Cassandra C/C++ Driver を使うと Cassandra で Connection reset by peer という INFO ログが出る

Cassandra C/C++ driver を使うと次のようなログが出るので調査したという話です。
INFO [epollEventLoopGroup-2-30] 2022-04-02 02:38:49,314 Message.java:623 - Unexpected exception during request; channel = [id: 0x632f6343, L:/172.31.84.31:9042 - R:/172.31.87.113:60864]
io.netty.channel.unix.Errors$NativeIoException: syscall:read(...)() failed: Connection reset by peer
at io.netty.channel.unix.FileDescriptor.readAddress(...)(Unknown Source) ~[netty-all-4.0.44.Final.jar:4.0.44.Final]
以下、Cassandra 3.11、Cassandra C/C++ driver 2.16 に対して macOS 上で調査した話です。
そもそも Connection reset by peer とは何なのか?
sockets - What does “connection reset by peer” mean? - Stack Overflow 辺りで説明されています。要は、片方が接続を閉じたのにもう片方が依然として通信しようとした場合に起きるエラーですね。
例えば次のコードを実行すると、client が接続を閉じた後に server が client にメッセージを送り、その後引き続きメッセージを受け取ろうとするので Connection reset by peer になります。
require 'logger'
require 'socket'
HOST = '127.0.0.1'
PORT = 8080
logger = Logger.new($stdout)
server_sock = TCPServer.new(HOST, PORT)
client_sock = TCPSocket.new(HOST, PORT)
th = Thread.new do
sock = server_sock.accept
logger.info("Server: Try to get a message")
msg = sock.gets
logger.info("Server: Received: #{msg}")
sleep 0.1
logger.info("Server: Send: #{msg}")
sock.puts(msg)
logger.info("Server: Try to get a message")
10.times { sock.gets } # 何故か 1, 2 回だとエラーにならないこともある
end
th.report_on_exception = false
logger.info('Client: Send hello')
client_sock.write('hello')
client_sock.close
th.join
実行すると次のようなログが出ます。
I, [2022-04-02T20:40:17.857053 #49528] INFO -- : Client: Send hello
I, [2022-04-02T20:40:17.857314 #49528] INFO -- : Server: Try to get a message
I, [2022-04-02T20:40:17.857360 #49528] INFO -- : Server: Received: hello
I, [2022-04-02T20:40:17.961273 #49528] INFO -- : Server: Send: hello
I, [2022-04-02T20:40:17.961421 #49528] INFO -- : Server: Try to get a message
/tmp/script.rb:20:in `gets': Connection reset by peer @ io_fillbuf - fd:10 (Errno::ECONNRESET)
from /tmp/script.rb:20:in `block (2 levels) in <main>'
from /tmp/script.rb:20:in `times'
from /tmp/script.rb:20:in `block in <main>'
tcpdump の結果は次のとおりです。
% sudo tcpdump -i lo0 -n tcp port 8080
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo0, link-type NULL (BSD loopback), capture size 262144 bytes
20:40:17.856691 IP 127.0.0.1.50115 > 127.0.0.1.8080: Flags [S], seq 3704873561, win 65535, options [mss 16344,nop,wscale 6,nop,nop,TS val 882104961 ecr 0,sackOK,eol], length 0
20:40:17.856785 IP 127.0.0.1.8080 > 127.0.0.1.50115: Flags [S.], seq 894336615, ack 3704873562, win 65535, options [mss 16344,nop,wscale 6,nop,nop,TS val 1111480137 ecr 882104961,sackOK,eol], length 0
20:40:17.856796 IP 127.0.0.1.50115 > 127.0.0.1.8080: Flags [.], ack 1, win 6379, options [nop,nop,TS val 882104961 ecr 1111480137], length 0
20:40:17.856800 IP 127.0.0.1.8080 > 127.0.0.1.50115: Flags [.], ack 1, win 6379, options [nop,nop,TS val 1111480137 ecr 882104961], length 0
20:40:17.857200 IP 127.0.0.1.50115 > 127.0.0.1.8080: Flags [P.], seq 1:6, ack 1, win 6379, options [nop,nop,TS val 882104961 ecr 1111480137], length 5: HTTP
20:40:17.857216 IP 127.0.0.1.50115 > 127.0.0.1.8080: Flags [F.], seq 6, ack 1, win 6379, options [nop,nop,TS val 882104961 ecr 1111480137], length 0
20:40:17.857220 IP 127.0.0.1.8080 > 127.0.0.1.50115: Flags [.], ack 6, win 6379, options [nop,nop,TS val 1111480137 ecr 882104961], length 0
20:40:17.857228 IP 127.0.0.1.8080 > 127.0.0.1.50115: Flags [.], ack 7, win 6379, options [nop,nop,TS val 1111480137 ecr 882104961], length 0
20:40:17.961403 IP 127.0.0.1.8080 > 127.0.0.1.50115: Flags [P.], seq 1:7, ack 7, win 6379, options [nop,nop,TS val 1111480241 ecr 882104961], length 6: HTTP
20:40:17.961464 IP 127.0.0.1.50115 > 127.0.0.1.8080: Flags [R], seq 3704873568, win 0, length 0
client が FIN パケットを送ったにも関わらず、server がメッセージを送ったからか、RST パケットが返ってきています。別途 lsof で確認したところ、client が FIN パケットを送って、server が ACK を返した時点で CLOSE-WAIT になり、RST パケットを送った時点で CLOSED になっているので、仕様的には次の箇所が関連してそうです(仕様というか実装例のセクションですが)
CLOSE-WAIT STATE
Send a reset segment:
<SEQ=SND.NXT><CTL=RST>
All queued SENDs and RECEIVEs should be given “connection reset” notification; all segments queued for transmission (except for the RST formed above) or retransmission should be flushed, delete the TCB, enter CLOSED state, and return.
というわけで、Cassandra で Connection reset by peer のログが出るということは、何らかの理由で client が接続を閉じたにも関わらず server からメッセージを送ることで RST パケットが返ってきて、その後も client からメッセージを読み取ろうとした場合に起きると言えそうです。要は server の意図しない形で client の方から接続を閉じた場合ですね。
ちなみに CASSANDRA-7849 では client の実装がまずいことを検知するには有用かもしれないけど、server のエラーじゃないから log level を DEBUG にしようみたいなやり取りがされています。かなり前にこの変更が取り込まれていて、その後 TRACE にまでなってるんですが、実は Native transports が使われた時のことが考慮されていなくて、この変更で正真正銘 TRACE ログになってます。なので、macOS 等 EpollEventLoopGroup をサポートしてないプラットフォームや Cassandra 3.11.4 以降で再現確認しても Connection reset by peer の INFO ログは出ないことに注意です。
再現確認
まず、client が異常終了した時に当該ログが出ることを確認します。次の docker-compose.yml を使って docker-compose up すると再現します。
version: "3.8"
services:
cassandra:
image: cassandra:3.11.3
environment:
CASSANDRA_SEEDS: 127.0.0.1
CASSANDRA_LISTEN_ADDRESS: 127.0.0.1
MAX_HEAP_SIZE: 400M
HEAP_NEWSIZE: 100M
app:
image: ruby:2.7
command: sh -c 'gem install cassandra-driver && ruby main.rb'
working_dir: /app
volumes:
- type: bind
source: .
target: /app
main.rb は次のようなコードです。もっとシンプルにできるかもしれないですが。
require 'cassandra'
logger = Logger.new($stdout)
cluster = nil
begin
cluster = Cassandra.cluster(hosts: %w[cassandra], logger: logger)
rescue Cassandra::Errors::NoHostsAvailable
sleep 1
retry
end
session = cluster.connect
session.execute(<<~CQL)
CREATE KEYSPACE IF NOT EXISTS store
WITH REPLICATION = {
'class': 'SimpleStrategy',
'replication_factor' : 1
};
CQL
session.execute(<<~CQL)
CREATE TABLE IF NOT EXISTS store.shopping_cart (
partitionid int,
userid text,
item_count int,
last_update_timestamp timestamp,
PRIMARY KEY (partitionid, userid)
);
CQL
1000.times do |i|
session.execute(<<~CQL % i, idempotent: true)
INSERT INTO
store.shopping_cart (partitionid, userid, item_count, last_update_timestamp)
VALUES
(2, '1234%04d', 3, toTimeStamp(now()));
CQL
end
Thread.new do
sleep 1
Process.kill(:KILL, Process.pid)
end
Array.new(4) do
Thread.new do
loop do
session = cluster.connect
session.execute_async('SELECT * FROM store.shopping_cart')
sleep 0.001
session.close
end
end
end.each(&:join)
次のような感じでログが出ることがわかります。
-- snip --
app_1 | D, [2022-04-02T14:56:23.150517 #38] DEBUG -- : Creating 1 request connections to 192.168.32.3
cassandra_1 | INFO [epollEventLoopGroup-2-7] 2022-04-02 14:56:23,163 Message.java:623 - Unexpected exception during request; channel = [id: 0x4be59dde, L:/192.168.32.3:9042 - R:/192.168.32.2:57716]
cassandra_1 | io.netty.channel.unix.Errors$NativeIoException: syscall:read(...)() failed: Connection reset by peer
cassandra_1 | at io.netty.channel.unix.FileDescriptor.readAddress(...)(Unknown Source) ~[netty-all-4.0.44.Final.jar:4.0.44.Final]
app_1 | Killed
cassandra_1 | INFO [epollEventLoopGroup-2-3] 2022-04-02 14:56:23,234 Message.java:623 - Unexpected exception during request; channel = [id: 0x834c6e96, L:/192.168.32.3:9042 - R:/192.168.32.2:57724]
cassandra_1 | io.netty.channel.unix.Errors$NativeIoException: syscall:read(...)() failed: Connection reset by peer
cassandra_1 | at io.netty.channel.unix.FileDescriptor.readAddress(...)(Unknown Source) ~[netty-all-4.0.44.Final.jar:4.0.44.Final]
cassandra_app_1 exited with code 137
ちなみに、Docker Desktop for Mac を使っている場合、次のような docker-compose.yml を使って、Cassandra Ruby driver の contact point を 172.16.0.2 にすれば app container は不要なんですが、Connection reset by peer は再現できないので気を付けてください。Linux でどうなるかは検証していません。
version: "3.8"
services:
cassandra:
image: cassandra:3.11.3
networks:
cassandra:
ipv4_address: 172.16.0.2
ports:
# ifconfig lo0 alias 172.16.0.2 (To delete the alias: ifconfig lo0 -alias 172.16.0.2)
- 172.16.0.2:9042:9042
environment:
CASSANDRA_SEEDS: 172.16.0.2
MAX_HEAP_SIZE: 400M
HEAP_NEWSIZE: 100M
networks:
cassandra:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.16.0.0/24
慣れてる Ruby のコードですら問題のログを出すのにめちゃくちゃ苦労したことや、C/C++ driver は最初に接続を確立しているところでログが出てそうという話があったので、RST パケットが送られてないかを確認しました。
最終的に次のコードで RST パケットが送られていることを確認しました。
#include <cassandra.h>
int main(int argc, char* argv[]) {
CassCluster* cluster = cass_cluster_new();
cass_cluster_set_contact_points(cluster, "127.0.0.1");
CassSession* session = cass_session_new();
CassFuture* future = cass_session_connect(session, cluster);
cass_future_wait(future);
return 0;
}
% gcc -o main main.c -lcassandra
% ./main
% sudo tcpdump -i lo0 -n tcp port 9042
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo0, link-type NULL (BSD loopback), capture size 262144 bytes
01:01:51.901853 IP 127.0.0.1.60298 > 127.0.0.1.9042: Flags [S], seq 3790279341, win 65535, options [mss 16344,nop,wscale 6,nop,nop,TS val 3269705598 ecr 0,sackOK,eol], length 0
01:01:51.901932 IP 127.0.0.1.9042 > 127.0.0.1.60298: Flags [S.], seq 3495878965, ack 3790279342, win 65535, options [mss 16344,nop,wscale 6,nop,nop,TS val 3990721673 ecr 3269705598,sackOK,eol], length 0
01:01:51.901940 IP 127.0.0.1.60298 > 127.0.0.1.9042: Flags [.], ack 1, win 6379, options [nop,nop,TS val 3269705598 ecr 3990721673], length 0
01:01:51.901946 IP 127.0.0.1.9042 > 127.0.0.1.60298: Flags [.], ack 1, win 6379, options [nop,nop,TS val 3990721673 ecr 3269705598], length 0
01:01:51.902051 IP 127.0.0.1.60298 > 127.0.0.1.9042: Flags [P.], seq 1:10, ack 1, win 6379, options [nop,nop,TS val 3269705598 ecr 3990721673], length 9
01:01:51.902069 IP 127.0.0.1.9042 > 127.0.0.1.60298: Flags [.], ack 10, win 6379, options [nop,nop,TS val 3990721673 ecr 3269705598], length 0
01:01:51.904650 IP 127.0.0.1.9042 > 127.0.0.1.60298: Flags [P.], seq 1:108, ack 10, win 6379, options [nop,nop,TS val 3990721675 ecr 3269705598], length 107
01:01:51.904688 IP 127.0.0.1.60298 > 127.0.0.1.9042: Flags [.], ack 108, win 6378, options [nop,nop,TS val 3269705600 ecr 3990721675], length 0
01:01:51.904921 IP 127.0.0.1.60298 > 127.0.0.1.9042: Flags [F.], seq 10, ack 108, win 6378, options [nop,nop,TS val 3269705600 ecr 3990721675], length 0
01:01:51.904949 IP 127.0.0.1.9042 > 127.0.0.1.60298: Flags [.], ack 11, win 6379, options [nop,nop,TS val 3990721675 ecr 3269705600], length 0
01:01:51.905086 IP 127.0.0.1.60299 > 127.0.0.1.9042: Flags [S], seq 1512530264, win 65535, options [mss 16344,nop,wscale 6,nop,nop,TS val 1342414003 ecr 0,sackOK,eol], length 0
01:01:51.905177 IP 127.0.0.1.9042 > 127.0.0.1.60299: Flags [S.], seq 421117837, ack 1512530265, win 65535, options [mss 16344,nop,wscale 6,nop,nop,TS val 764993117 ecr 1342414003,sackOK,eol], length 0
01:01:51.905184 IP 127.0.0.1.60299 > 127.0.0.1.9042: Flags [.], ack 1, win 6379, options [nop,nop,TS val 1342414003 ecr 764993117], length 0
01:01:51.905190 IP 127.0.0.1.9042 > 127.0.0.1.60299: Flags [.], ack 1, win 6379, options [nop,nop,TS val 764993117 ecr 1342414003], length 0
01:01:51.905302 IP 127.0.0.1.60299 > 127.0.0.1.9042: Flags [P.], seq 1:10, ack 1, win 6379, options [nop,nop,TS val 1342414003 ecr 764993117], length 9
01:01:51.905325 IP 127.0.0.1.9042 > 127.0.0.1.60299: Flags [.], ack 10, win 6379, options [nop,nop,TS val 764993117 ecr 1342414003], length 0
01:01:51.905594 IP 127.0.0.1.9042 > 127.0.0.1.60298: Flags [R.], seq 108, ack 11, win 6379, length 0
01:01:51.908357 IP 127.0.0.1.9042 > 127.0.0.1.60299: Flags [P.], seq 1:108, ack 10, win 6379, options [nop,nop,TS val 764993119 ecr 1342414003], length 107
01:01:51.908395 IP 127.0.0.1.60299 > 127.0.0.1.9042: Flags [.], ack 108, win 6378, options [nop,nop,TS val 1342414005 ecr 764993119], length 0
01:01:51.908557 IP 127.0.0.1.60299 > 127.0.0.1.9042: Flags [F.], seq 10, ack 108, win 6378, options [nop,nop,TS val 1342414005 ecr 764993119], length 0
01:01:51.908576 IP 127.0.0.1.9042 > 127.0.0.1.60299: Flags [.], ack 11, win 6379, options [nop,nop,TS val 764993119 ecr 1342414005], length 0
01:01:51.908713 IP 127.0.0.1.60300 > 127.0.0.1.9042: Flags [S], seq 3213156330, win 65535, options [mss 16344,nop,wscale 6,nop,nop,TS val 3594102261 ecr 0,sackOK,eol], length 0
01:01:51.908773 IP 127.0.0.1.9042 > 127.0.0.1.60299: Flags [R.], seq 108, ack 11, win 6379, length 0
01:01:51.908841 IP 127.0.0.1.9042 > 127.0.0.1.60300: Flags [S.], seq 2612148364, ack 3213156331, win 65535, options [mss 16344,nop,wscale 6,nop,nop,TS val 2461264152 ecr 3594102261,sackOK,eol], length 0
01:01:51.908858 IP 127.0.0.1.60300 > 127.0.0.1.9042: Flags [.], ack 1, win 6379, options [nop,nop,TS val 3594102261 ecr 2461264152], length 0
01:01:51.908865 IP 127.0.0.1.9042 > 127.0.0.1.60300: Flags [.], ack 1, win 6379, options [nop,nop,TS val 2461264152 ecr 3594102261], length 0
-- snip --
この結果から、後述するようにどこで接続を閉じているのか調査したんですが、結局再現確認できないと直ったかわからないので C/C++ driver でも再現環境を作るよう試行錯誤してみました。
最終的に次の設定で再現させることができました。複数の Cassandra ノードが必要なのがポイントです。
version: "3.8"
services:
cassandra-1:
image: cassandra:3.11.3
networks:
cassandra:
ipv4_address: 172.16.0.2
environment:
CASSANDRA_SEEDS: 172.16.0.2,172.16.0.3
MAX_HEAP_SIZE: 400M
HEAP_NEWSIZE: 100M
healthcheck:
test: ["CMD", "cqlsh", "-e", "quit"]
interval: 5s
timeout: 5s
retries: 60
cassandra-2:
image: cassandra:3.11.3
networks:
cassandra:
ipv4_address: 172.16.0.3
environment:
CASSANDRA_SEEDS: 172.16.0.2,172.16.0.3
MAX_HEAP_SIZE: 400M
HEAP_NEWSIZE: 100M
healthcheck:
test: ["CMD", "cqlsh", "-e", "quit"]
interval: 5s
timeout: 5s
retries: 60
app:
build: .
command: sh -c 'gcc -o main main.c -lcassandra && ./main'
working_dir: /app
volumes:
- type: bind
source: .
target: /app
networks:
cassandra:
ipv4_address: 172.16.0.4
depends_on:
cassandra-1:
condition: service_healthy
cassandra-2:
condition: service_healthy
networks:
cassandra:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.16.0.0/24
Dockerfile
FROM ubuntu:18.04
# cf. https://docs.datastax.com/en/developer/cpp-driver/2.16/topics/installation/
RUN apt-get update && \
apt-get install -y \
build-essential \
curl \
multiarch-support \
libkrb5-3 \
libssl1.1 \
zlib1g
RUN curl -O https://downloads.datastax.com/cpp-driver/ubuntu/18.04/cassandra/v2.16.0/cassandra-cpp-driver_2.16.0-1_amd64.deb && \
curl -O https://downloads.datastax.com/cpp-driver/ubuntu/18.04/cassandra/v2.16.0/cassandra-cpp-driver-dev_2.16.0-1_amd64.deb && \
curl -O https://downloads.datastax.com/cpp-driver/ubuntu/18.04/dependencies/libuv/v1.35.0/libuv1_1.35.0-1_amd64.deb && \
dpkg -i libuv1_1.35.0-1_amd64.deb && \
dpkg -i cassandra-cpp-driver_2.16.0-1_amd64.deb && \
dpkg -i cassandra-cpp-driver-dev_2.16.0-1_amd64.deb
main.c
#include <stdio.h>
#include <stdlib.h>
#include <cassandra.h>
int main(int argc, char* argv[]) {
CassCluster* cluster = cass_cluster_new();
cass_cluster_set_contact_points(cluster, "cassandra-1,cassandra-2");
CassError rc = CASS_OK;
CassSession* session = cass_session_new();
CassFuture* future = cass_session_connect(session, cluster);
cass_future_wait(future);
rc = cass_future_error_code(future);
if (rc != CASS_OK) {
fprintf(stderr, "failed to connect\n");
exit(1);
}
cass_future_free(future);
return 0;
}
次のようなログが出ます。
-- snip --
app_1 | 1648917845.145 [WARN] (host.cpp:155:void datastax::internal::core::Host::set(const datastax::internal::core::Row*, bool)): Found host with 'bind any' for rpc_address; using listen_address (172.16.0.3) to contact instead. If this is incorrect you should configure a specific interface for rpc_address on the server.
app_1 | 1648917845.174 [WARN] (host.cpp:155:void datastax::internal::core::Host::set(const datastax::internal::core::Row*, bool)): Found host with 'bind any' for rpc_address; using listen_address (172.16.0.2) to contact instead. If this is incorrect you should configure a specific interface for rpc_address on the server.
cassandra-1_1 | INFO [epollEventLoopGroup-2-6] 2022-04-02 16:44:05,284 Message.java:623 - Unexpected exception during request; channel = [id: 0x1145f794, L:/172.16.0.2:9042 - R:/172.16.0.4:60700]
cassandra-1_1 | io.netty.channel.unix.Errors$NativeIoException: syscall:read(...)() failed: Connection reset by peer
cassandra-1_1 | at io.netty.channel.unix.FileDescriptor.readAddress(...)(Unknown Source) ~[netty-all-4.0.44.Final.jar:4.0.44.Final]
cassandra_app_1 exited with code 0
原因調査
connect する時に接続が閉じられていることが原因っぽいということがわかったので、あとはブレークポイントを仕込んで地道にデバッグすれば良いだけです。自分の場合は CLion を使ってデバッグしました。
C/C++ driver は examples が豊富で、CMake options に -DCASS_BUILD_EXAMPLES=ON を付ければ CLion から手軽に試せて便利です。
とはいえ、C/C++ driver は callback だらけで地道にステップ実行してもなかなか骨の折れる作業だったので、TRACE ログを有効にしました。
cass_log_set_level(CASS_LOG_TRACE);
これで実行してみると、次のような怪しいログが出ました。
1648918232.789 [DEBUG] (socket.cpp:377:void datastax::internal::core::Socket::handle_close()): Socket(0x7f5e280047a0) to host 172.16.0.2 closed
1648918232.789 [DEBUG] (socket.cpp:377:void datastax::internal::core::Socket::handle_close()): Socket(0x7f5e28004510) to host 172.16.0.3 closed
この Socket::handle_close() にブレークポイントを仕込んで、どこから呼ばれているのかを調べてみてもたしかよくわからなかったんですが、Socket::close という、接続を閉じる際に確実に呼ばれているであろうメソッドを見つけたのでここにブレークポイントを仕込むと Connector::on_error から呼ばれていることがわかりました。
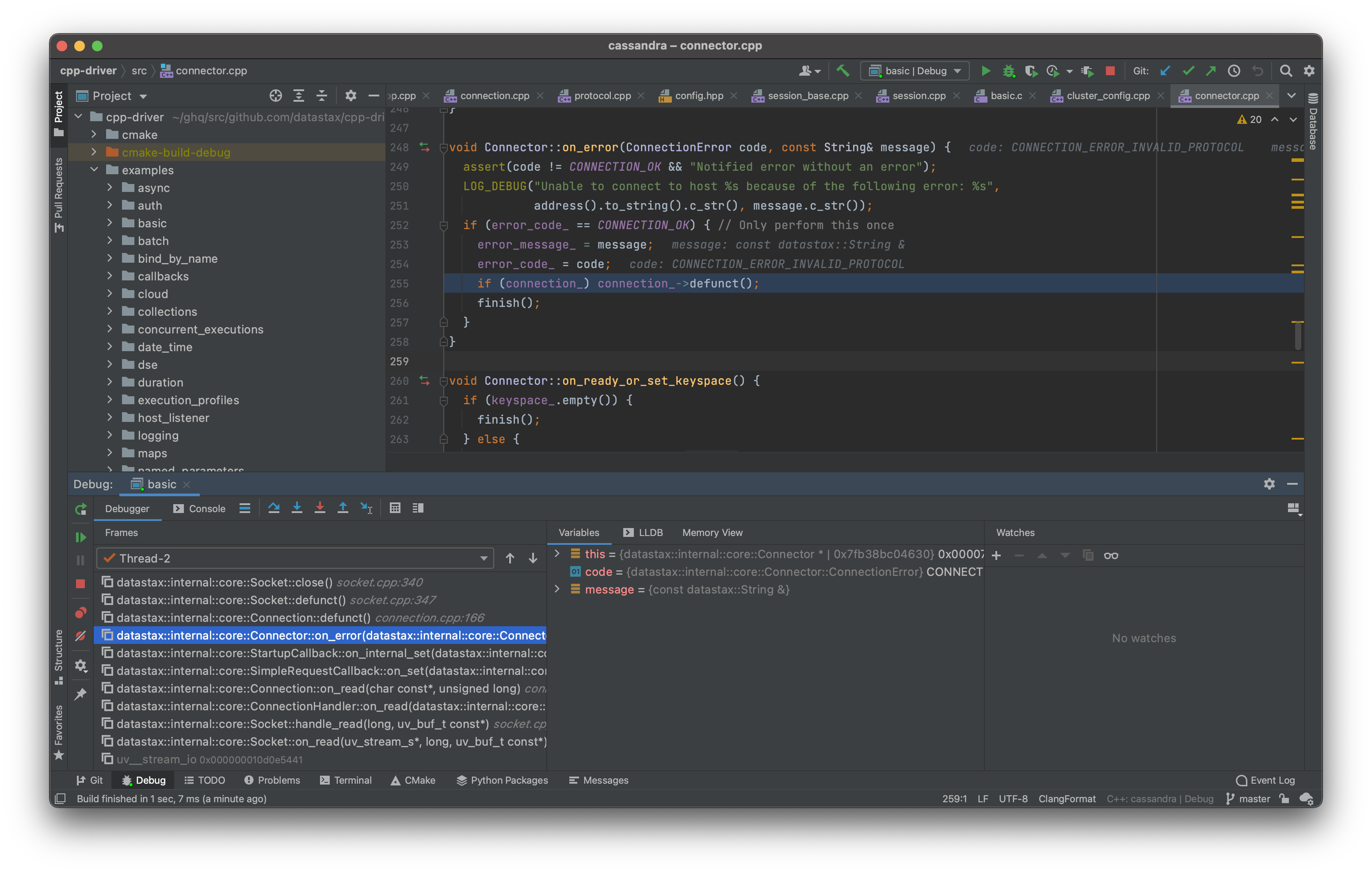
つまり、何かしらのエラーが原因で接続を閉じているということになります。このメソッドの中では “Unable to connect to host …” というログを出すようになっているので、それを調べてみました(Socket::handle_close() にブレークポイントを設定したのはログを有効にする前で、この時にようやく有効にした気もしてきた)
そうすると、次のように Invalid or unsupported protocol version (66) とありました。
1648918232.786 [TRACE] (connection.cpp:254:void datastax::internal::core::Connection::on_read(const char*, size_t)): Consumed message type CQL_OPCODE_ERROR with stream 0, input 107, remaining 107 on host 172.16.0.3
1648918232.786 [DEBUG] (connector.cpp:251:void datastax::internal::core::Connector::on_error(datastax::internal::core::Connector::ConnectionError, const String&)): Unable to connect to host 172.16.0.3 because of the following error: Received error response 'Invalid or unsupported protocol version (66); supported versions are (3/v3, 4/v4, 5/v5-beta)' (0x0200000A)
1648918232.788 [INFO] (cluster_connector.cpp:290:void datastax::internal::core::ClusterConnector::on_connect(datastax::internal::core::ControlConnector*)): Host 172.16.0.3 does not support protocol version DSEv2. Trying protocol version DSEv1...
1648918232.789 [TRACE] (connection.cpp:254:void datastax::internal::core::Connection::on_read(const char*, size_t)): Consumed message type CQL_OPCODE_ERROR with stream 0, input 107, remaining 107 on host 172.16.0.2
1648918232.789 [DEBUG] (connector.cpp:251:void datastax::internal::core::Connector::on_error(datastax::internal::core::Connector::ConnectionError, const String&)): Unable to connect to host 172.16.0.2 because of the following error: Received error response 'Invalid or unsupported protocol version (66); supported versions are (3/v3, 4/v4, 5/v5-beta)' (0x0200000A)
1648918232.789 [INFO] (cluster_connector.cpp:290:void datastax::internal::core::ClusterConnector::on_connect(datastax::internal::core::ControlConnector*)): Host 172.16.0.2 does not support protocol version DSEv2. Trying protocol version DSEv1...
1648918232.789 [DEBUG] (socket.cpp:377:void datastax::internal::core::Socket::handle_close()): Socket(0x7f5e280047a0) to host 172.16.0.2 closed
1648918232.789 [DEBUG] (socket.cpp:377:void datastax::internal::core::Socket::handle_close()): Socket(0x7f5e28004510) to host 172.16.0.3 closed
66、つまり 0x42 で grep してみると、CASS_PROTOCOL_VERSION_DSEV2 という enum の要素が見つかったので、これを使っている箇所が怪しいということになります。これを使っているのは ProtocolVersion::highest_supported で、Config の protocol version の初期値として CASS_PROTOCOL_VERSION_DSEV2 が使われているのがわかります。よって、これを CASS_PROTOCOL_VERSION_V4 に変更すれば良さそうです。
というわけで、main.c を次のように変更すれば解消すると思うじゃないですか。
#include <stdio.h>
#include <stdlib.h>
#include <cassandra.h>
int main(int argc, char* argv[]) {
CassCluster* cluster = cass_cluster_new();
cass_cluster_set_contact_points(cluster, "cassandra-1,cassandra-2");
cass_cluster_set_protocol_version(cluster, CASS_PROTOCOL_VERSION_V4);
CassError rc = CASS_OK;
CassSession* session = cass_session_new();
CassFuture* future = cass_session_connect(session, cluster);
cass_future_wait(future);
rc = cass_future_error_code(future);
if (rc != CASS_OK) {
fprintf(stderr, "failed to connect\n");
exit(1);
}
cass_future_free(future);
return 0;
}
ところが Connection reset by peer は出続けるわけですよ。原因不明すぎるので CLion から 2 台の Cassandra に接続できるように次のような docker-compose.yml でクラスタを起動します。
version: "3.8"
services:
cassandra-1:
image: cassandra:3.11.3
ports:
# ifconfig lo0 alias 172.16.0.2 (To delete the alias: ifconfig lo0 -alias 172.16.0.2)
- 172.16.0.2:9042:9042
networks:
cassandra:
ipv4_address: 172.16.0.2
environment:
CASSANDRA_SEEDS: 172.16.0.2,172.16.0.3
MAX_HEAP_SIZE: 400M
HEAP_NEWSIZE: 100M
healthcheck:
test: ["CMD", "cqlsh", "-e", "quit"]
interval: 5s
timeout: 5s
retries: 60
cassandra-2:
image: cassandra:3.11.3
networks:
cassandra:
ipv4_address: 172.16.0.3
ports:
# ifconfig lo0 alias 172.16.0.3 (To delete the alias: ifconfig lo0 -alias 172.16.0.3)
- 172.16.0.3:9042:9042
environment:
CASSANDRA_SEEDS: 172.16.0.2,172.16.0.3
MAX_HEAP_SIZE: 400M
HEAP_NEWSIZE: 100M
healthcheck:
test: ["CMD", "cqlsh", "-e", "quit"]
interval: 5s
timeout: 5s
retries: 60
networks:
cassandra:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.16.0.0/24
コメントにも書いてありますが、事前に ifconfig を使って 172.16.0.2 などを loopback interface に紐付けておく必要があります。Cassandra driver は最初の contact points のノードからクラスタの情報を得て、その情報に含まれる IP アドレスに対してリクエストするので、CLion から Cassandra ノードの IP アドレスにアクセスできるようにする必要があります。もっと上手い方法があるかもしれないですが、これでアクセスできるようになります。
これで main.c と同様のコード(examples の basic を少し修正したもの)を実行してみると、試行錯誤の際にたまたまブレークポイントを設定していた TcpConnector::cancel() で止まって、呼び出し元を確認してみると次の箇所にたどり着きました。
cluster_connector.cpp#L268-L274
The cluster is initialized so the rest of the connectors can be canceled.
仕様かい!!!!
この commit で contact points に一斉にリクエストし、最初にレスポンスが返ってきたもの以外はキャンセルするようにしたと書かれていますね。詳細は追ってないですが、次のようなことが起こるんじゃないかと思います。
- client が最初に contact points に対してクラスタのメタデータをリクエストする
- client は最初にレスポンスが返ってきたノード以外は接続を閉じる(FIN パケットを送る)
- server は全てのリクエストに対して返答しようとするが、既に CLOSE-WAIT になっていて、その接続に対してレスポンスを返すから RST パケットが返ってきて CLOSED になる
- server は CLOSED になっていることも知らず次のリクエスト(client からのコマンド)を処理するためにデータを読み取ろうとする
- Connection reset by peer
そんなわけで、Connection reset by peer を避けつつ contact points を複数指定したい場合は次のようにシーケンシャルに試す必要がありそうです。
#include <stdio.h>
#include <stdlib.h>
#include <cassandra.h>
#define CONTACT_POINT_COUNT 2
int main(int argc, char* argv[]) {
CassCluster* cluster = cass_cluster_new();
char* contact_points[CONTACT_POINT_COUNT] = { "cassandra-1", "cassandra-2" };
CassSession* session;
cass_cluster_set_protocol_version(cluster, CASS_PROTOCOL_VERSION_V4);
for (int i = 0; i < CONTACT_POINT_COUNT; ++i) {
cass_cluster_set_contact_points(cluster, contact_points[i]);
CassError rc = CASS_OK;
session = cass_session_new();
CassFuture* future = cass_session_connect(session, cluster);
cass_future_wait(future);
rc = cass_future_error_code(future);
cass_future_free(future);
if (rc == CASS_OK) {
break;
} else {
fprintf(stderr, "failed to connect\n");
cass_session_free(session);
if (i == CONTACT_POINT_COUNT - 1) {
exit(1);
}
}
}
return 0;
}
上記の変更によって Connection reset by peer のログが出なくなることを確認できました。
まとめ
- Connection reset by peer は Cassandra client が接続を閉じる出るログで、多くの場合 client の実装に問題がある
- Cassandra の Connection reset by peer のログレベルは現在 TRACE になっているので、再現できる環境は限られている
- Cassandra C/C++ driver では contact points が 2 つ以上あると最初にレスポンスが返ってきたもの以外の接続を閉じる仕様になっているので Connection reset by peer が出るのは仕方がない
- どうしても Connection reset by peer が出るのが気になるのであれば、contact points を 1 つだけ指定し、接続に失敗したら別のノードに接続を試みるよう自前でリトライするしかない