして全要素を新しい配列にコピーする場合、次のようなイメージです。
def rehash(hash_table)
new_hash_table = Array.new(hash_table.size * 2)
hash_table.each do |entry|
next if entry.nil?
insert(new_hash_table, entry[:key], entry[:value])
end
new_hash_table
end
今回扱う extendible hashing は一度に行うリハッシュのコストを下げる工夫のされたハッシュテーブルです。
以上がハッシュテーブルの基礎的な内容です。
より詳細に知りたい方は次の文献が非常に詳しく解説されていてるのでオススメです。
Extendible Hashing
extendible hashing は小さなハッシュテーブル(バケット)を束ねたハッシュテーブルであり、リハッシュがバケット単位で行われるので一度のリハッシュにかかるコストが低いのが特徴です。
各バケットへのポインタを格納したディレクトリとバケットから成ります。
ディレクトリのサイズが 4、バケットの数が 2、各バケットのサイズが 2 の extendible hash の構造は次のように表されます。
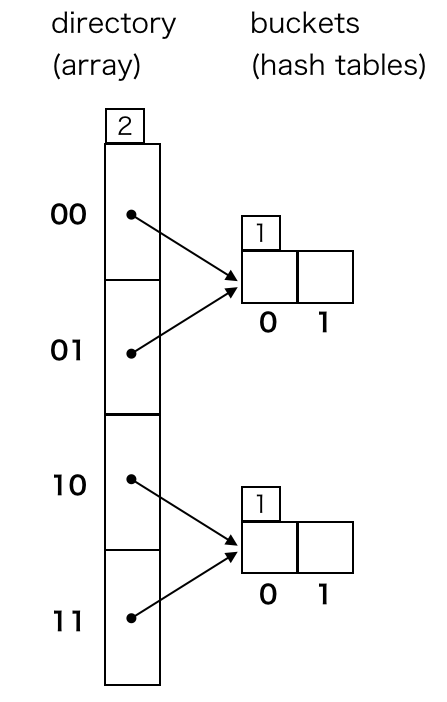
ディレクトリも各バケットも depth という概念を持っており、ここではそれぞれ directory depth、local depth と表現することにします。図中の左上に表示してある数が depth です。
directory depth は、ハッシュ値からディレクトリのインデックスを決定する際にハッシュ値の上位何ビットを使用するかを意味します。local depth は、そのバケットがハッシュ値の上位何ビットまで同じキーの要素を格納できるかを意味します。その性質上、directory depth >= local depth が成り立ちます。
図中の上のバケットはディレクトリのインデックス 00、01 の指し示すバケットであり、ハッシュ値の上位 1 ビットが 0 のキーの要素の格納先になっています。
Ruby で表現すると次のようなイメージです。Bucket と Directory の定義は雰囲気で感じとってください。
directory = Directory.new(depth: 2)
bucket1 = Bucket.new(depth: 1)
bucket2 = Bucket.new(depth: 1)
directory.buckets = [bucket1, bucket1, bucket2, bucket2]
この extendible hash に次のキーの要素を格納することを考えます。ハッシュ値は unsigned 8-bit integer とします。
| キー | ハッシュ値 |
|---|---|
| k1 | 01001011 |
| k2 | 11010010 |
| k3 | 00100000 |
| k4 | 01110010 |
| k5 | 01100011 |
まず k1 ですが、ディレクトリの depth である上位 2 ビットが 01 なので、directory[0b01] の指し示すバケットが格納先のバケットになります。バケットはハッシュテーブルなので、h(k1) % bucket.size がハッシュテーブルのインデックスになります。
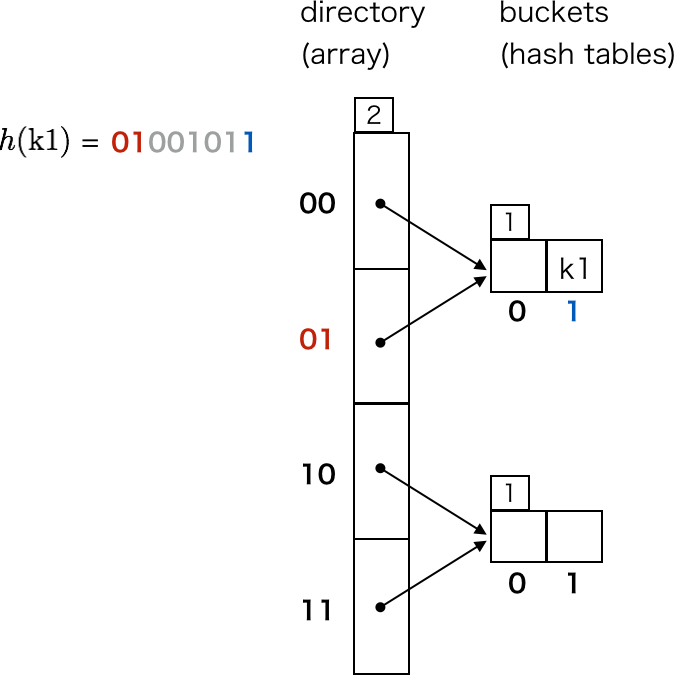
Ruby で表現すると次のようなイメージです。Entry の定義は雰囲気で感じとってください。
bucket = directory.buckets[h(k1) >> (8 - directory.depth)]
bucket.entries[h(k1) % bucket.size] = Entry.new(key: k1, value: nil, hash_value: h(k1))
同様に、k2, k3 も挿入できます。
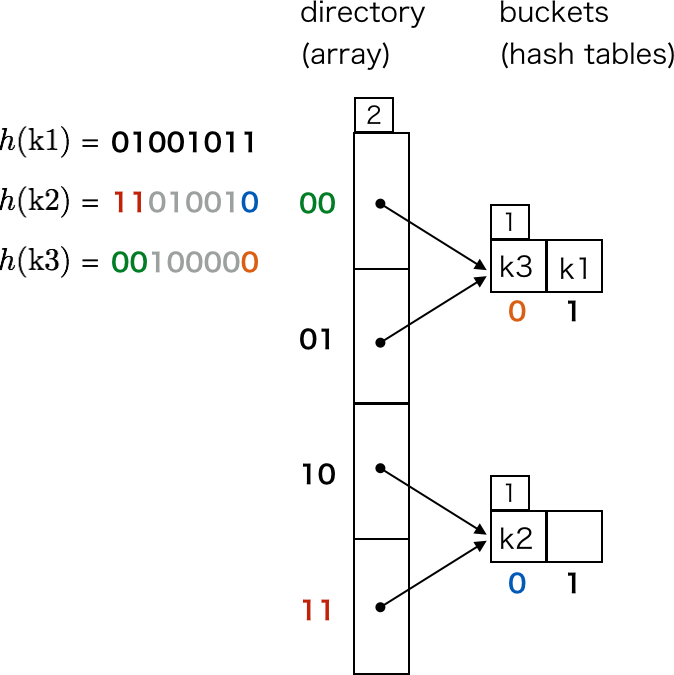
ここで、k4 を挿入しようとすると、directory[0b01] の指し示すバケットが満杯であることがわかります。そこで、ハッシュ値の上位 2 ビットが同じキーの要素を格納できるよう、バケットを分割します。これによって k4 の要素も挿入できるようになります。
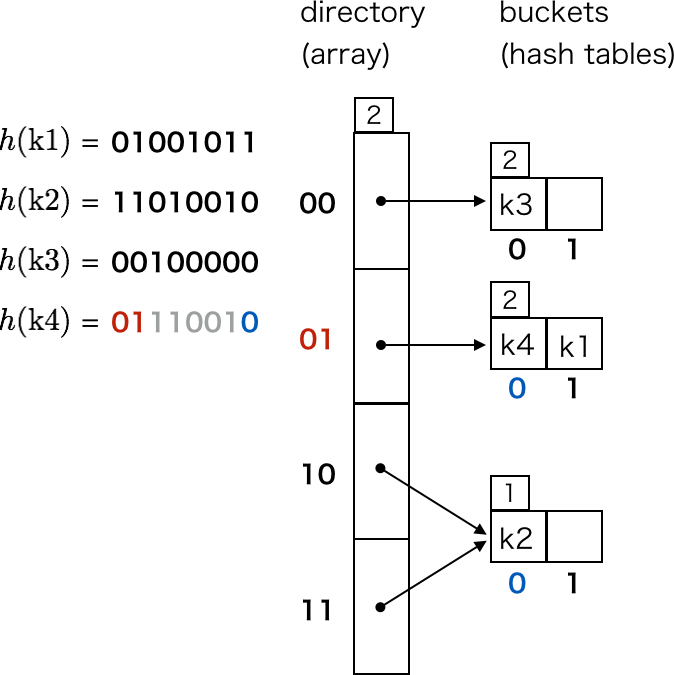
バケットの分割は Ruby で表現すると次のようなイメージです。
bucket = directory.buckets[h(k4) >> (8 - directory.depth)]
if bucket.full? && directory.depth > bucket.depth
new_depth = bucket.depth + 1
buckets = [Bucket.new(depth: new_depth), Bucket.new(depth: new_depth)]
bucket.entries.each do |entry|
buckets[(entry.hash_value >> (8 - new_depth)) & 1] = entry
end
directory.buckets[0] = buckets[0]
directory.buckets[1] = buckets[1]
end
次に、k5 を挿入しようとすると、またしても directory[0b01] の指し示すバケットが満杯であることがわかります。directory depth も local depth も 2 なので、これ以上バケットを分割することもできません。
そこで、ディレクトリを拡張して directory depth を 3 にします。具体的には、2 倍のサイズの配列を生成し、格納しているポインタをコピーします。ディレクトリを拡張するだけではバケットの数は増えません。
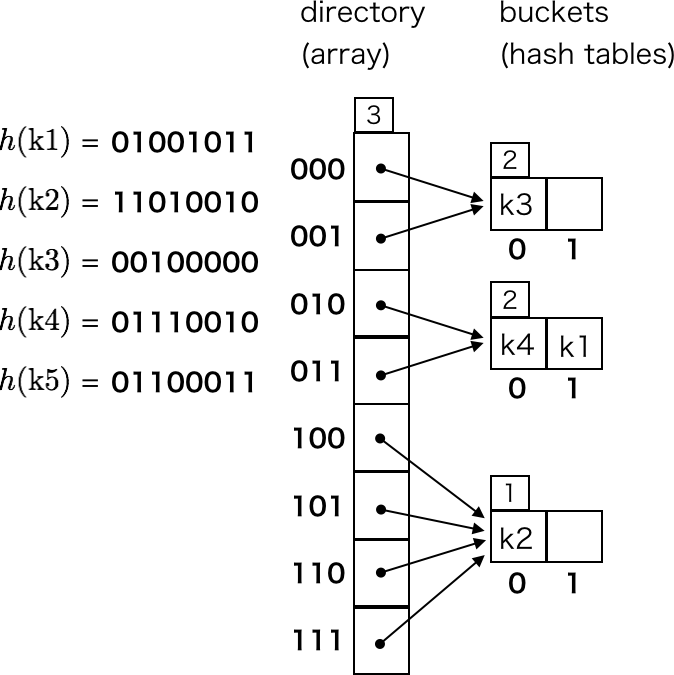
ディレクトリの拡張は Ruby で表現すると次のようなイメージです。
new_directory = Directory.new(depth: directory.depth * 2)
directory.buckets.each.with_index do |bucket, i|
new_directory.buckets[2 * i] = bucket
new_directory.buckets[2 * i + 1] = bucket
end
directory = new_directory
これによって、k5 の格納先のバケットも分割できるようになります。
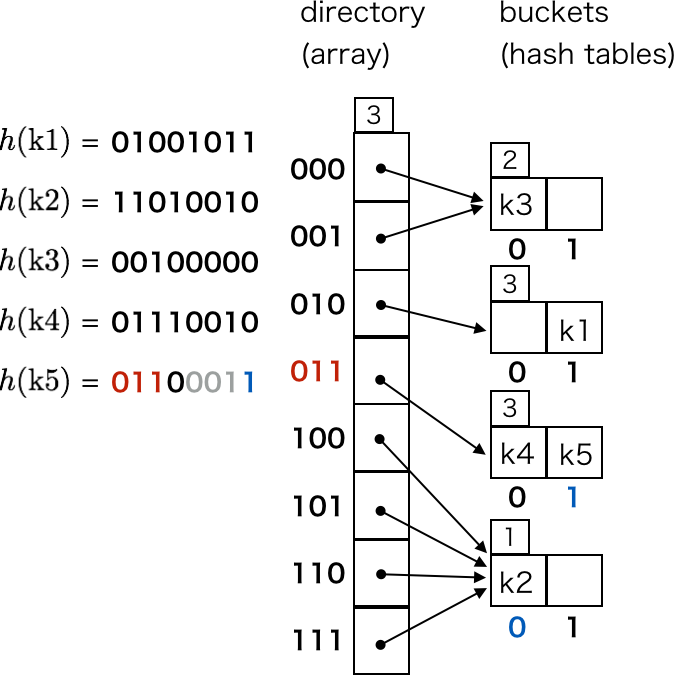
以上が extendible hashing の原理です。バケットを分割する際、分割対象のバケットのリハッシュしか行われず、ディレクトリを拡張する際もディレクトリのポインタのコピーしか発生しないことがポイントです。
バケットでの衝突処理については触れませんでしたが、普通のハッシュテーブル同様、開番地法等による衝突処理が必要なので注意してください。
GDBM による Extendible Hashing
GDBM のコードはキャッシュ周りの処理やファイル上のどの位置に情報を保存するかを決める処理は複雑なものの、それ以外はコード量も少なく比較的読みやすいので、extendible hashing を学ぶには良い対象です。
ハッシュ関数
GDBM のハッシュ関数は hash.c に次のように定義されています。
int
_gdbm_hash (datum key)
{
unsigned int value; /* Used to compute the hash value. */
int index; /* Used to cycle through random values. */
/* Set the initial value from key. */
value = 0x238F13AF * key.dsize;
for (index = 0; index < key.dsize; index++)
value = (value + (key.dptr[index] << (index*5 % 24))) & 0x7FFFFFFF;
value = (1103515243 * value + 12345) & 0x7FFFFFFF;
/* Return the value. */
return((int) value);
}
1103515243 等でググってみたところ、他のコードで同様のハッシュ関数を使っているものはどれも GDBM から持ってきたとコメントが書いてあるので、GDBM 独自のハッシュ関数のようです。
最後の value = (1103515243 * value + 12345) & 0x7FFFFFFF は rand の Example に出てくる式の RAND_MAX を signed 32-bit integer の最大値としたものとほぼ同じなので、線形合同法を意識した実装と思われます。
ユーザの任意の入力を GDBM に保存するということはないと思いますが、DJBX33A 同様、衝突するキーを容易に作成できるので、そのような用途で使うと Hash-flooding DoS が危険があります。
例えば、”02”, “P1”, “p0” はどれも同じハッシュ値になるので、これらの文字列を組み合わせることで同じハッシュ値になるキーを大量に作成可能です。
#include <stdio.h>
#include <gdbm.h>
int _gdbm_hash (datum key);
int main(int argc, char **argv) {
datum keys[] = {
{ .dptr = "02", .dsize = 2 },
{ .dptr = "P1", .dsize = 2 },
{ .dptr = "p0", .dsize = 2 },
{ .dptr = "0202", .dsize = 4 },
{ .dptr = "P102", .dsize = 4 },
{ .dptr = "p002", .dsize = 4 },
};
for (int i = 0; i < sizeof(keys) / sizeof(datum); ++i) {
printf("%s: %d\n", keys[i].dptr, _gdbm_hash(keys[i]));
}
return 0;
}
上記のコードの実行結果は次のとおりです。
02: 652613971
P1: 652613971
p0: 652613971
0202: 1148613021
P102: 1148613021
p002: 1148613021
ファイルヘッダのデータ構造
ヘッダの定義は gdbmdefs.h に次のように定義されています。
/* The dbm file header keeps track of the current location of the hash
directory and the free space in the file. */
typedef struct {
int header_magic; /* Version of file. */
int block_size; /* The optimal i/o blocksize from stat. */
off_t dir; /* File address of hash directory table. */
int dir_size; /* Size in bytes of the table. */
int dir_bits; /* The number of address bits used in the table.*/
int bucket_size; /* Size in bytes of a hash bucket struct. */
int bucket_elems; /* Number of elements in a hash bucket. */
off_t next_block; /* The next unallocated block address. */
avail_block avail; /* This must be last because of the pseudo
array in avail. This avail grows to fill
the entire block. */
} gdbm_file_header;
主要なメンバの意味は次のとおりです。
| メンバ | 概要 |
|---|---|
| header_magic | off_t のサイズによって異なるマジックナンバーになる。データベースファイルを作成した環境と使用する環境が異なるとマジックナンバーの不一致によりエラーになる場合がある。 |
| block_size | ファイルシステムのブロックサイズ |
| dir | データベースファイル上の、ディレクトリの開始位置 |
| dir_size | ディレクトリの容量 |
| dir_bits | directory depth |
| bucket_size | バケットの容量 |
| bucket_elems | バケットに格納できる要素数 |
ヘッダの情報から、データベースファイルを作成する環境と使用する環境は統一した方が良いことがわかります。
次のように要素数 0 のデータベースファイルを作成してヘッダ情報を確認してみましょう。
#include <gdbm.h>
int main(int argc, char **argv) {
GDBM_FILE dbf = gdbm_open("tmp.db", 0, GDBM_NEWDB, 0666, 0);
gdbm_close(dbf);
return 0;
}
各値は次のようになっています。
% ruby -e 'puts File.binread("tmp.db", 32).unpack("IIQI*")'
324508367
4096
4096
4096
9
4096
166
これより、directory depth は初期状態で 9、ディレクトリの容量は 4096 バイト、バケットに格納できる要素数は 166 であることがわかります。
ディレクトリはバケットのポインタ(データベースファイル上のファイル位置)の配列なので、29 x sizeof(off_t) = 4096 です。
バケットのデータ構造
バケットの定義は gdbmdefs.h に次のように定義されています。
/* A bucket is a small hash table. This one consists of a number of
bucket elements plus some bookkeeping fields. The number of elements
depends on the optimum blocksize for the storage device and on a
parameter given at file creation time. This bucket takes one block.
When one of these tables gets full, it is split into two hash buckets.
The contents are split between them by the use of the first few bits
of the 31 bit hash function. The location in a bucket is the hash
value modulo the size of the bucket. The in-memory images of the
buckets are allocated by malloc using a calculated size depending of
the file system buffer size. To speed up write, each bucket will have
BUCKET_AVAIL avail elements with the bucket. */
typedef struct {
int av_count; /* The number of bucket_avail entries. */
avail_elem bucket_avail[BUCKET_AVAIL]; /* Distributed avail. */
int bucket_bits; /* The number of bits used to get here. */
int count; /* The number of element buckets full. */
bucket_element h_table[1]; /* The table. Make it look like an array.*/
} hash_bucket;
主要なメンバの意味は次のとおりです。
| メンバ | 概要 |
|---|---|
| bucket_bits | バケットの depth |
| count | バケット内の要素数 |
| h_table | バケットのハッシュテーブル(要素数が header->bucket_elems のフレキシブル配列) |
よって、header->bucket_elems と bucket->count が一致するとバケットが満杯であることを意味します。
要素を挿入するのは gdbm_store 関数ですが、次の箇所でバケットを分割するかどうか判断しています。
if (dbf->bucket->count == dbf->header->bucket_elems)
{
/* Split the current bucket. */
_gdbm_split_bucket (dbf, new_hash_val);
}
バケット要素のデータ構造
バケット要素の定義は gdbmdefs.h に次のように定義されています。
/* The dbm hash bucket element contains the full 31 bit hash value, the
"pointer" to the key and data (stored together) with their sizes. It also
has a small part of the actual key value. It is used to verify the first
part of the key has the correct value without having to read the actual
key. */
typedef struct {
int hash_value; /* The complete 31 bit value. */
char key_start[SMALL]; /* Up to the first SMALL bytes of the key. */
off_t data_pointer; /* The file address of the key record. The
data record directly follows the key. */
int key_size; /* Size of key data in the file. */
int data_size; /* Size of associated data in the file. */
} bucket_element;
メンバの意味は次のとおりです。
| メンバ | 概要 |
|---|---|
| hash_value | キーのハッシュ値 |
| key_start | キーの先頭 4 バイト。キーの比較の際に使うことで、実際の要素にアクセスする回数を減らしている。 |
| data_pointer | 実際の要素を格納しているデータベースファイル上のファイル位置 |
| key_size | キーのバイト数。data_pointer から key_size バイトがキーの内容。 |
| data_size | 値のバイト数。data_pointer + key_size から data_size バイトが値の内容。 |
衝突処理
gdbm_store 関数で既存の要素が見つからなかった場合、挿入先の h_table のインデックスを次の処理で探していることから、衝突処理は linear probing であることがわかります。(h_table に入っている要素の hash_value は -1 で初期化されています cf. _gdbm_new_bucket)
/* Find space to insert into bucket and set elem_loc to that place. */
elem_loc = new_hash_val % dbf->header->bucket_elems;
while (dbf->bucket->h_table[elem_loc].hash_value != -1)
elem_loc = (elem_loc + 1) % dbf->header->bucket_elems;
ディレクトリの拡張とバケットの分割
ディレクトリの拡張とバケットの分割処理は bucket.c の _gdbm_split_bucket 関数に相当します。
キャッシュや領域の確保・解放の処理があって非常に読みにくいですが、その辺の処理は読み飛ばします。
まず最初に、ディレクトリの拡張が必要かどうかをチェックし、必要であれば拡張します。dbf->bucket は分割対象のバケットです。
/* Double the directory size if necessary. */
if (dbf->header->dir_bits == dbf->bucket->bucket_bits)
{
dir_size = dbf->header->dir_size * 2;
dir_adr = _gdbm_alloc (dbf, dir_size);
new_dir = (off_t *) malloc (dir_size);
if (new_dir == NULL) _gdbm_fatal (dbf, _("malloc error"));
for (index = 0; index < GDBM_DIR_COUNT (dbf); index++)
{
new_dir[2*index] = dbf->dir[index];
new_dir[2*index+1] = dbf->dir[index];
}
(snip)
}
次に、予め用意しておいた 2 つのバケット (hash_bucket *bucket[2]) に分割対象のバケットの内容をコピーします。new_bits は dbf->bucket->bucket_bits + 1 です。
/* Copy all elements in dbf->bucket into the new buckets. */
for (index = 0; index < dbf->header->bucket_elems; index++)
{
old_el = & (dbf->bucket->h_table[index]);
select = (old_el->hash_value >> (31-new_bits)) & 1;
elem_loc = old_el->hash_value % dbf->header->bucket_elems;
while (bucket[select]->h_table[elem_loc].hash_value != -1)
elem_loc = (elem_loc + 1) % dbf->header->bucket_elems;
bucket[select]->h_table[elem_loc] = *old_el;
bucket[select]->count += 1;
}
最後に、ディレクトリのバケットポインタを更新します。dbf->bucket_dir は分割対象のバケットが格納されているディレクトリのインデックス、adr_0, adr_1 はそれぞれ bucket[0], bucket[1] の内容が格納される予定のファイル上の位置 (off_t) です。
/* Update the directory. We have new file addresses for both buckets. */
dir_start1 = (dbf->bucket_dir >> (dbf->header->dir_bits - new_bits)) | 1;
dir_end = (dir_start1 + 1) << (dbf->header->dir_bits - new_bits);
dir_start1 = dir_start1 << (dbf->header->dir_bits - new_bits);
dir_start0 = dir_start1 - (dir_end - dir_start1);
for (index = dir_start0; index < dir_start1; index++)
dbf->dir[index] = adr_0;
for (index = dir_start1; index < dir_end; index++)
dbf->dir[index] = adr_1;
ちょっとわかりにくいので簡単に解説します。
まず、ディレクトリの要素のうち、更新しなければいけないのは分割対象のバケットを指していた要素です。
次の図の状態で local depth 1 のバケットを分割する場合、dbf->bucket_dir は 0b100, 0b101, 0b110, 0b111 のいずれか、dbf->header->dir_bits = 3, new_bits = 2 です。
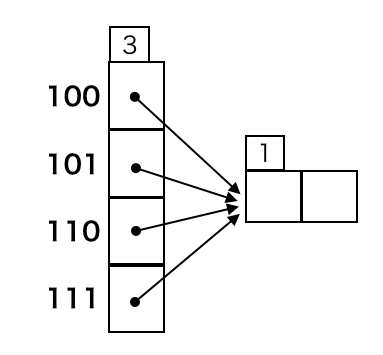
よって、dbf->bucket_dir >> (dbf->header->dir_bits - new_bits) によって、0b10 または 0b11 が得られます。これに | 1 することで 0b11 が得られ、元の分だけビットシフトすることで dir_start1 = 0b110 が得られます。
これがわかれば dir_end, dir_start0 の求め方も難しくないでしょう。
データベースファイルは要素数が多いと肥大化する
バケット要素のデータ構造的に生のキーと値がデータベースファイルに保存されるので、格納するデータのサイズが大して変わらなければデータベースファイルのサイズも同じになることを期待するかもしれません。
ところが、次のように各ハッシュを 1 つの要素として JSON で保存する場合と、
GDBM.open(filename, 0666, GDBM::NEWDB) do |db|
hashes.each.with_index do |hash, i|
db[i.to_s] = hash.to_json
end
end
次のように各ハッシュの各要素を 1 つの要素として保存する場合ではファイルサイズが大きく変わります。
GDBM.open(filename, 0666, GDBM::NEWDB) do |db|
hashes.each.with_index do |hash, i|
hash.each do |key, value|
db["#{i}:#{key}"] = value.to_s
end
end
end
これは、要素数が増えることで大量のバケットが作成されることが原因です。バケット 1 つで 4 KB の容量を占めるので、最良のケースでも 166 要素につき 4 KB 容量が増えます。
よって、各ハッシュを 1 つの要素として JSON で保存する場合に 16 万要素でバケットの合計サイズが約 4 MB だったとしても、各ハッシュの各要素を 1 つの要素として保存することで 160 万要素になると約 40 MB に膨れ上がります。
データベースファイルのサイズを意識する場合はこのことも留意した方が良いでしょう。
おわりに
以上、GDBM が採用している extendible hashing の説明と GDBM での実装の説明でした。
Ruby では手軽に GDBM を導入できるので、データの取得速度がボトルネックになっている箇所には導入してみると良いと思います!