ECS の dependsOn で HEALTHY に依存させて HEALTHY にならなければ無限に待ち続けることがある

ECS の dependsOn では condition に HEALTHY を指定することができ、依存するコンテナのヘルスチェックが通るまで待つことができます。ところが、本来 essential なコンテナのヘルスチェックが通らないとタスク全体が終了するはずが、これを指定することで HEALTHY にならない限り、無限に PENDING な状態で待ち続けることがあるようです。後述の再現コードでは無限に待ち続けましたが、別のケース(ECS agent のバージョン等色々異なる)ではちょうど 10 分程度で stopped reason が launch timeout になったので、何らかの条件ではある程度の時間が経過すると timeout になるかもしれません。
再現コード
次のファイルに対して terraform apply することで再現確認できます。今実行すると AMI は ami-01a818286958067c9 (amzn2-ami-ecs-hvm-2.0.20220318-x86_64-ebs) になり、ECS agent version は 1.60.0 になりました。
provider "aws" {}
locals {
application_name = "healthy-dependency-example"
}
data "aws_subnet" "default_1a" {
default_for_az = true
filter {
name = "availability-zone"
values = ["ap-northeast-1a"]
}
}
data "aws_ami" "most_recent_ecs_optimized" {
most_recent = true
owners = ["amazon"]
filter {
name = "name"
values = ["amzn2-ami-ecs-hvm-2.0.*-x86_64-ebs"]
}
}
resource "aws_ecs_cluster" "main" {
name = local.application_name
}
resource "aws_ecs_task_definition" "main" {
family = local.application_name
# fluetnd never becomes healhty
container_definitions = <<-JSON
[
{
"name": "main",
"image": "ubuntu",
"essential": true,
"memoryReservation": 50,
"dependsOn": [
{
"containerName": "fluentd",
"condition": "HEALTHY"
}
]
},
{
"name": "fluentd",
"image": "fluent/fluentd:v1.14.5-1.1",
"essential": true,
"memoryReservation": 50,
"healthCheck": {
"command": ["CMD", "nc", "-z", "127.0.0.1", "24225"],
"interval": 5,
"timeout": 5,
"retries": 10
}
}
]
JSON
}
resource "aws_ecs_service" "fluentd_forwarder" {
name = aws_ecs_task_definition.main.family
cluster = aws_ecs_cluster.main.name
task_definition = aws_ecs_task_definition.main.arn
desired_count = 1
}
resource "aws_instance" "main" {
ami = data.aws_ami.most_recent_ecs_optimized.image_id
instance_type = "c5.large"
subnet_id = data.aws_subnet.default_1a.id
associate_public_ip_address = true
iam_instance_profile = "ecsInstanceRole"
tags = {
Name = local.application_name
}
user_data = <<-DATA
#!/bin/bash
cat <<'EOF' >> /etc/ecs/ecs.config
ECS_CLUSTER=${aws_ecs_cluster.main.name}
ECS_AVAILABLE_LOGGING_DRIVERS=["awslogs","fluentd"]
EOF
DATA
}
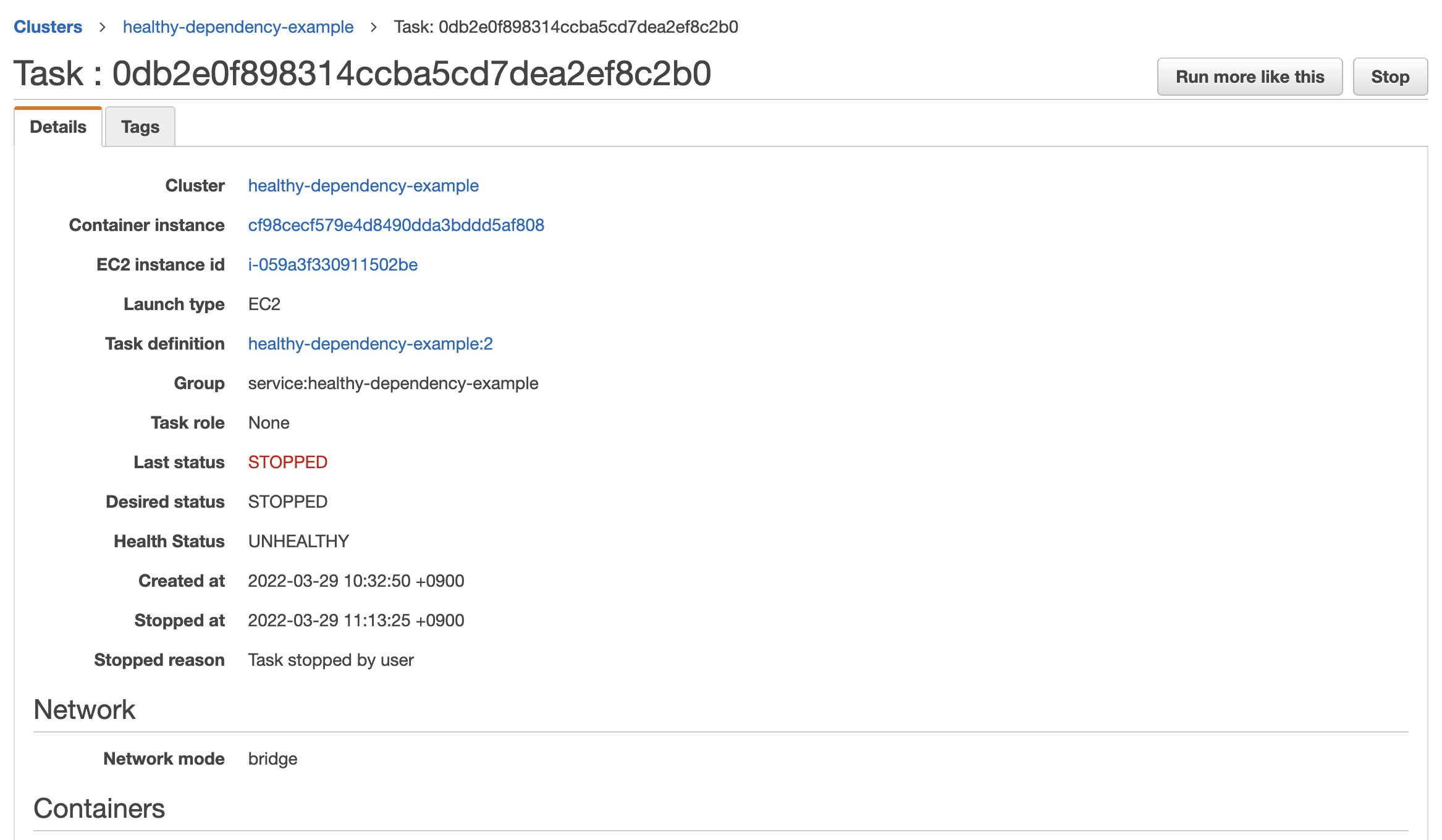
次のスクリーンショットのように created at から起動しないまま 30 分以上経過したので明示的に stop しました。
startTimeout で終了させることもできるらしい
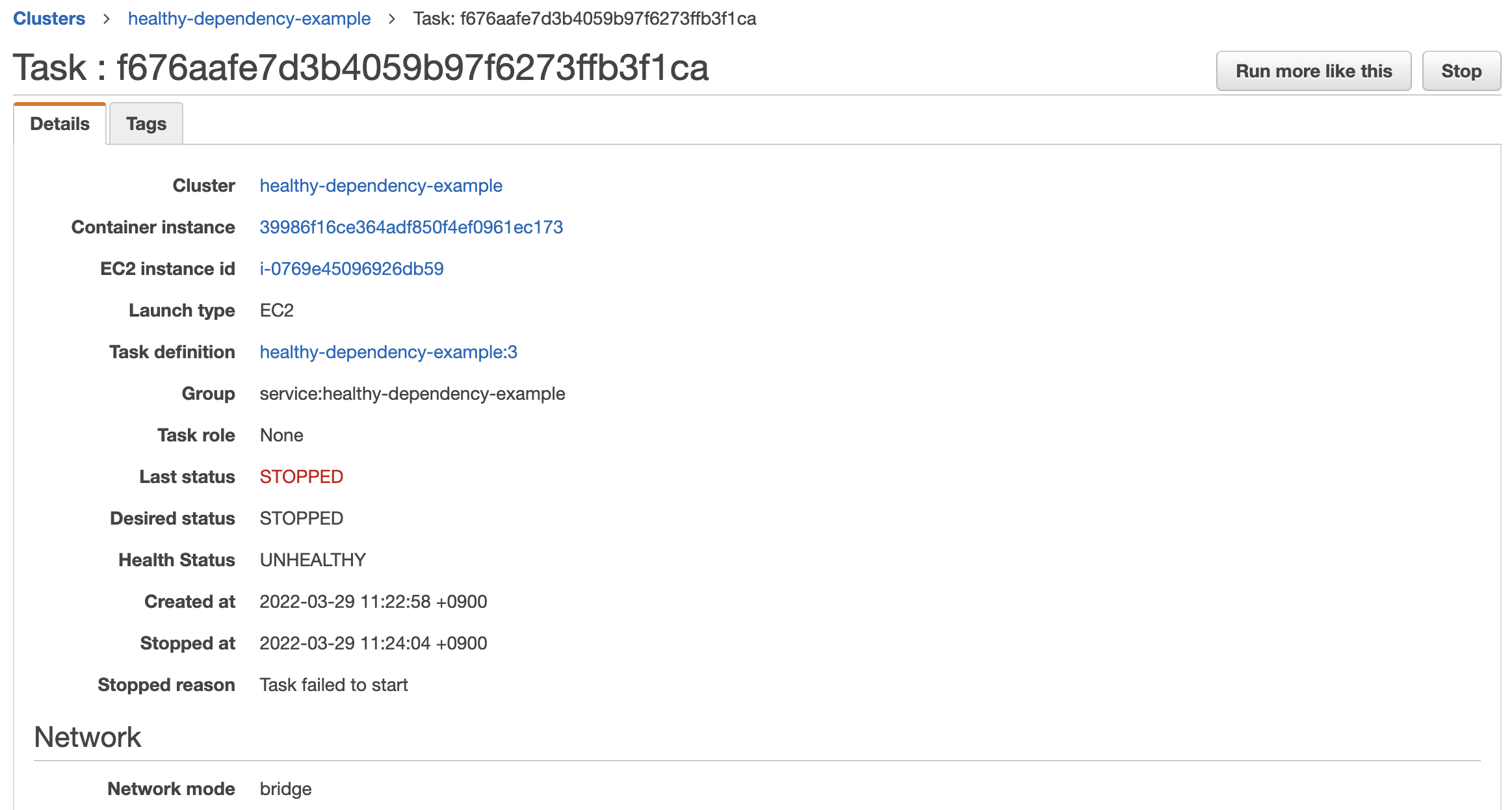
他の環境で試した時は startTimeout を指定しても効果がなかった気がするんですが、ヘルスチェックの設定を指定しているコンテナに startTimeout を指定することで、その時間内に HEALTHY にならなければ stopped reason Task failed to start になることもあるようです。
次のスクリーンショットは fluentd コンテナの startTimeout として 60 を指定した場合のタスク詳細です。
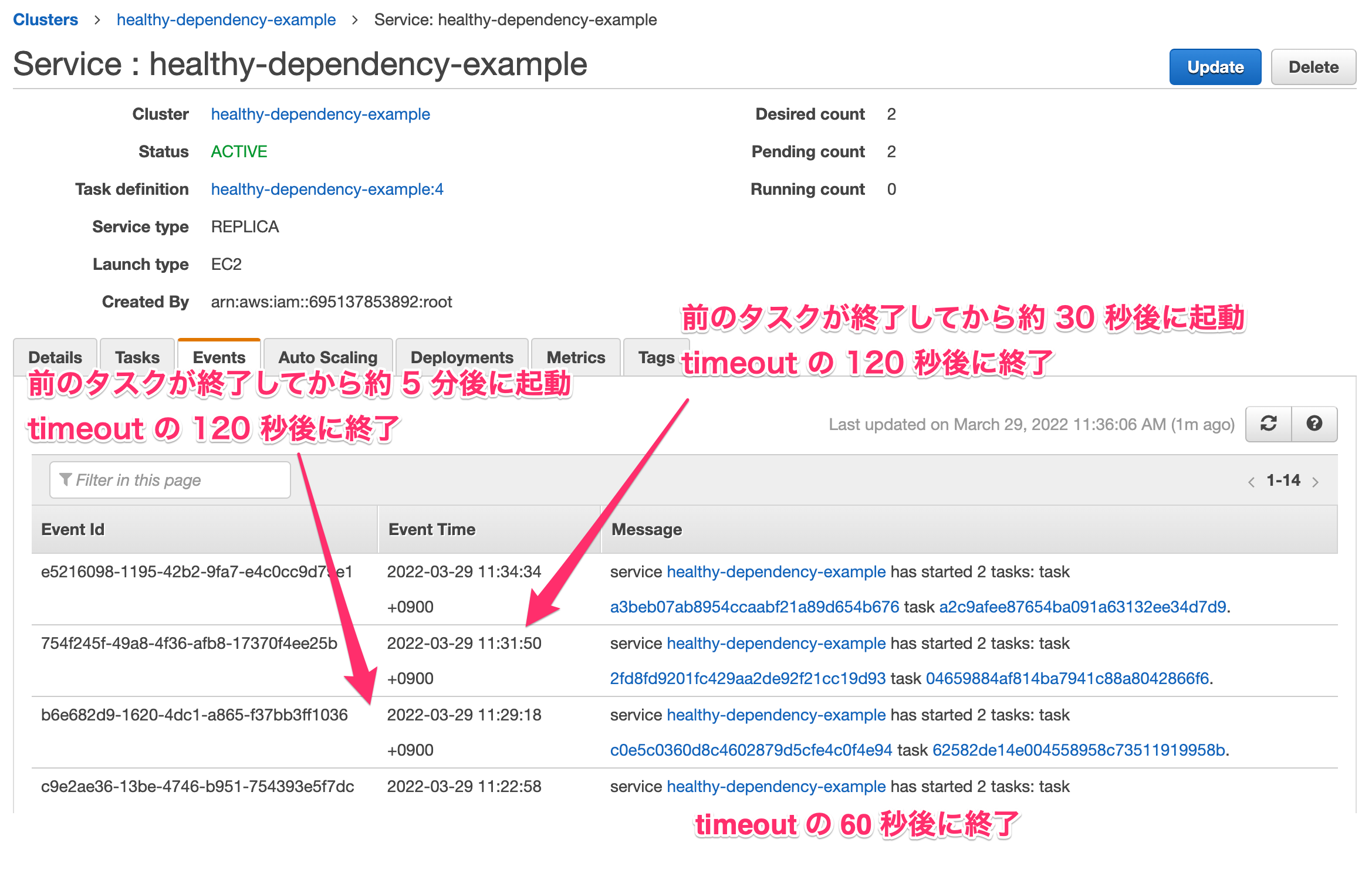
ただし、その場合は新しいタスクを起動するのに 5 分ぐらいかかるケースもあるようです。すぐに起動するケースもあるようですが…
なお、run task で起動した task も同様に startTimeout で指定した時間が経過すると終了しました。startTimeout として 120 を指定しています。
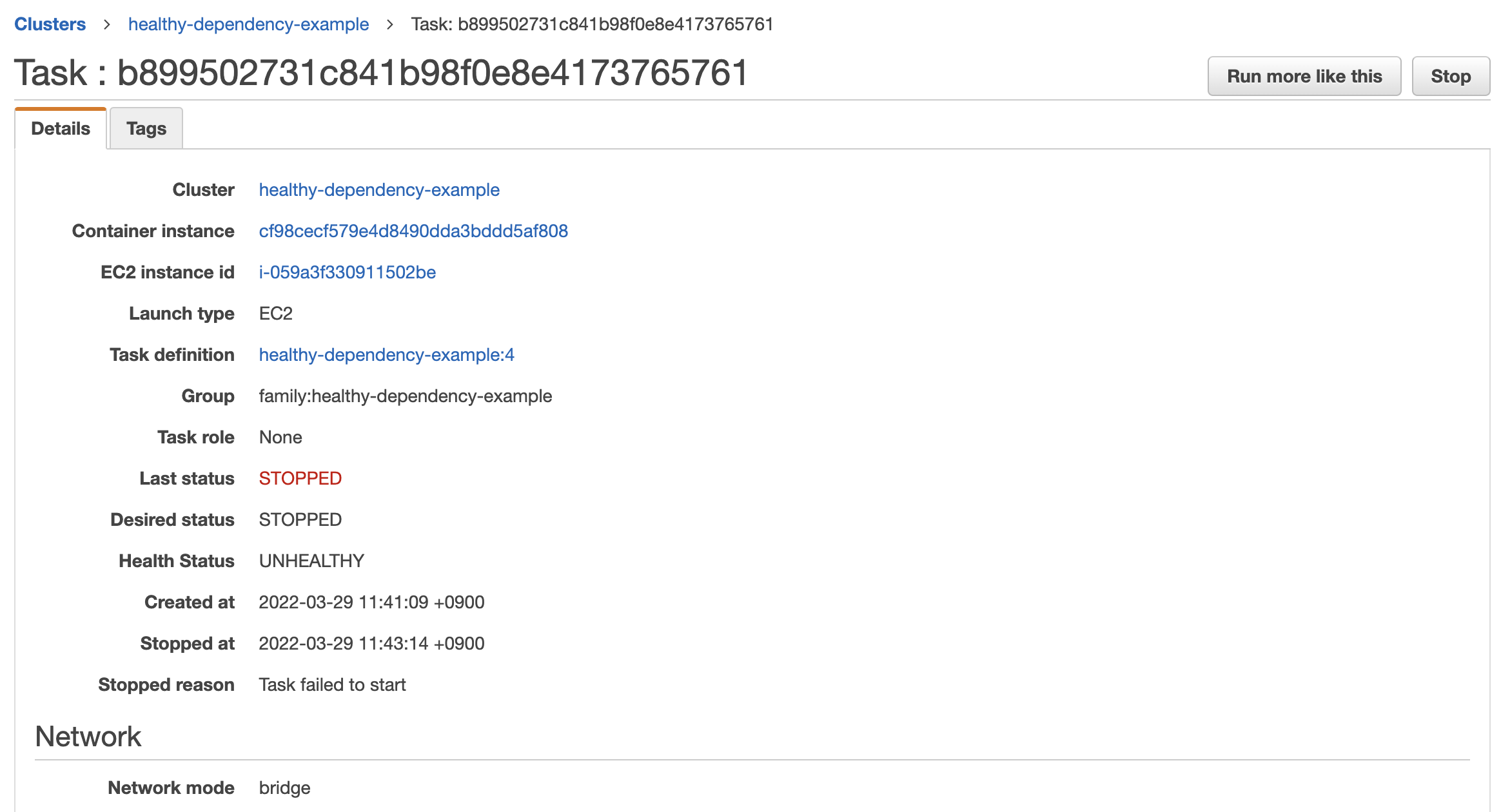
fluentd worker が gem を読み込む際に稀に stuck するようで、その場合にタスクを終了し、別のタスクを起動してくれることを期待したんですが、挙動が不安ですね…