Cassandra でレプリケーションストラテジーを変更するとデータが消失する

Cassandra でレプリケーションストラテジーを変更するとデータが消失する現象に遭遇したんですが、どうしてそんなことが起きるのかやどうしたら直せるのかがさっぱりわからなかったので、ソースコードを読んだり手を動かしたりして調べてみました。
以下、Cassandra 3.11.4 の話です。
partitioner としてデフォルトの Murmur3Partitioner を使用し、endpoint snitch として GossipingPropertyFileSnitch を使用することとします。
Cassandra のレプリカノードはどのように決まるのか?
まず、そもそも Cassandra がどのようにレプリカノードを選択しているかがわからなかったので、それについて説明します。
データセンターの数が 1、ラックの数が 2、ノード数が 3 の次のようなクラスタを考えます。
| IP Address | Data Center | Rack |
|---|---|---|
| 172.24.0.2 | dc1 | rack1 |
| 172.24.0.3 | dc1 | rack1 |
| 172.24.0.4 | dc1 | rack2 |
レプリケーション係数 1 & num_token = 1 の場合
Cassandra では consistent hasing を採用していて、まず各ノードに token が割り当てられます。
その結果は nodetool ring で確認することができます。次の出力は virtual node を無効にした場合(num_tokens = 1 の場合)のものです。
$ nodetool ring
Datacenter: dc1
==========
Address Rack Status State Load Owns Token
2913852835856394332
172.24.0.3 rack1 Up Normal 65.22 KiB 95.96% -2609423468938814500
172.24.0.4 rack2 Up Normal 127.89 KiB 74.10% -1864680695487047011
172.24.0.2 rack1 Up Normal 127.89 KiB 29.94% 2913852835856394332
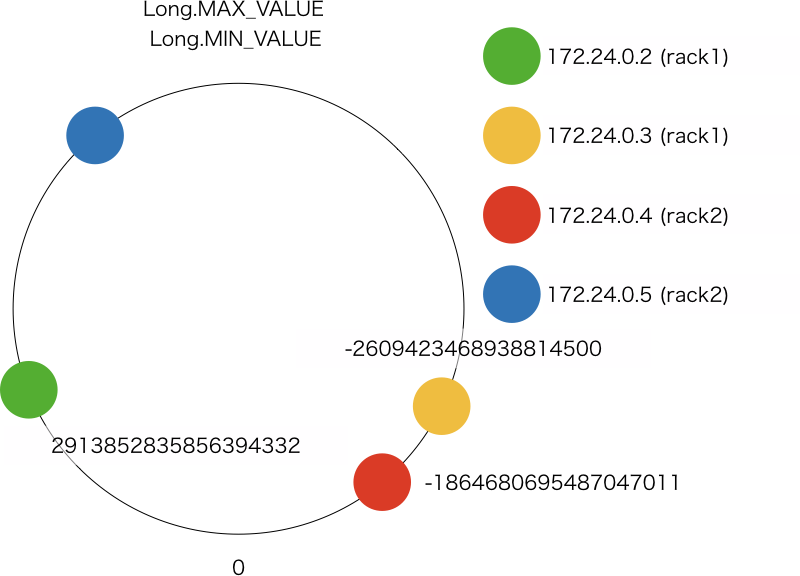
イメージとしては次のような配置です。

各ノードに割り当てられた token によって、各ノードの担当範囲は次のようになります。
| IP Address | Range |
|---|---|
| 172.24.0.2 | (-1864680695487047011, 2913852835856394332] |
| 172.24.0.3 | (-9223372036854775808, -2609423468938814500] (2913852835856394332, 9223372036854775807] |
| 172.24.0.4 | (-2609423468938814500, -1864680695487047011] |
token の下限値は Long.MIN_VALUE で上限値は Long.MAX_VALUE になっているので、172.24.0.3 の範囲はそれに合わせて分割しています。
Cassandra はデータを挿入する際に partition key から token を計算し、その token を担当するノードに保存します。token の位置から consistent hash ring を時計回りに進んで最初に到達するノードに保存するとも言い換えられます。このノードに保存されるデータのことを、本記事では便宜上プライマリーレプリカと呼ぶことにします。
例として次のテーブルを考えます。
CREATE KEYSPACE IF NOT EXISTS test
WITH REPLICATION = {
'class': 'SimpleStrategy',
'replication_factor' : 1
};
CREATE TABLE IF NOT EXISTS test.users (
app_id int,
id int,
name text,
created_at timestamp,
PRIMARY KEY (app_id, id)
);
この場合、app_id = 1 (Murmur3Partitioner#getToken = -4069959284402364209) のデータは 172.24.0.3 に保存され、app_id = 6 (Murmur3Partitioner#getToken = 2705480034054113608) のデータは 172.24.0.2 に保存されます。
$ nodetool getendpoints test users 1
172.24.0.3
$ nodetool getendpoints test users 6
172.24.0.2
仮にここで新しいノードを追加したとします。
この場合、172.24.0.3 のデータの一部が 172.24.0.5 に移るだけなので、残りのノードは新しいノードを追加したことによる負荷分散の恩恵が得られません。これを解消するのが virtual node という概念で、num_token に 1 より大きな値を指定することで実現できます。デフォルトは 256 です。
レプリケーション係数 1 & num_token = 4 の場合
続いて num_token = 4 の場合です。num_token = 4 で起動した場合、私の手元では consistent hash ring は次のようになりました。
$ nodetool ring
Datacenter: dc1
==========
Address Rack Status State Load Owns Token
9216178714344602529
172.24.0.3 rack1 Up Normal 127.85 KiB 67.48% -8556096403387275620
172.24.0.2 rack1 Up Normal 65.28 KiB 81.95% -8151920490432810868
172.24.0.3 rack1 Up Normal 127.85 KiB 67.48% -3855495865544340301
172.24.0.3 rack1 Up Normal 127.85 KiB 67.48% -2848014410424999526
172.24.0.2 rack1 Up Normal 65.28 KiB 81.95% -433108085672519511
172.24.0.4 rack2 Up Normal 145.41 KiB 50.57% -443119614084012
172.24.0.3 rack1 Up Normal 127.85 KiB 67.48% 2896250345574616760
172.24.0.4 rack2 Up Normal 145.41 KiB 50.57% 3123411945676703294
172.24.0.4 rack2 Up Normal 145.41 KiB 50.57% 3785937351724272180
172.24.0.4 rack2 Up Normal 145.41 KiB 50.57% 6479672427606371611
172.24.0.2 rack1 Up Normal 65.28 KiB 81.95% 8824499221154258863
172.24.0.2 rack1 Up Normal 65.28 KiB 81.95% 9216178714344602529
イメージとしては次のような配置です。
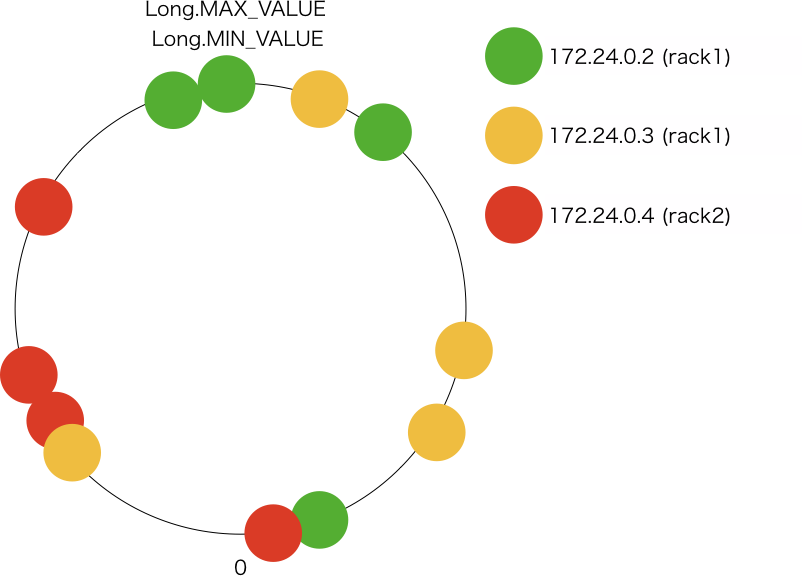
各ノードに割り当てられた token によって、各ノードの担当範囲は次のようになります。
| IP Address | Range |
|---|---|
| 172.24.0.2 | (-8556096403387275620, -8151920490432810868] (-433108085672519511, -2848014410424999526] (6479672427606371611, 8824499221154258863] (8824499221154258863, 9216178714344602529] |
| 172.24.0.3 | (-9223372036854775808, -8556096403387275620] (-8151920490432810868, -3855495865544340301] (-3855495865544340301, -2848014410424999526] (-443119614084012, 2896250345574616760] (9216178714344602529, 9223372036854775807] |
| 172.24.0.4 | (-433108085672519511, -443119614084012] (2896250345574616760, 3123411945676703294] (3123411945676703294, 3785937351724272180] (3785937351724272180, 6479672427606371611] |
ノード数は同じですが、ノードに割り当てる token を増やしたことによって仮想的にノードが増えたようになっています。これによって、新しくノードを追加したり既存のノードを削除したりした時のデータの移動を複数のノードに分散させることができます。
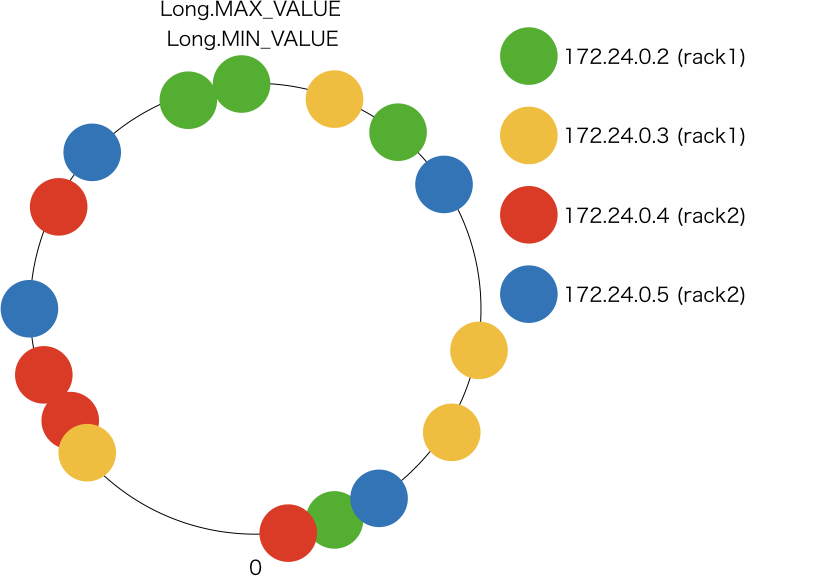
データが保存されるノードの選択ロジックは num_token = 1 の場合と同様です。
レプリケーション係数 2 & num_token = 4 の場合
いよいよ本題です。レプリケーション係数が 2 以上になると少し複雑です。というのも、レプリカノードの選択は各種レプリケーションストラテジーの calculateNaturalEndpoints の実装に依存するからです。つまり、SimpleStrategy と NetworkTopologyStrategy で異なります。
SimpleStrategy の場合
SimpleStrategy の場合、1 つ目の保存先はレプリケーション係数 1 の時と同様で、2 つ目の保存先は consistent hash ring を時計回りに進んで最初に見つかる別のノードです。
nodetool ring の結果のうち、次の範囲に注目してみます。
$ nodetool ring
Datacenter: dc1
==========
Address Rack Status State Load Owns Token
-- snip --
172.24.0.2 rack1 Up Normal 65.28 KiB 81.95% -8151920490432810868
172.24.0.3 rack1 Up Normal 127.85 KiB 67.48% -3855495865544340301
172.24.0.3 rack1 Up Normal 127.85 KiB 67.48% -2848014410424999526
172.24.0.2 rack1 Up Normal 65.28 KiB 81.95% -433108085672519511
172.24.0.4 rack2 Up Normal 145.41 KiB 50.57% -443119614084012
-- snip --
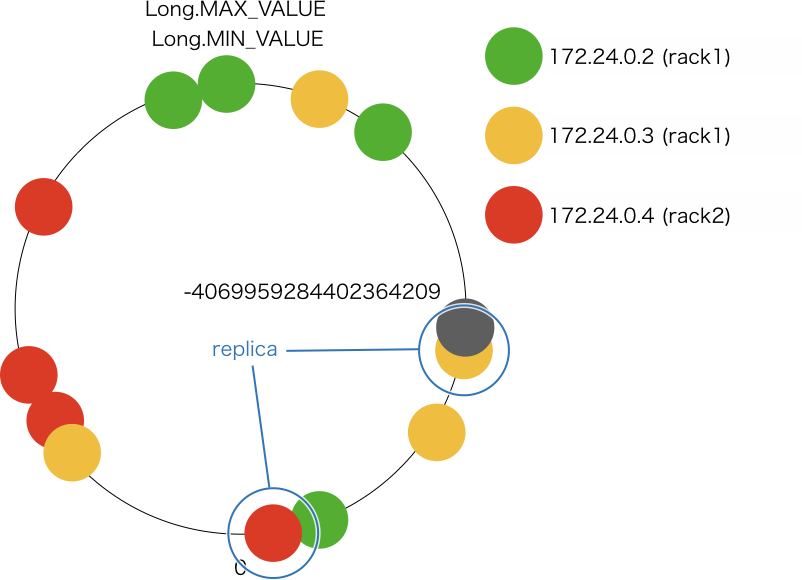
例えば、token が -4069959284402364209 になるデータを保存する場合、次のように保存先のノードが決まります。
- token は (-8151920490432810868, -3855495865544340301] の範囲に収まるので、172.24.0.3 が プライマリレプリカの保存先になる
- consistent hash ring を時計回りに進むと、次に見つかるノードは 172.24.0.3 で、すでにレプリカが存在するノードなのでスキップ
- 時計回りに更に進むと、次に見つかるノードは 172.24.0.2 なので 172.24.0.2 が 2 つ目のレプリカの保存先になる
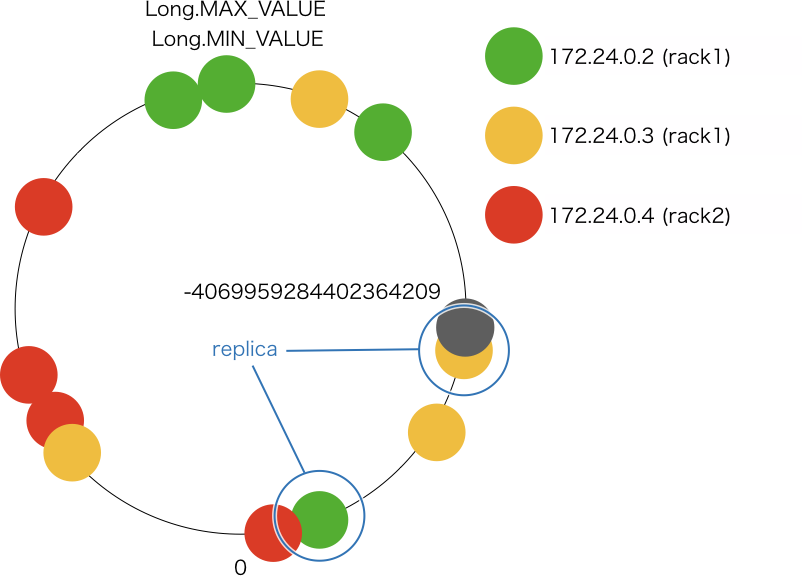
NetworkTopologyStrategy の場合
NetworkTopologyStrategy の場合、1 つ目の保存先はレプリケーション係数 1 の時と同様で、2 つ目の保存先は consistent hash ring を時計回りに進んで最初に見つかる別のラックのノードです。レプリケーション係数が 3 以上だともう少し複雑です。
SimpleStrategy 同様、nodetool ring の結果のうち、次の範囲に注目してみます。
$ nodetool ring
Datacenter: dc1
==========
Address Rack Status State Load Owns Token
-- snip --
172.24.0.2 rack1 Up Normal 65.28 KiB 81.95% -8151920490432810868
172.24.0.3 rack1 Up Normal 127.85 KiB 67.48% -3855495865544340301
172.24.0.3 rack1 Up Normal 127.85 KiB 67.48% -2848014410424999526
172.24.0.2 rack1 Up Normal 65.28 KiB 81.95% -433108085672519511
172.24.0.4 rack2 Up Normal 145.41 KiB 50.57% -443119614084012
-- snip --
例えば、token が -4069959284402364209 になるデータを保存する場合、次のように保存先のノードが決まります。
- token は (-8151920490432810868, -3855495865544340301] の範囲に収まるので、172.24.0.3 がプライマリレプリカの保存先になる
- consistent hash ring を時計回りに進むと、次に見つかるノードは 172.24.0.3 で、すでにレプリカが存在するノードなのでスキップ
- 時計回りに更に進むと、次に見つかるノードは 172.24.0.2 で、すでにレプリカが存在するラックなのでスキップ
- 時計回りに更に進むと、次に見つかるノードは 172.24.0.4 で、ラックの異なるノードなので 172.24.0.4 が 2 つ目のレプリカの保存先になる
具体例
次のテーブルを考えます。
CREATE KEYSPACE IF NOT EXISTS simple_strategy
WITH REPLICATION = {
'class': 'SimpleStrategy',
'replication_factor' : 2
};
CREATE TABLE IF NOT EXISTS simple_strategy.users (
app_id int,
id int,
name text,
created_at timestamp,
PRIMARY KEY (app_id, id)
);
CREATE KEYSPACE IF NOT EXISTS network_topology_strategy
WITH REPLICATION = {
'class': 'NetworkTopologyStrategy',
'dc1' : 2
};
CREATE TABLE IF NOT EXISTS network_topology_strategy.users (
app_id int,
id int,
name text,
created_at timestamp,
PRIMARY KEY (app_id, id)
);
app_id = 1 の場合、Murmur3Partitioner#getToken は -4069959284402364209 を返すので、nodetool getendpoints を実行することで、先ほどの説明と同じ結果になることが確認できます。
$ nodetool getendpoints simple_strategy users 1
172.24.0.3
172.24.0.2
$ nodetool getendpoints network_topology_strategy users 1
172.24.0.3
172.24.0.4
レプリケーションストラテジーの変更でデータが消える
以上の内容を理解していれば、レプリケーションストラテジーの変更でどうしてデータが消えるかわかると思います。
例として次のようなテーブルを考えます。
CREATE KEYSPACE IF NOT EXISTS test
WITH REPLICATION = {
'class': 'SimpleStrategy',
'replication_factor' : 2
};
CREATE TABLE IF NOT EXISTS test.users (
app_id int,
id int,
name text,
created_at timestamp,
PRIMARY KEY (app_id, id)
)
WITH speculative_retry = 'NONE'
AND dclocal_read_repair_chance = 0;
INSERT INTO test.users (app_id, id, name, created_at) VALUES (1, 1, 'Foo', '2019-01-01 00:00:00');
動作確認しやすくするために、speculative_retry = 'NONE', dclocal_read_repair_chance = 0 を指定することで read repair が起きないようにしています。
この状態では 172.24.0.3, 172.24.0.2 だけがデータを持っている状態です。
$ nodetool getendpoints test users 1
172.24.0.3
172.24.0.2
172.24.0.3$ nodetool flush
172.24.0.3$ sstabledump /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/*-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 41,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2019-07-15T23:00:56.137882Z" },
"cells" : [
{ "name" : "created_at", "value" : "2019-01-01 00:00:00.000Z" },
{ "name" : "name", "value" : "Foo" }
]
}
]
}
]
172.24.0.2$ nodetool flush
172.24.0.2$ sstabledump /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/*-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 41,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2019-07-15T23:00:56.137882Z" },
"cells" : [
{ "name" : "created_at", "value" : "2019-01-01 00:00:00.000Z" },
{ "name" : "name", "value" : "Foo" }
]
}
]
}
]
172.24.0.4$ nodetool flush
172.24.0.4$ sstabledump /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/*-Data.db
Cannot find file /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/*-Data.db
172.24.0.4 はデータを持っていませんが、もちろんデータを取得することはできます。ところが、レプリケーションストラテジーを変更して、再度データを取得してみると、データが見つかりません。
172.24.0.4$ cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.4 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cqlsh> SELECT * FROM test.users WHERE app_id = 1;
app_id | id | created_at | name
--------+----+---------------------------------+------
1 | 1 | 2019-01-01 00:00:00.000000+0000 | Foo
(1 rows)
cqlsh> ALTER KEYSPACE test WITH REPLICATION = {'class': 'NetworkTopologyStrategy', 'dc1' : 2};
cqlsh> SELECT * FROM test.users WHERE app_id = 1;
app_id | id | created_at | name
--------+----+------------+------
(0 rows)
というのも、app_id = 1 (Murmur3Partitioner#getToken = -4069959284402364209) のデータを持っているノードは 172.24.0.3, 172.24.0.2 から 172.24.0.3, 172.24.0.4 に変わっているのに、実際のデータは移っていないからです。
$ nodetool getendpoints test users 1
172.24.0.3
172.24.0.4
172.24.0.3$ nodetool flush
172.24.0.3$ sstabledump /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/*-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 41,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2019-07-15T23:00:56.137882Z" },
"cells" : [
{ "name" : "created_at", "value" : "2019-01-01 00:00:00.000Z" },
{ "name" : "name", "value" : "Foo" }
]
}
]
}
]
172.24.0.2$ nodetool flush
172.24.0.2$ sstabledump /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/*-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 41,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2019-07-15T23:00:56.137882Z" },
"cells" : [
{ "name" : "created_at", "value" : "2019-01-01 00:00:00.000Z" },
{ "name" : "name", "value" : "Foo" }
]
}
]
}
]
172.24.0.4$ nodetool flush
172.24.0.4$ sstabledump /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/*-Data.db
Cannot find file /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/*-Data.db
Cassandra は consistency ONE でデータを取得する場合、coordinator 自身がデータを持っていればそのデータを取得します。よって、172.24.0.4 で cqlsh から CQL を発行して app_id = 1 のデータを取得しようとすると、必ず 172.24.0.4 からデータを取得するので、データが消えたように見えるわけです。
172.24.0.3 で cqlsh から同じ CQL を発行すると、172.24.0.3 からデータを取得するので正常な結果が返ってきます。
172.24.0.3$ cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.4 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cqlsh> SELECT * FROM test.users WHERE app_id = 1;
app_id | id | created_at | name
--------+----+---------------------------------+------
1 | 1 | 2019-01-01 00:00:00.000000+0000 | Foo
(1 rows)
この不整合な状態を解消するには、172.24.0.3 で nodetool repair -full -pr を実行するか、172.24.0.4 で nodetool repair -full を実行する必要があります。172.24.0.2 で実行しても解消しません。
172.24.0.4$ nodetool repair -full
[2019-07-15 23:22:42,014] Starting repair command #1 (71844d00-a757-11e9-8ff1-139d6a4978df), repairing keyspace test with repair options (parallelism: parallel, primary range: false, incremental: false, job threads: 1, ColumnFamilies: [], dataCenters: [], hosts: [], # of ranges: 12, pull repair: false)
[2019-07-15 23:22:42,175] Repair session 718b2ad0-a757-11e9-8ff1-139d6a4978df for range [(2896250345574616760,3123411945676703294], (-8556096403387275620,-8151920490432810868], (-2848014410424999526,-433108085672519511], (3123411945676703294,3785937351724272180], (6479672427606371611,8824499221154258863], (8824499221154258863,9216178714344602529], (3785937351724272180,6479672427606371611]] finished (progress: 31%)
[2019-07-15 23:22:42,327] Repair session 71908200-a757-11e9-8ff1-139d6a4978df for range [(-433108085672519511,-443119614084012], (-443119614084012,2896250345574616760], (9216178714344602529,-8556096403387275620], (-3855495865544340301,-2848014410424999526], (-8151920490432810868,-3855495865544340301]] finished (progress: 37%)
[2019-07-15 23:22:42,362] Repair completed successfully
[2019-07-15 23:22:42,368] Repair command #1 finished in 0 seconds
[2019-07-15 23:22:42,376] Replication factor is 1. No repair is needed for keyspace 'system_auth'
[2019-07-15 23:22:42,391] Starting repair command #2 (71bf8140-a757-11e9-8ff1-139d6a4978df), repairing keyspace system_traces with repair options (parallelism: parallel, primary range: false, incremental: false, job threads: 1, ColumnFamilies: [], dataCenters: [], hosts: [], # of ranges: 6, pull repair: false)
[2019-07-15 23:22:42,492] Repair session 71c15600-a757-11e9-8ff1-139d6a4978df for range [(2896250345574616760,3123411945676703294], (-2848014410424999526,-433108085672519511], (3123411945676703294,3785937351724272180], (3785937351724272180,6479672427606371611]] finished (progress: 50%)
[2019-07-15 23:22:42,538] Repair session 71c8f721-a757-11e9-8ff1-139d6a4978df for range [(-433108085672519511,-443119614084012], (-443119614084012,2896250345574616760]] finished (progress: 60%)
[2019-07-15 23:22:42,544] Repair completed successfully
[2019-07-15 23:22:42,545] Repair command #2 finished in 0 seconds
172.24.0.4$ sstabledump /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/*-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 41,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2019-07-15T23:00:56.137882Z" },
"cells" : [
{ "name" : "created_at", "value" : "2019-01-01 00:00:00.000Z" },
{ "name" : "name", "value" : "Foo" }
]
}
]
}
]
残念なことに、172.24.0.2 には repair をしてもデータが残ったままです。
172.24.0.2$ nodetool repair -full
[2019-07-15 23:30:04,471] Starting repair command #5 (793f6830-a758-11e9-8ff1-139d6a4978df), repairing keyspace test with repair options (parallelism: parallel, primary range: false, incremental: false, job threads: 1, ColumnFamilies: [], dataCenters: [], hosts: [], # of ranges: 12, pull repair: false)
[2019-07-15 23:30:04,518] Repair session 79420040-a758-11e9-8ff1-139d6a4978df for range [(2896250345574616760,3123411945676703294], (-8556096403387275620,-8151920490432810868], (-2848014410424999526,-433108085672519511], (3123411945676703294,3785937351724272180], (6479672427606371611,8824499221154258863], (8824499221154258863,9216178714344602529], (3785937351724272180,6479672427606371611]] finished (progress: 31%)
[2019-07-15 23:30:04,549] Repair session 79449850-a758-11e9-8ff1-139d6a4978df for range [(-433108085672519511,-443119614084012], (-443119614084012,2896250345574616760], (9216178714344602529,-8556096403387275620], (-3855495865544340301,-2848014410424999526], (-8151920490432810868,-3855495865544340301]] finished (progress: 37%)
[2019-07-15 23:30:04,581] Repair completed successfully
[2019-07-15 23:30:04,582] Repair command #5 finished in 0 seconds
[2019-07-15 23:30:04,588] Replication factor is 1. No repair is needed for keyspace 'system_auth'
[2019-07-15 23:30:04,648] Repair session 7953da90-a758-11e9-8ff1-139d6a4978df for range [(2896250345574616760,3123411945676703294], (-2848014410424999526,-433108085672519511], (3123411945676703294,3785937351724272180], (3785937351724272180,6479672427606371611]] finished (progress: 50%)
[2019-07-15 23:30:04,678] Repair session 79575d00-a758-11e9-8ff1-139d6a4978df for range [(-433108085672519511,-443119614084012], (-443119614084012,2896250345574616760]] finished (progress: 60%)
[2019-07-15 23:30:04,691] Repair completed successfully
[2019-07-15 23:30:04,691] Repair command #6 finished in 0 seconds
172.24.0.2$ sstabledump /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/*-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 41,
"clustering" : [ 1 ],
"liveness_info" : { "tstamp" : "2019-07-15T23:00:56.137882Z" },
"cells" : [
{ "name" : "created_at", "value" : "2019-01-01 00:00:00.000Z" },
{ "name" : "name", "value" : "Foo" }
]
}
]
}
]
これは、repair を実行したノードが保持し得る範囲しか repair 対象にならないからです。sstable の中に repair 対象が混在していたとしても、不要になったデータが削除されることはないみたいです。
追記: nodetool cleanup で削除されることを同僚に教えてもらいました。
172.24.0.2$ nodetool cleanup
172.24.0.2$ ls /var/lib/cassandra/data/test/users-664d8a80a75411e9bef98522f7d6152d/
backups
おそらく repair では直らないケースがある
先ほどの例では全ノードに書き込みが成功している前提でしたが、そうでもないケースもあるでしょう。例えば、先ほどの例で 172.24.0.3 への書き込みが失敗していたら、レプリケーションストラテジーを変更した後はどのノードにも app_id = 1 のデータは存在しないことになります。172.24.0.2 には存在しますが、それを知る術がありません。
そう考えると、レプリケーション係数を変更するとか、レプリケーションストラテジーを変更するとか、snitch を変更するとかは致命的なデータロストに繋がりそうなんですが、世の中の Cassandra 管理者はどうやって運用してるんでしょうか…?
おまけ: Anti-entropy repair と partitioner range
nodetool repair で実行する repair を anti-entropy repair と呼びます。
nodetool repair を実行すると、デフォルトだと自身が持っているであろうデータの range 全てを対象に repair します。なお、repair 済みの sstable は対象から外れるので、それらも対象に含めたい場合は -full を付ける必要があります。
例えば、「レプリケーション係数 2 & num_token = 4 の場合」の「SimpleStrategy の場合」で、token が -4069959284402364209 のデータは 172.24.0.3 と 172.24.0.2 に保存されると説明しました。
この場合、172.24.0.3 と 172.24.0.2 のどちらも (-8151920490432810868, -3855495865544340301] の範囲のデータを保持している可能性があるので、どちらのノードで nodetool repair を実行してもこの範囲が repair 対象に含まれます。
よって、172.24.0.3 と 172.24.0.2 両方で nodetool repair を実行すると、同じ範囲のデータが 2 回 repair されて無駄です。そこで、各ノードでプライマリレプリカが保存されている範囲だけを repair 対象にすれば、全ノードで repair を実行する際に無駄なく repair できます。この「プライマリレプリカが保存される範囲」がそのノードにとっての partitioner range と呼ばれる範囲です。ソースコード上では primary range と表現されています。
既に何度か出てきているように、partitioner range は nodetool ring で確認することができます。
参考文献
DataStax のドキュメントも良いですが、適当な本を買ってみました。5 章まで読んでからソースコードを読んだらかなり理解が深まったので、細かい箇所で間違いがある気もしますが読んでみると良いかもです。
