Amazon Elastic MapReduce (EMR) ではじめる Presto/Trino 入門

Presto/Trino 1は日本語の入門書がなく、「Presto/Trino を運用することになったけど何から勉強すれば良いかわからない><」という人も多いのではないかと思います。そこで、Presto/Trino を運用する時にこの辺の内容を知っていれば、よりスムーズにキャッチアップできたかなぁと思うことをまとめてみました。
Hive connector を使いたいので、Hive と Presto の環境構築をサクッと行える Amazon Elastic MapReduce (以降 EMR) で実際に手を動かせればと思います。
以降 Presto/Trino ではなく Presto と表記しますが、Trino は元々同じソフトウェアであるため、Trino でも当てはまる内容がほとんどのはずです。
なお、Presto のバージョンは 2019-03-13 時点で最新の EMR 5.21.0 でインストールされる Presto 0.215 を前提とします。また、AWS のリージョンとして ap-northeast-1 を使用する前提とするので、他のリージョンを使う方は適宜リージョンを変更してください。
このエントリーで EMR はサクッと Hive と Presto が動く環境を用意するぐらいの目的でしか使いませんが、EMR の特徴について知りたい方は岩永さんのスライドが非常にわかりやすいと思います。
アジェンダ
Presto とは
Presto にはざっくりと次のような特徴があると思います。
- 分散 SQL クエリエンジン
- ANSI SQL に準拠
- worker の台数を増やせばスループットも比例して上がる2
- データストレージとしての機能は持たない
- 様々なデータソースを扱える
- Hive テーブルのデータ(Hadoop のファイルシステムのデータ)と MySQL のデータを結合するなんてこともできる
- MySQL 5.6 以下に対して JSON をパースして集計処理するなんてこともできる
- 基本的にオンメモリで処理する
- Hive on Tez とかと比べると速い(よく引き合いに出される Spark SQL と比べても速いらしい 3)
- メモリに収まらないデータは処理できない
- 開発が活発
- 月に 2 回ぐらいリリースがある
- ドキュメントに載っていない、または詳細が書かれていないけどパフォーマンスチューニングに重要な設定がある
hive.bucket_execution_enabledとか- ソースコードを読めないと厳しい
Getting Started
Presto についてざっくり説明したところで、早速触ってみましょう。EMR の Getting Started で使われているデータを Hive と同じように Presto で処理してみます。
事前準備
次のコマンドで EMR クラスタを起動します。あまりお金をかけたくないので m4.large のスポットインスタンスを使用するようにしています。--ec2-attributes は適当なものに置き換えてください。
aws emr create-cluster \
--name emr-test \
--release-label emr-5.21.0 \
--use-default-roles \
--applications Name=Hadoop Name=Hive Name=Tez Name=Presto \
--ec2-attributes KeyName=<key-name>,SubnetId=<subnet-id> \
--instance-groups InstanceGroupType=MASTER,InstanceType=m4.large,InstanceCount=1,BidPrice=0.05 \
InstanceGroupType=CORE,InstanceType=m4.large,InstanceCount=2,BidPrice=0.05
上記のコマンドを実行すると ClusterID が表示されるので、以降ではこの値が $CLUSTER_ID にセットされているものとします。
CLUSTER_ID=j-24LD5R05E7X6B
また、EMR_MASTER_IP に master ノードの IP アドレスをセットしておきます。次のコマンドはインスタンスが起動していない状態で実行すると空文字列を返すので注意してください。
EMR_MASTER_IP=$(aws ec2 describe-instances \
--filters "Name=tag:aws:elasticmapreduce:job-flow-id,Values=$CLUSTER_ID" \
"Name=tag:aws:elasticmapreduce:instance-group-role,Values=MASTER" \
--query 'Reservations[*].Instances[*].[PublicIpAddress]' \
--output text
)
クラスタが起動したら Hive テーブルを作成します。
まず、master ノードにログインします。
ssh -l hadoop $EMR_MASTER_IP
次に、以下のコマンドを実行してテーブルを作成します。
hive -e '
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
DateObject Date,
Time STRING,
Location STRING,
Bytes INT,
RequestIP STRING,
Method STRING,
Host STRING,
Uri STRING,
Status INT,
Referrer STRING,
OS String,
Browser String,
BrowserVersion String
)
ROW FORMAT SERDE "org.apache.hadoop.hive.serde2.RegexSerDe"
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$"
) LOCATION "s3://ap-northeast-1.elasticmapreduce.samples/cloudfront/data";
'
これによって Hive の metastore にテーブルの情報が保存されます。Presto の Hive connector はこの metastore から Hive テーブルのパーティション情報等を取得します。
HiveQL を実行して所望の結果が得られるか確認してみます。
hive -e "
SELECT
os,
COUNT(*) count
FROM
cloudfront_logs
WHERE
dateobject BETWEEN '2014-07-05' AND '2014-08-05'
GROUP BY
os
;
"
上記のコマンドを実行すると次のような出力が得られるはずです。
Android 855
Linux 813
MacOS 852
OSX 799
Windows 883
iOS 794
以上で事前準備完了です。
presto-cli の利用
presto-cli を使用することでインタラクティブに SQL を投げることができます。
先程実行した HiveQL 相当の Presto SQL は次のように書けます。
SELECT
os,
COUNT(*) count
FROM
hive.default.cloudfront_logs
WHERE
dateobject BETWEEN DATE '2014-07-05' AND DATE '2014-08-05'
GROUP BY
os
;
これを presto-cli から実行してみます。
[hadoop@ip-172-31-5-125 ~]$ presto-cli
presto> SELECT
-> os,
-> COUNT(*) count
-> FROM
-> hive.default.cloudfront_logs
-> WHERE
-> dateobject BETWEEN DATE '2014-07-05' AND DATE '2014-08-05'
-> GROUP BY
-> os
-> ;
os | count
---------+-------
OSX | 799
Windows | 883
Android | 855
iOS | 794
MacOS | 852
Linux | 813
(6 rows)
Query 20190312_133351_00001_uxfsg, FINISHED, 2 nodes
Splits: 86 total, 86 done (100.00%)
0:15 [5K rows, 993KB] [324 rows/s, 64.5KB/s]
Hive と同様の結果が得られましたね。
後述しますが、Presto は catalog, schema, table という概念があり、完全修飾名は <catalog>.<schema>.<table> で表されます。事前準備で作成したテーブルの完全修飾名は hive.default.cloudfront_logs です。
Web UI の利用
EMR の場合は master node の 8889 番ポートにアクセスすると Presto の Web UI が表示されます。
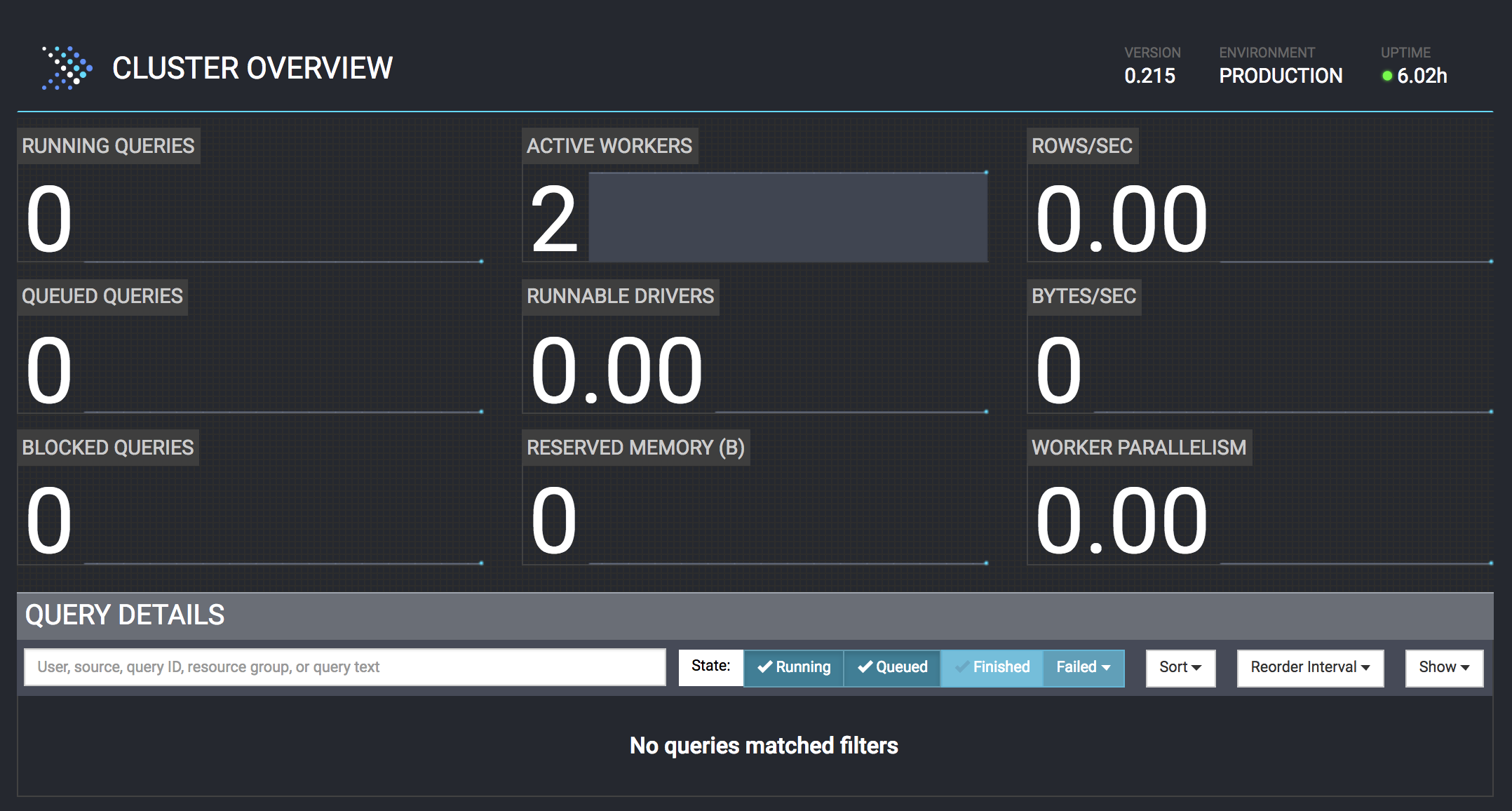
このページからクエリの実行状況や統計情報を確認したり、kill したりすることができます。
手っ取り早く Web UI にアクセスするには、次のようにポートフォワーディングして、http://localhost:8889 にアクセスすると良いでしょう。
ssh -l hadoop -fNL 8889:localhost:8889 $EMR_MASTER_IP
Presto クライアントの利用
例えば Ruby からは presto-client を使うことで手軽に SQL を投げて結果を取得することができます。
presto-cli で実行した SQL と同じ結果を得るためのコードは次のようになります。
require 'presto-client'
# 次のコマンドでポートフォワーディングしている前提
# ssh -l hadoop -fNL 8889:localhost:8889 $EMR_MASTER_IP
client = Presto::Client.new(server: 'localhost:8889', user: 'arabiki')
query = client.query(<<~SQL)
SELECT
os,
COUNT(*) count
FROM
hive.default.cloudfront_logs
WHERE
dateobject BETWEEN DATE '2014-07-05' AND DATE '2014-08-05'
GROUP BY
os
SQL
query.each_row do |row|
p row
end
ポートフォワーディングした状態で上記のコードを実行すると次のような出力が得られます。
["Linux", 813]
["Windows", 883]
["OSX", 799]
["iOS", 794]
["MacOS", 852]
["Android", 855]
Presto の構成要素
Presto でよく使われる用語を押さえておくと Presto がどのように動いているかイメージしやすくなるので、Presto のドキュメントの 1.2. Presto Concepts に沿って簡単に説明していきます。
Server Types
Presto のサーバは coordinator と worker の大きく 2 種類あります。
Coordinator
主に次の 2 つの役割を担います。
- クライアントからリクエストを受け付けて worker にタスクを投げる
- worker の管理 (discovery server)
EMR では master node が coordinator になるように設定されています。
[hadoop@ip-172-31-5-125 ~]$ instance_id=$(curl -s http://169.254.169.254/latest/meta-data/instance-id)
[hadoop@ip-172-31-5-125 ~]$ aws ec2 describe-tags --filter Name=resource-id,Values=$instance_id --output text
TAGS aws:elasticmapreduce:instance-group-role i-0325e92290f8d20d4 instance MASTER
TAGS aws:elasticmapreduce:job-flow-id i-0325e92290f8d20d4 instance j-24LD5R05E7X6B
[hadoop@ip-172-31-5-125 ~]$ grep coordinator /etc/presto/conf/config.properties
coordinator=true
node-scheduler.include-coordinator=false
クライアントからのリクエストを受け付けて worker にタスクを投げるまでに次のようなことを 1 node で行うため、SQL やデータの性質によっては CPU にかなりの負荷がかかります。
- ステートメント (SQL) のパース
- クエリの最適化
- クエリの実行計画の作成
- タスクの配分の決定
CPU に余裕がないと突然死することがあるので、それなりに良いインスタンスを用意した方が良いです。
Worker
coordinator から割り当てられたタスクを処理します。各データソースからデータを取得したり、中間データを他の worker とやり取りしつつ、最終結果を 1 つの worker に集約します。集約したデータは coordinator 経由でクライアントに返します。
EMR では core node と task node が worker になるように設定されています。
Data Sources
データソースに関連する概念として次のような概念があります。
| 概念 | 概要 |
|---|---|
| Connector | データソースにアクセスするためのプラグイン。catalog を登録する際に指定する。 |
| Catalog | データソースの登録名。 |
| Schema | テーブルの名前空間的なもの。connector の実装によるが MySQL connector の場合はデータベースに相当する。 |
| Table | いわゆるテーブル。 |

Getting Started で使用した Hive テーブルの完全修飾名は hive.default.cloudfront_logs でしたが、それは EMR の設定で Hive connector (hive-hadoop2 プラグイン) を使う catalog が hive という名前で登録されているからです。
[hadoop@ip-172-31-5-125 ~]$ grep connector.name /etc/presto/conf/catalog/hive.properties
connector.name=hive-hadoop2
/etc/presto/conf/catalog/ 以下のファイル名から .properties を除いたものが catalog 名になります。
別のクラスタの Hive テーブルにアクセスしたい場合は別名で catalog を指定することで実現できます。4
Query Execution Model
クエリの実行モデルに関連する概念として次のような概念があります。
| 概念 | 概要 |
|---|---|
| Statement | いわゆる SQL。 |
| Query | 1 つの SQL を実行するための設定やコンポーネントをまとめたもの。 |
| Stage | 他の worker とデータをやり取りせずに行える処理の単位。最終結果をまとめるための root stage (stage 0)、データソースから直接データを取得して処理する stage、中間データを処理する stage が存在する。 |
| Task | 各 stage における各 wokrer の処理。複数の driver を並行して動かすことでデータを処理する。 |
| Split | 各 stage の入力データを分割したデータ。例えば S3 オブジェクトの split (HiveSplit) であれば処理対象の path, start (offset), length などの情報によって分割する。 |
| Driver | 1 つの split に対して、属する stage で必要な operation を実行する(operator を適用する)コンポーネント。 |
| Operator | データに対する処理。フィルター処理や集約処理などがある。 |
| Exchange | stage 間で異なる worker にデータを転送すること。 |

Presto の実行フロー
Presto の実行フローについては古橋さんのスライドの 4 枚目から 27 枚目までに非常に良くまとまっているので、こちらを参照してください。
デバッグ方法
Presto を運用していると、EMR のインスタンス上で動いている presto server をデバッグする必要が出てくることもあります。ここでは代表的なデバッグ方法と思われるデバッグログの有効化(ログレベルの変更)、リモートデバッグ、Web UI の利用について紹介します。
なお、EMR の全インスタンスにログインして行う作業がありますが、拙作の tmux-multi-ssh を使うと、次のコマンドでクラスタの全インスタンスにログインして同じコマンドをインタラクティブに実行することができます。
tmux-multi-ssh --ssh-option '-l hadoop' --col 2 $(
aws ec2 describe-instances \
--filters "Name=tag:aws:elasticmapreduce:job-flow-id,Values=$CLUSTER_ID" \
--query 'Reservations[*].Instances[*].[PublicIpAddress]' \
--output text
)
デバッグログの有効化
EMR のインスタンスでデバッグログを有効化するには、各インスタンスで次のコマンドを実行します。
sudo sed -i 's/INFO/DEBUG/' /etc/presto/conf/log.properties
sudo restart presto-server
デバッグログを有効にすると、worker に次のようなログが出るので、その worker が処理した split の詳細を知ることができます。
2019-03-12T18:45:29.215Z DEBUG 20190312_184513_00009_uxfsg.2.1-1-46 com.facebook.presto.execution.executor.TaskExecutor Split 20190312_184513_00009_uxfsg.2.1-1 {path=s3://ap-northeast-1.elasticmapreduce.samples/cloudfront/data/log3, start=0, length=101270, fileSize=101270, hosts=[*], database=default, table=cloudfront_logs, forceLocalScheduling=false, partitionName=<UNPARTITIONED>, s3SelectPushdownEnabled=false} (start = 2.0400363354646E7, wall = 11595 ms, cpu = 3606 ms, wait = 14 ms, calls = 9) is finished
2019-03-12T18:45:34.419Z DEBUG 20190312_184513_00009_uxfsg.2.1-2-48 com.facebook.presto.execution.executor.TaskExecutor Split 20190312_184513_00009_uxfsg.2.1-2 {path=s3://ap-northeast-1.elasticmapreduce.samples/cloudfront/data/log5, start=0, length=203642, fileSize=203642, hosts=[*], database=default, table=cloudfront_logs, forceLocalScheduling=false, partitionName=<UNPARTITIONED>, s3SelectPushdownEnabled=false} (start = 2.040036392307E7, wall = 16798 ms, cpu = 6720 ms, wait = 8 ms, calls = 14) is finished
2019-03-12T18:45:34.624Z DEBUG 20190312_184513_00009_uxfsg.2.1-0-47 com.facebook.presto.execution.executor.TaskExecutor Split 20190312_184513_00009_uxfsg.2.1-0 {path=s3://ap-northeast-1.elasticmapreduce.samples/cloudfront/data/log2, start=0, length=203435, fileSize=203435, hosts=[*], database=default, table=cloudfront_logs, forceLocalScheduling=false, partitionName=<UNPARTITIONED>, s3SelectPushdownEnabled=false} (start = 2.0400354563597E7, wall = 17012 ms, cpu = 8296 ms, wait = 13 ms, calls = 14) is finished
MySQL connector 等、JDBC connector を利用している connector は発行される SQL が表示されるので、データソースに対して発行される SQL が想像しにくい場合にデバッグログを有効にすると便利です。
cf. JdbcRecordCursor.java#L91
上記の方法ではログレベルを変更するのに presto server の再起動が必要でしたが、JMX を利用すれば JConsole や VisualVM 等の JMX クライアント経由で再起動なしに変更することができます。
まず、JMX エージェントに外部から接続できるように、次のコマンドを EMR インスタンスで実行します。
echo -Dcom.sun.management.jmxremote.port=9999 | sudo tee -a /etc/presto/conf/jvm.config
echo -Dcom.sun.management.jmxremote.authenticate=false | sudo tee -a /etc/presto/conf/jvm.config
echo -Dcom.sun.management.jmxremote.ssl=false | sudo tee -a /etc/presto/conf/jvm.config
sudo restart presto-server
JConsole から master node に接続するには次のコマンドを実行します。master node 以外も IP アドレスを変えれば同様に接続可能です。
ssh -l hadoop -fND 1080 $EMR_MASTER_IP
jconsole -J-DsocksProxyHost=localhost -J-DsocksProxyPort=1080 service:jmx:rmi:///jndi/rmi://localhost:9999/jmxrmi -J-DsocksNonProxyHosts=
上記のコマンドを実行すると JConsole が起動するので、MBeans タブの io.airlift.log > Logging > Operations で setLevel(com.facebook.presto, DEBUG) を実行すればログレベルが変わります。5
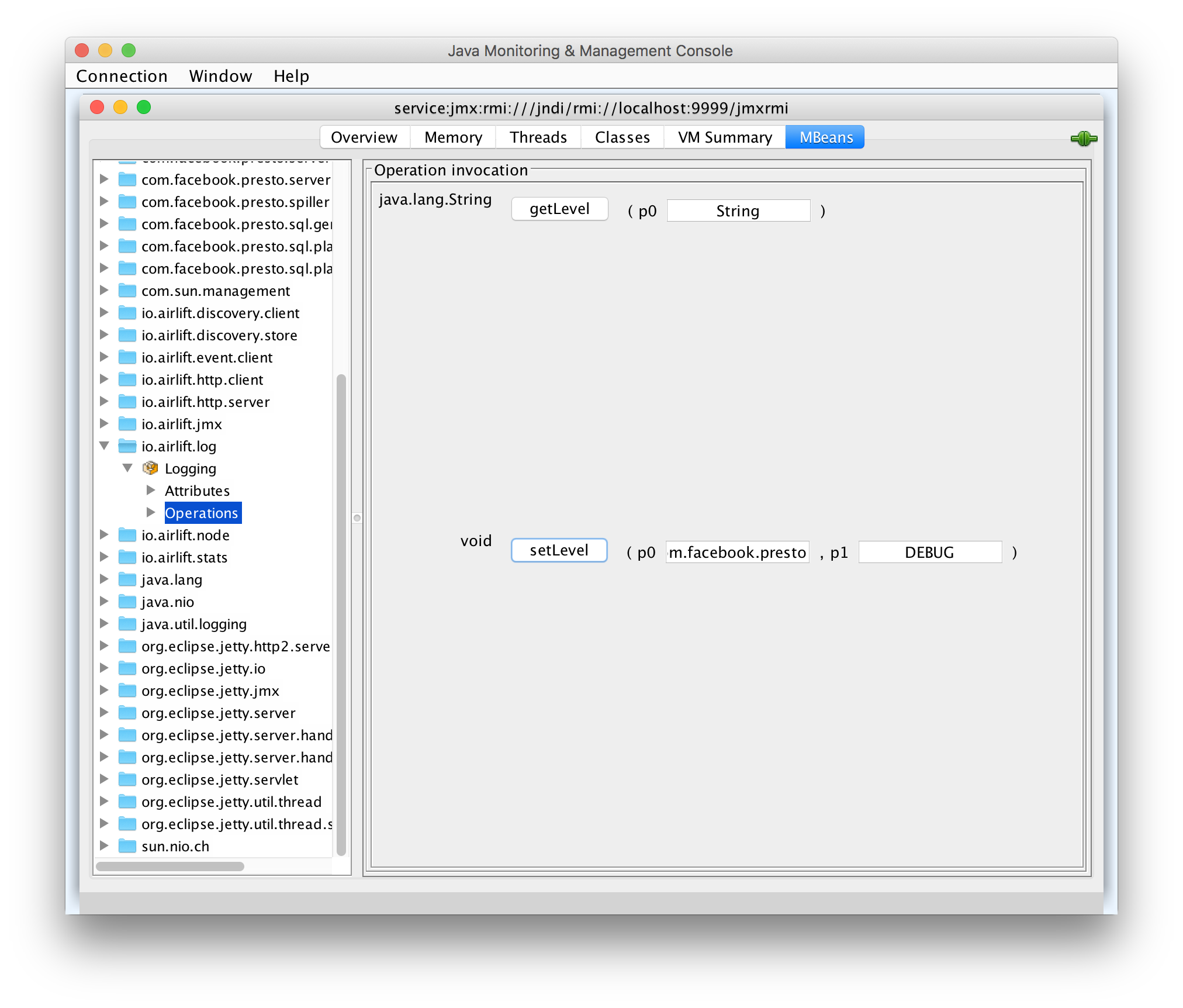
もし接続に成功してもすぐに “Connection Lost: Reconnect?” となる場合は Java のバージョンを変えると解決するかもしれません。
cf. https://stackoverflow.com/questions/64090365/jconsole-remote-connection-lost-reconnect
jmxterm を使えば SOCKS proxy server を起動せずに、サーバにログインした状態で作業を行うことができます。
$ curl -sLO https://github.com/jiaqi/jmxterm/releases/download/v1.0.0/jmxterm-1.0.0-uber.jar
$ java -jar jmxterm-1.0.0-uber.jar
Welcome to JMX terminal. Type "help" for available commands.
$>open localhost:9999
#Connection to localhost:9999 is opened
$>domains
#following domains are available
JMImplementation
com.facebook.presto.execution
com.facebook.presto.execution.executor
com.facebook.presto.execution.resourceGroups
com.facebook.presto.execution.scheduler
com.facebook.presto.failureDetector
com.facebook.presto.hive
com.facebook.presto.hive.metastore
com.facebook.presto.hive.metastore.thrift
com.facebook.presto.memory
com.facebook.presto.metadata
com.facebook.presto.operator.index
com.facebook.presto.security
com.facebook.presto.server
com.facebook.presto.server.remotetask
com.facebook.presto.spiller
com.facebook.presto.sql.gen
com.facebook.presto.sql.planner.iterative
com.facebook.presto.sql.planner.optimizations
com.sun.management
io.airlift.discovery.client
io.airlift.discovery.store
io.airlift.event.client
io.airlift.http.client
io.airlift.http.server
io.airlift.jmx
io.airlift.log
io.airlift.node
io.airlift.stats
java.lang
java.nio
java.util.logging
jdk.management.jfr
org.eclipse.jetty.http2.server
org.eclipse.jetty.io
org.eclipse.jetty.jmx
org.eclipse.jetty.server
org.eclipse.jetty.server.handler
org.eclipse.jetty.server.handler.gzip
org.eclipse.jetty.servlet
org.eclipse.jetty.util.thread
org.eclipse.jetty.util.thread.strategy
sun.nio.ch
$>beans -d io.airlift.log
#domain = io.airlift.log:
io.airlift.log:name=Logging
$>info -d io.airlift.log -b name=Logging
#mbean = io.airlift.log:name=Logging
#class name = io.airlift.log.LoggingMBean
# attributes
%0 - AllLevels (java.util.Map, r)
%1 - RootLevel (java.lang.String, rw)
# operations
%0 - java.lang.String getLevel(java.lang.String p0)
%1 - void setLevel(java.lang.String p0,java.lang.String p1)
#there's no notifications
$>run -d io.airlift.log -b name=Logging getLevel com.facebook.presto
#calling operation getLevel of mbean io.airlift.log:name=Logging with params [com.facebook.presto]
#operation returns:
INFO
$>run -d io.airlift.log -b name=Logging setLevel com.facebook.presto DEBUG
#calling operation setLevel of mbean io.airlift.log:name=Logging with params [com.facebook.presto, DEBUG]
#operation returns:
null
$>run -d io.airlift.log -b name=Logging getLevel com.facebook.presto
#calling operation getLevel of mbean io.airlift.log:name=Logging with params [com.facebook.presto]
#operation returns:
DEBUG
なお、jmxterm の使い方については help コマンドを使うことで調べることができます。
$>help
#following commands are available to use:
about - Display about page
bean - Display or set current selected MBean.
beans - List available beans under a domain or all domains
bye - Terminate console and exit
close - Close current JMX connection
domain - Display or set current selected domain.
domains - List all available domain names
exit - Terminate console and exit
get - Get value of MBean attribute(s)
help - Display available commands or usage of a command
info - Display detail information about an MBean
jvms - List all running local JVM processes
open - Open JMX session or display current connection
option - Set options for command session
quit - Terminate console and exit
run - Invoke an MBean operation
set - Set value of an MBean attribute
subscribe - Subscribe to the notifications of a bean
unsubscribe - Unsubscribe the notifications of an earlier subscribed bean
watch - Watch the value of one MBean attribute constantly
$>help domains
[USAGE]
domains <OPTIONS>
[DESCRIPTION]
List all available domain names
[OPTIONS]
-h --help Display usage
$>help beans
[USAGE]
beans <OPTIONS>
[DESCRIPTION]
List available beans under a domain or all domains
[OPTIONS]
-d --domain <domain> Name of domain under which beans are listed
-h --help Display usage
[NOTE]
Without -d option, current select domain is applied. If there's no domain specified, all beans are listed. Example:
beans
beans -d java.lang
$>help run
[USAGE]
run <OPTIONS> <ARGS>
[DESCRIPTION]
Invoke an MBean operation
[OPTIONS]
-b --bean <value> MBean to invoke
-d --domain <value> Domain of MBean to invoke
-h --help Display usage
-m --measure Measure the time spent on the invocation of operation
-q --quots Flag for quotation marks
-t --types <value> Require parameters to have specific types (comma separated)
[ARGS]
<arg>... The first parameter is operation name, which is followed by list of arguments
[NOTE]
Syntax is
run <operationName> [parameter1] [parameter2]
リモートデバッグ
Presto の挙動をより詳細に理解したい場合はリモートデバッグするのが手っ取り早いです。
Presto が IntelliJ IDEA を使用することを推奨しているので、IntelliJ IDEA の Community Edition 2018.3 を使用してリモートデバッグすることにします。
IntelliJ IDEA がインストールされていない場合は https://www.jetbrains.com/idea/download/ からダウンロードしてください。
まず、README に書かれているとおりの手順で Presto をビルドします。
git clone git@github.com:prestodb/presto.git
cd presto
git checkout 0.215
./mvnw clean install -DskipTests
ビルド(インストール)に成功したら IntelliJ で pom.xml を開きます。macOS で開くなら次のコマンドです。
open -a 'IntelliJ IDEA CE' pom.xml
起動したら Run > Edit Configurations から Remote の設定を追加します。
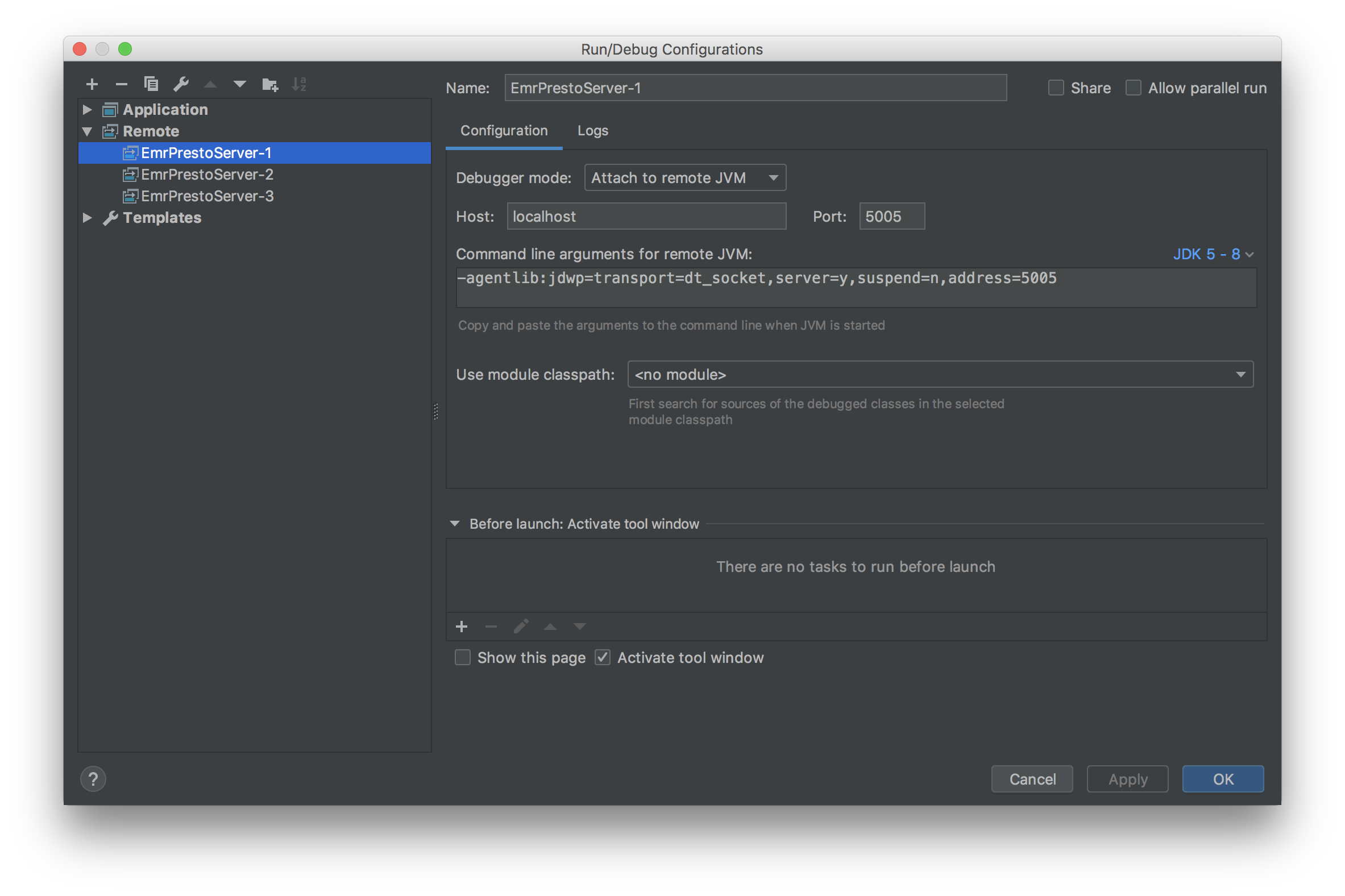
インスタンスの数だけポート番号をずらして設定を作成します。上記のスクリーンショットでは次のような設定にしています。
| Name | Port |
|---|---|
| EmrPrestoServer-1 | 5005 |
| EmrPrestoServer-2 | 5006 |
| EmrPrestoServer-3 | 5007 |
あとは次のコマンドを EMR の全インスタンスで実行して presto-server プロセスにアタッチできるようにします。
echo -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005 | sudo tee -a /etc/presto/conf/jvm.config
sudo restart presto-server
これだけだとローカルホストからはアクセスできないので、ローカルホストの 5005 番ポートから 5007 番ポートを各 EMR インスタンスの 5005 番ポートに転送するようにします。
ips=($(aws ec2 describe-instances \
--filters "Name=tag:aws:elasticmapreduce:job-flow-id,Values=$CLUSTER_ID" \
--query 'Reservations[*].Instances[*].[PrivateIpAddress]' \
--output text
))
for ((i = 0; i < ${#ips[@]}; i++)); do
ssh -l hadoop -fNL $((5005 + $i)):${ips[@]:$i:1}:5005 $EMR_MASTER_IP
done
これで IntelliJ から接続できるようになりました。
試しに SqlQueryExecution#start の最初の行にブレークポイントを設定して SQL を投げてみます。
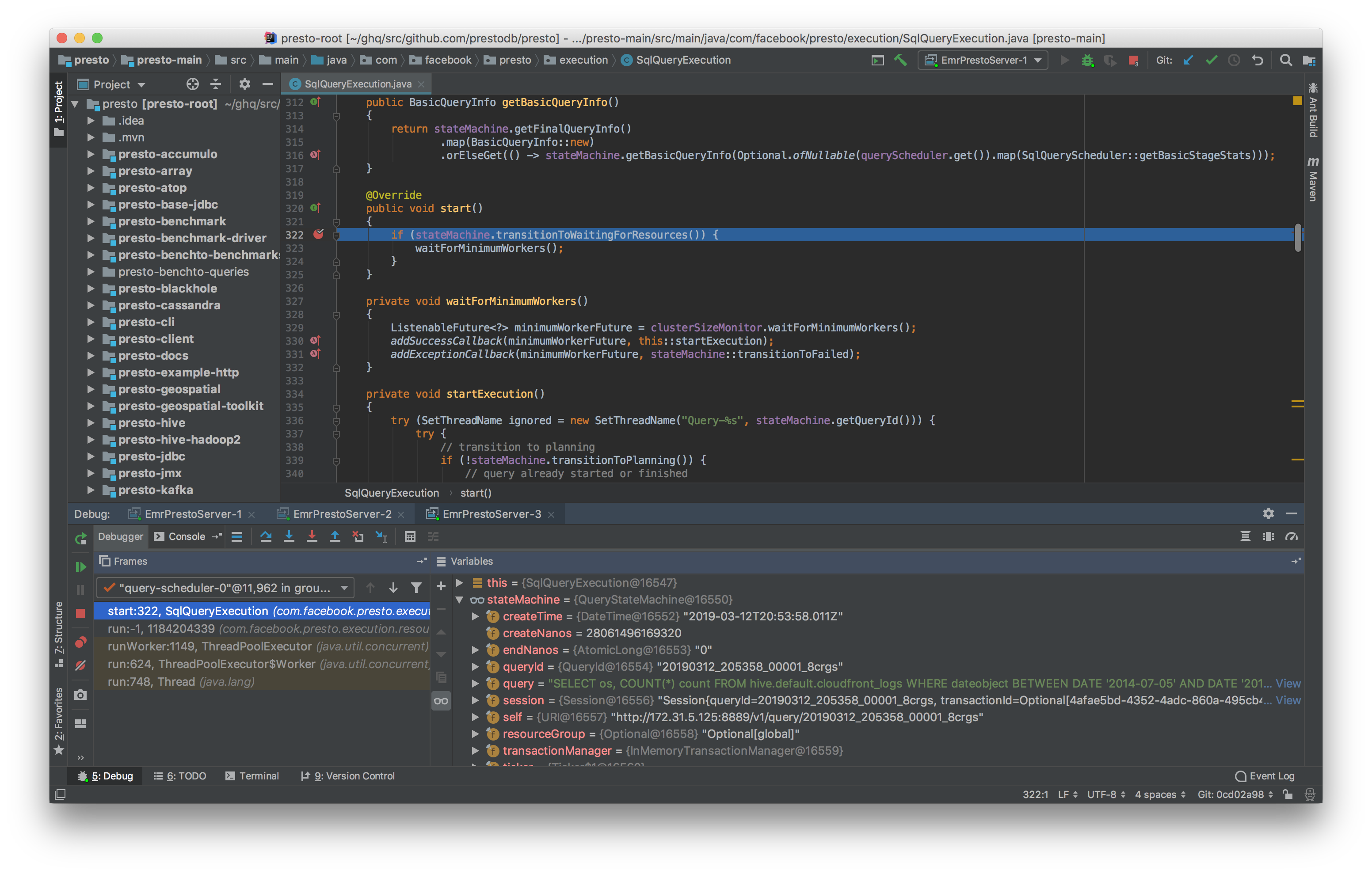
ちゃんと指定した場所で止まってますね!SqlQueryExecution#start は coordinator が query を処理する時のエントリーポイントみたいなものなので、ここを起点に読むと coorinator が query を処理する時にどのようなことをしているかの雰囲気が掴めます。
Web UI を使ったデバッグ
デバッグかと言うと微妙ですが、Web UI からはパフォーマンスチューニング等を行う上でかなり有益な情報を得ることができます。
試しに、Getting Started の SQL を実行した時の情報を見てみましょう。
Web UI でクエリの詳細を確認すると、Overview タブの Tasks のセクションには次のような情報が表示されます。
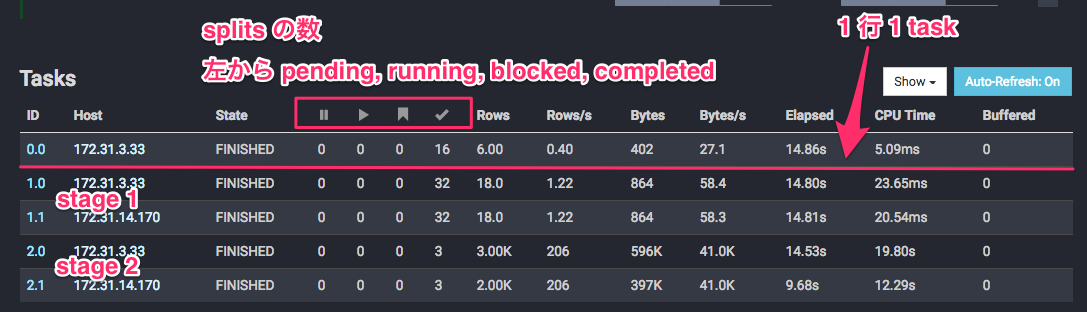
今回の例では 2 worker しか用意していないので、root stage 以外は全 worker に task が配分されていることがわかります。また、stage 2 は各 task に 3 split 存在し、stage 1 は各 task に 32 split 存在することもわかります。
ここの情報を見るだけで、特定の worker だけが大量のデータを処理していないかや、他の worker と同程度のデータ量しか処理していないのにパフォーマンスが異常に悪い worker がいないかを把握することができます。
なお、stage 2 には合計 6 split 存在するわけですが、入力データが 6 ファイルなので、サンプルデータの規模であれば 1 split が S3 の 1 オブジェクトに相当していることがわかります。
% aws s3 ls s3://ap-northeast-1.elasticmapreduce.samples/cloudfront/data/
2014-11-01 08:06:38 0
2014-11-06 10:37:38 203052 log1
2014-11-06 10:37:38 203435 log2
2014-11-06 10:37:38 101270 log3
2014-11-06 10:37:38 101813 log4
2014-11-06 10:37:38 203642 log5
2014-11-06 10:37:38 203494 log6
Live Plan タブでは各 stage の処理内容や依存関係(論理プラン)を視覚的に表示してくれます。
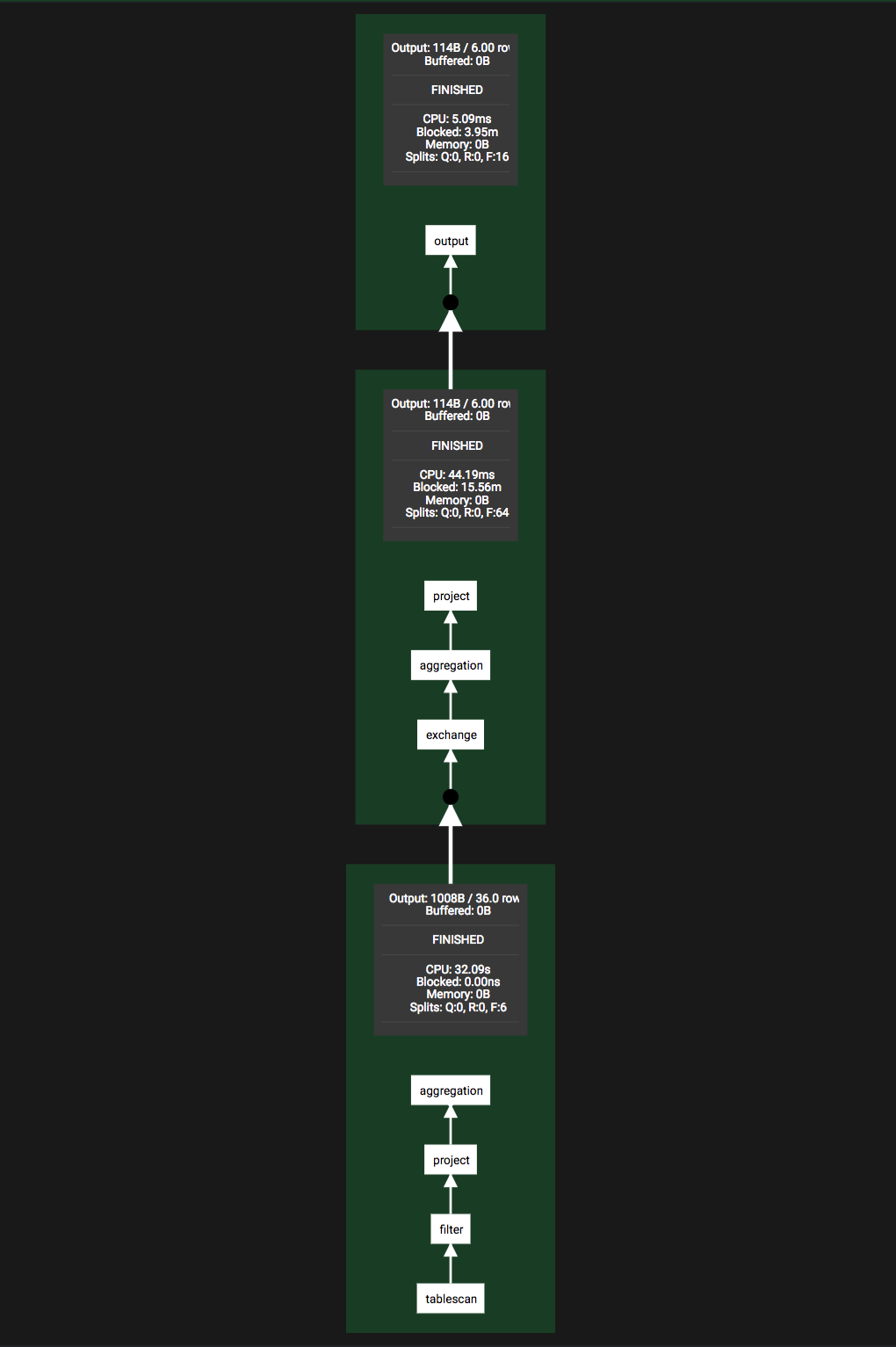
この図から、stage 2(一番下に表示されている stage)では次のようなことが行われていることが理解できます。
- tablescan
- Hive テーブル(S3)からデータの取得
- filter
- いわゆる
WHERE句の処理。dateobject BETWEEN DATE '2014-07-05' AND DATE '2014-08-05'によるフィルタリング
- いわゆる
- project
- os カラムのみ取得(厳密には集約処理のために os のハッシュ値のカラムも追加するっぽい)
- aggregation
- os カラム(のハッシュ値)で集約して行数をカウント
論理プランの詳細を知りたければ EXPLAIN と併用する必要があります。
EXPLAIN SELECT
os,
COUNT(*) count
FROM
hive.default.cloudfront_logs
WHERE
dateobject BETWEEN DATE '2014-07-05' AND DATE '2014-08-05'
GROUP BY
os
;
Query Plan
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
- Output[os, count] => [os:varchar, count:bigint]
- RemoteExchange[GATHER] => os:varchar, count:bigint
- Project[] => [os:varchar, count:bigint]
- Aggregate(FINAL)[os][$hashvalue] => [os:varchar, $hashvalue:bigint, count:bigint]
count := "count"("count_8")
- LocalExchange[HASH][$hashvalue] ("os") => os:varchar, count_8:bigint, $hashvalue:bigint
- RemoteExchange[REPARTITION][$hashvalue_9] => os:varchar, count_8:bigint, $hashvalue_9:bigint
- Aggregate(PARTIAL)[os][$hashvalue_10] => [os:varchar, $hashvalue_10:bigint, count_8:bigint]
count_8 := "count"(*)
- ScanFilterProject[table = hive:default:cloudfront_logs, filterPredicate = ("dateobject" BETWEEN DATE '2014-07-05' AND DATE '2014-08-05')] => [os:varchar, $hashvalue_10:bigint]
$hashvalue_10 := "combine_hash"(bigint '0', COALESCE("$operator$hash_code"("os"), 0))
LAYOUT: default.cloudfront_logs
dateobject := dateobject:date:0:REGULAR
os := os:string:10:REGULAR
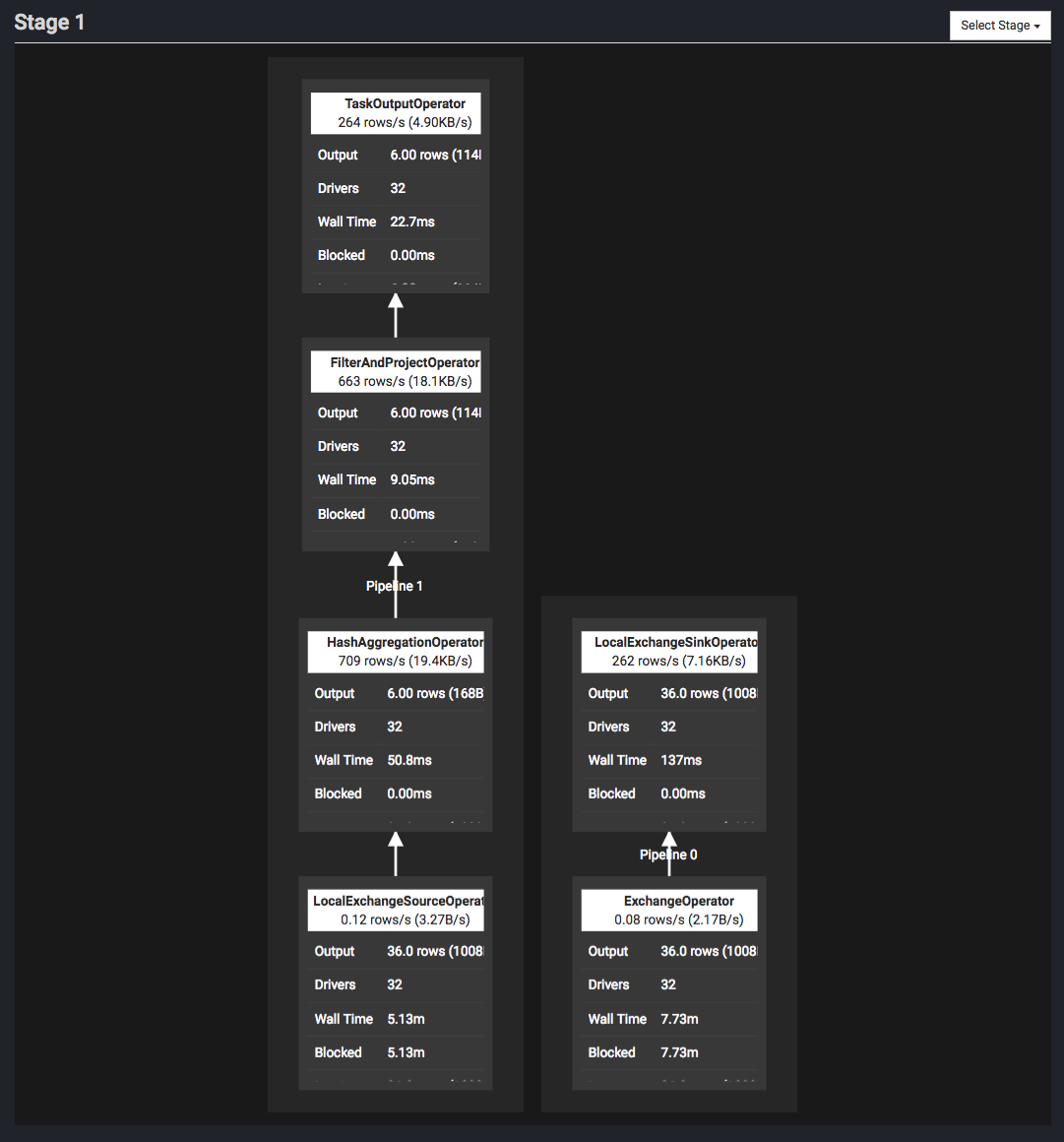
Live Plan タブでは、各 stage の枠内をクリックすると、その stage の詳細を確認することができます。次の図は stage 1 をクリックした時の図です。
更に各 operator の枠内をクリックすると、その operator の統計情報を確認することができます。次の図は HashAggregationOperator をクリックした時の図です。
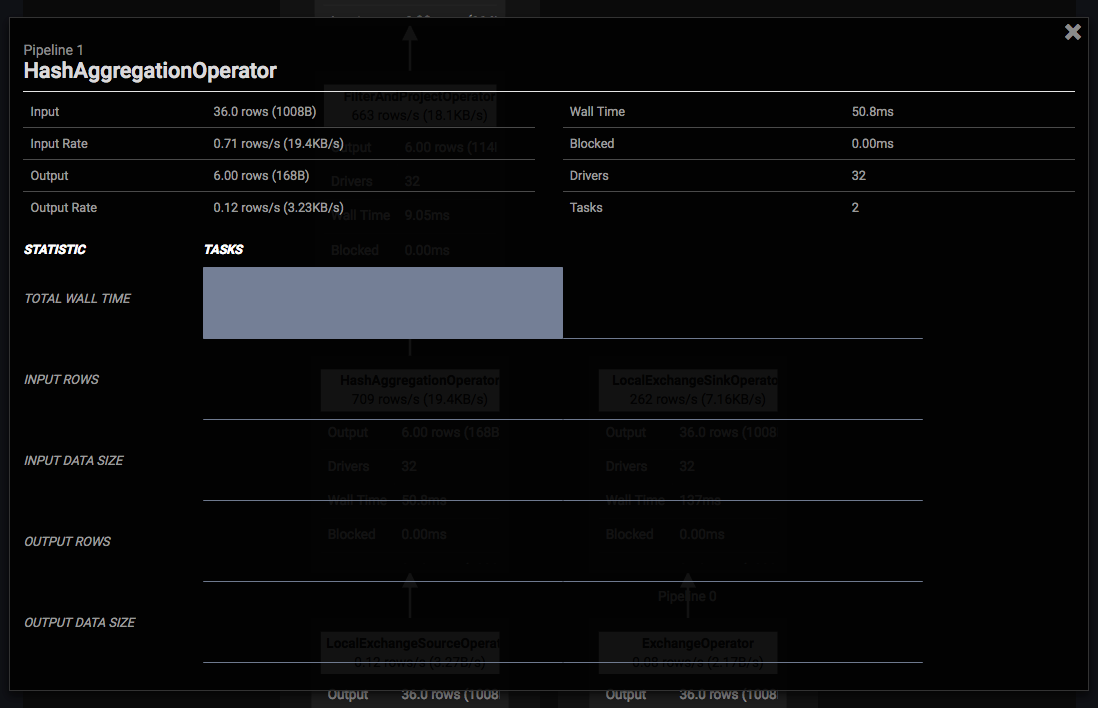
Input が 36 行 1008 bytes で Output が 6 行 168 bytes であることなどがわかります。これによって、ある operator でいきなり行数が増えたということも把握することができます。
以前、一定間隔の滞在ユーザ数を高速に求める Presto SQL ではクエリの詳細情報を JSON で取得して inputDataSize と outputDataSize を確認しましたが、このように手軽に確認することもできます。
役立ちそうな REST API
最後に、運用に役立ちそうな REST API のエンドポイントについて紹介します。Presto は coordinator と worker も HTTP でやり取りするので、外部向けの API なのか内部向けの API なのか判別が付きにくいですが、知っておくと役立ちそうなものには次のようなものがあります。
全てのエンドポイントに関して、末尾に ?pretty を付けると整形された JSON が返ってきます。
| エンドポイント | 概要 |
|---|---|
| GET /v1/cluster | runningQueries, activeWorkers など、クラスタの情報 |
| GET /v1/node | worker の情報 |
| GET /v1/info | Presto のバージョン情報など |
| PUT /v1/info/state | 現状だと graceful shutdown する時に使用(詳細は後述) |
| GET /v1/info/state | node の state |
| GET /v1/jmx/mbean | MBean の情報 |
| GET /v1/jmx/mbean/{objectName} | MBean の情報のうち objectName が一致するもの |
| GET /v1/jmx/mbean/{objectName}/{attributeName} | MBean の objectName の情報のうち、指定した attributeName の値 |
PUT /v1/info/state について捕捉します。worker を切り離したい場合、その worker 上で次のようなリクエストを送れば graceful shutdown させることができます。
curl \
-X PUT \
-H 'Content-Type: application/json' \
-d '"SHUTTING_DOWN"' localhost:8889/v1/info/state
リクエストを受け取ると、worker は次のことを行います。
- state を SHUTTING_DOWN に変えて
shutdown.grace-period(デフォルト 2 分)待つ- おそらく coordinator が SHUTTING_DOWN になったことを認識するまでの猶予期間
- coordinator が SHUTTING_DOWN になったことを認識したら新しい task が投げられることはない
- active tasks が 0 になるまで待つ
shutdown.grace-period(デフォルト 2 分)待つ- おそらく active tasks が 0 になってすぐ停止すると、coordinator が task が正常に終了したかどうか判断できなくなるのでそれを防ぐのが目的
- 諸々停止処理をする
cf. GracefulShutdownHandler.java
ただ、EMR の場合は upstart で presto-server のプロセスが管理されているので、良きタイミングで stop presto-server も実行しなければ、切り離したはずの worker が復活するので注意してください。
upstart については次のエントリーで詳細に触れています。
upstart で start した job の設定を変更するには一度 stop する必要がある - あらびき日記
おわりに
以上、Presto の運用に役立ちそうな内容についてざっくり説明しました。
今まで業務で行ったパフォーマンスチューニングや安定化についても追々公開できればと思います。
ところで、僕の所属している Repro では Presto や Cassandra の最適化・安定化やデータパイプラインの効率化ができる人・興味のある人を募集しています!僕がエンジニアリングタスクに集中できるようにチームマネージメントをしてくれる僕の上司も募集しています!!
興味があれば下記採用ページから応募してもらったり、@a_bicky にご連絡いただけたりすると、とってもとっても嬉しいです!
-
Presto は Facebook が開発しているものと、2019 年に発足された Trino Software Foundation(旧 Presto Software Foundation)によって開発されているものが存在しましたが、後者は Trino に改名されました 。EMR では前者は Presto または Presto(DB) と表記され、後者は PrestoSQL と表記されています。 ↩
-
ただし、データを分割できないデータソースがあると、特定の worker に負荷が集中して台数を増やしてもスループットもが上がらないことがあります ↩
-
Hadoop / Spark Conference Japan 2019 の懇親会で Spark コミッターの方や Cloudera の方が言っていたのできっと間違いない ↩
-
別クラスタの Hive metastore やデータにアクセスできるように security group 等の設定が別途必要です ↩
-
Presto のバージョンが 300 以降であれば com.facebook.presto ではなく io.prestosql や io.trino になると思います(未確認) ↩