Docker のログを columnify で Athena (Presto) に特化した Parquet にする

先日 columnify という、入力データを Parquet フォーマットに変換するツールがリリースされました。
cf. 軽量な Go 製カラムナフォーマット変換ツール columnify を作った話 - Repro Tech Blog
また、fluent-plugin-s3 で compressor として columnify をサポートする話が出ています。1
cf. Add parquet compressor using columnify by okkez · Pull Request #338 · fluent/fluent-plugin-s3
個人的に前々から Docker のログを Parquet フォーマットで S3 に put して Athena で検索できると素敵だなと思っていたので喜ばしいことですね!そんなわけで、Docker のログを fluentd log driver で fluentd に送りつつ、columnify で Athena に適した Parquet フォーマットに変換し、S3 に put するにはどうすると良いか試してみました。
なお、ログを Parquet フォーマットで S3 に送るだけであれば Kinesis Data Firehose を使うのが手軽でしょうが、既存のアーキテクチャとの相性や柔軟性の観点から、その選択肢はないものとします。
アジェンダ
- Parquet の概要と Presto で Parquet を扱う上での注意点
- Docker のログを fluentd 経由で Parquet にして S3 に送る設定
- 他のフォーマットとのパフォーマンスの比較
- まとめ
Parquet の概要と Presto で Parquet を扱う上での注意点
columnify のオプションに関係してくるので、Parquet(カタカナ読みだと「パーケイ」)の概要と、Athena のバックエンドに使われている Presto における Parquet の扱いについて簡単に説明します。
Parquet の概要
Parquet の特徴としてざっくりと次のように理解しておけば良いと思います。
- 列指向フォーマット
- 特定のカラムしか使わない場合はその他のカラムを読み取る必要がないので効率が良い
- カラムのページ単位で符号化・圧縮するので圧縮が効きやすい
- run length encoding, dictionary encoding, delta encoding のような符号化をサポートしている
- columnify では符号化方式を指定することができないが、colummnify で使っている parquet-go ではサポートしているので将来指定できるようになるかも
- 1 ファイルに複数の row group を含むことができる
- row group はカラム単位でチャンクを保有し、各チャンクは複数のページに分かれており、ページごとに符号化・圧縮する
- GZIP 等と異なり、処理範囲を row group で分割できるので、1 ファイルの処理を row group の数だけ並列で処理することができる
- ページの圧縮方式として gzip, lzo, snappy 等を指定できる
- row group ごとに各カラムの最小値・最大値、含まれる値の辞書等のメタデータを保有している
- 最小値・最大値や辞書の情報から row group に所望のデータが存在しないことがわかればその row group の読み込みをスキップできる
次の図は github.com/apache/parquet-format に載っている Parquet のフォーマットを表す図です。
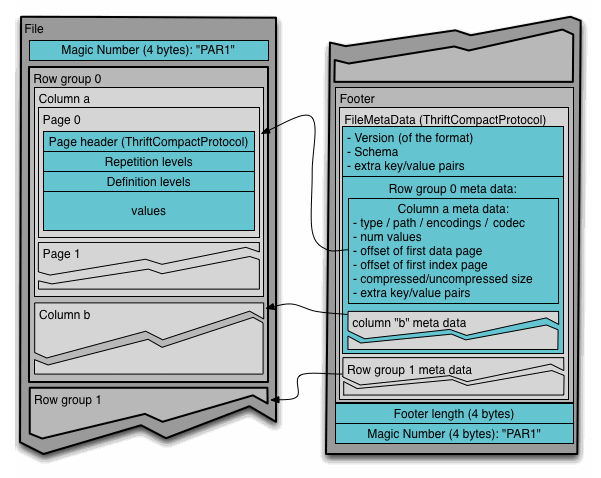
この図では row group に column a や b などの値がカラムごとにチャンクとして保存されており、各チャンクは更にページに分かれていることがわかります。また、フッターに各 row group のメタデータとしてカラムチャンクのメタデータが保存されていることもわかります。
列指向フォーマットについてもうちょっと詳細に知りたい方は次の記事を読んでみると良いと思います。
カラムナフォーマットのきほん 〜データウェアハウスを支える技術〜 - Retty Tech Blog
Presto で Parquet を扱う上での注意点
Presto では 0.138 で predicate pushdown などをサポートした新しい Parquet reader が実験的に導入され、0.203 でデフォルトになり、0.213 で古い Parquet reader が廃止されました。Athena では Presto 0.172 をベースにしていることと、実験結果のデータのスキャン量から判断して新しい Parquet reader が使われていると考えられます。
新しい Parquet reader の何が嬉しいかについては次の記事が詳しいです。
Engineering Data Analytics with Presto and Parquet at Uber
Presto で Parquet を利用する上で最低限気を付けるべき点は次の 2 点です。
- フィルタリングで使うカラムでソートする
- row gruop のサイズは 32 MB を少し超えるようにする
フィルタリングで使うカラムでソートすべき理由は Parquet の特徴から明白でしょう。ソートされていることによって、メタデータの最小値・最大値を使ったフィルタリングを最大限に活かせます。
例えば、row group が 3 つ存在し、a というカラムの min, max がそれぞれ次のようになっていた場合、a = 11 のレコードを取得するには row group 1 だけを見れば良いです。
| row group | min | max |
|---|---|---|
| 0 | 0 | 10 |
| 1 | 10 | 20 |
| 2 | 20 | 30 |
一方、a というカラムの min, max がそれぞれ次のようになっていた場合、全ての row group を精査する必要があります。
| row group | min | max |
|---|---|---|
| 0 | 1 | 28 |
| 1 | 0 | 29 |
| 2 | 3 | 30 |
前者のようにするためには a でソートする必要があります。
適切な row group のサイズについて理解するには、ある程度 Presto と Presto の Hive connector について理解していないいけません。
Presto では対象データを split という単位に分割した上で各 worker にタスクを割り振ります。この単位は hive.max-initial-split-size や hive.max-split-size を指定しない限り 32 MB 単位です。2
cf. HiveClientConfig.java#L134-L140
例えば 64 MB のファイルを split に分割する場合、1 つ目の split は start 0, length 33,554,432(ファイルの前半部分)、2 つ目の split は start 33,554,432, length 33,554,432(ファイルの後半部分)になります。
Parquet reader は row group の最初のデータのオフセットが自分の担当する split の範囲にある row group だけを処理します。
cf. ParquetPageSourceFactory.java#L156-L161
よって、もし 2 つの worker で 64 MB のファイルを処理する場合、row group が 1 つしかなければ次のように split は 2 つになるものの、worker 1 は処理する row group がないため、worker 0 だけで全てのデータを処理することになります。
| worker | split | target row gruop | data size |
|---|---|---|---|
| 0 | start: 0, length: 33,554,432 | 0 (offset 4) | 67,108,864 |
| 1 | start: 33,554,432, length: 33,554,432 | - | 0 |
1 つ目の row group のサイズがちょうど 32 MB であれば、worker 0 と worker 1 が同程度のデータを処理することになります。
| worker | split | target row gruop | data size |
|---|---|---|---|
| 0 | start: 0, length: 33,554,432 | 0 (offset 4) | 33,554,436 |
| 1 | start: 33,554,432, length: 33,554,432 | 1 (offset 33,554,436) | 33,554,428 |
もし 1 つ目の row group のサイズが 60 MB であれば、worker 0 と worker 1 両方がデータを処理するものの、2 つ目の row group が小さく、worker 0 に負荷が偏るので注意が必要です。
| worker | split | target row gruop | data size |
|---|---|---|---|
| 0 | start: 0, length: 33,554,432 | 0 (offset 4) | 62,914,564 |
| 1 | start: 33,554,432, length: 33,554,432 | 1 (offset 62,914,564) | 4,194,300 |
逆に row group のサイズが 31 MB のように 32 MB より少し小さいと、row group のサイズが 60 MB の時と同様 worker 0 に負荷が偏ってしまいます。
| worker | split | target row gruop | data size |
|---|---|---|---|
| 0 | start: 0, length: 33,554,432 | 0 (offset 4) 1 (offset 32,505,860) |
65,011,716 |
| 1 | start: 33,554,432, length: 33,554,432 | 2 (offset 65,011,716) | 2,097,148 |
実例として、後述のパフォーマンス比較のために生成した次のオブジェクトをそれぞれ配置した 2 つのテーブルに対して、特定の条件にマッチするレコードを EMR 5.30.1 の Presto でカウントしてみます。
- logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_0.parquet
- size: 85,073,688, row group の数 1
- logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_0.parquet
- size: 85,075,319, row group の数 3
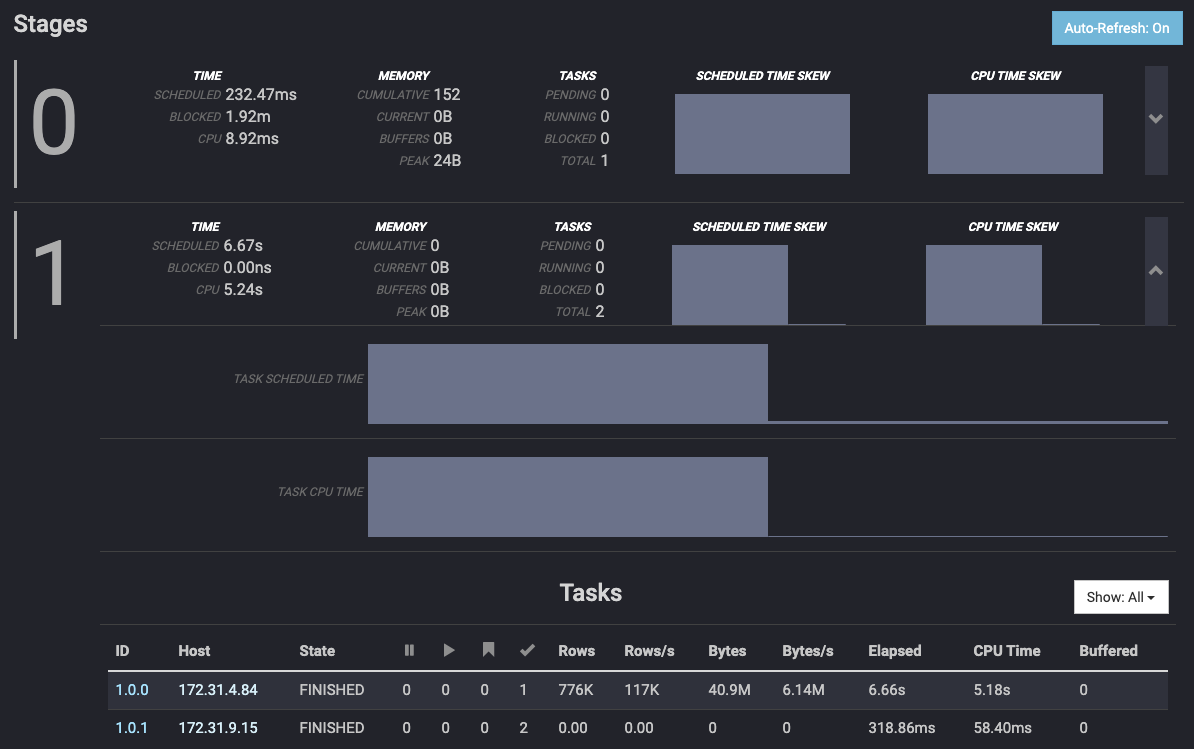
まず、row group の数が 1 のオブジェクトを持つテーブルのレコードをカウントした結果ですが、次のように split(チェックマークのカラムが処理の完了した split の数)は worker 172.31.4.84 に 1、worker 172.31.9.15 に 2 割り当てていますが、処理した行数は 172.31.9.15 が 0 になっていることがわかります。
一方、row group の数が 3 のオブジェクトを持つテーブルのレコードをカウントした結果は split が同じ様に配分されているものの、rows がちゃんとバラけていることがわかります。3
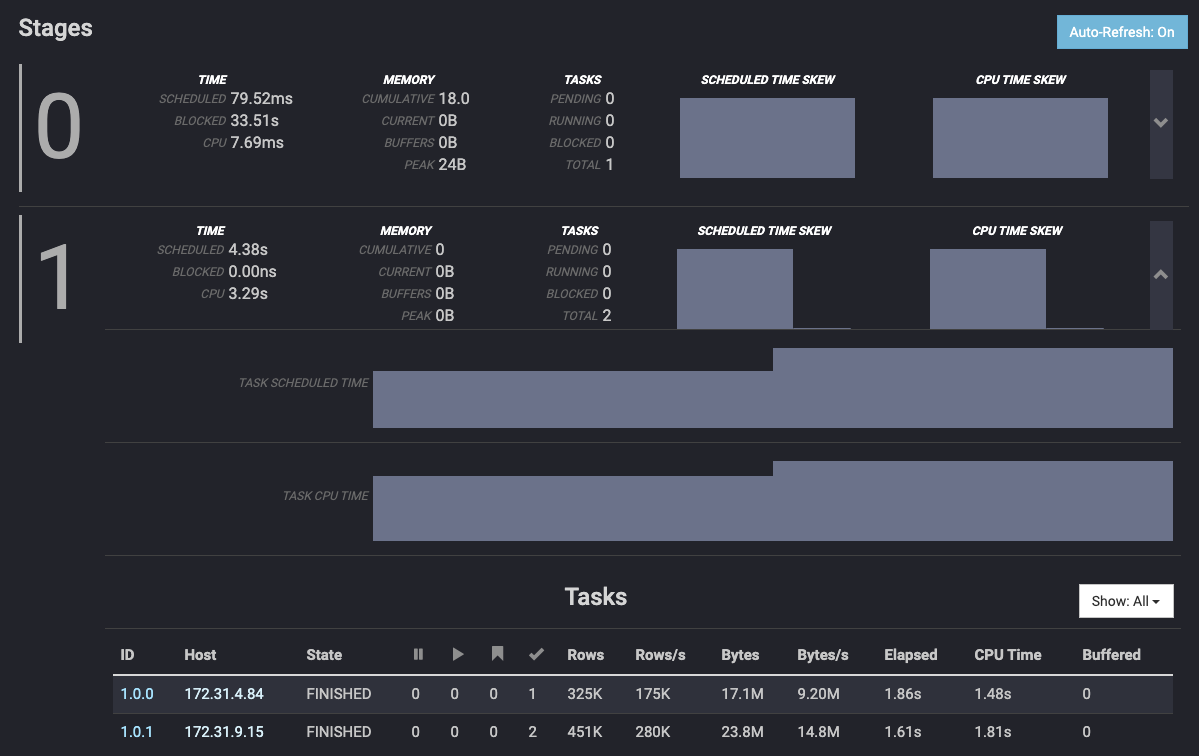
なお、Hive 等で Parquet を出力する際には parquet.block.size によって、columnify では -parquetRowGroupSize によって row group のサイズを指定できますが、実装を見る限り、どちらもファイルに書き出す直前で例外的に大きなレコードが入ってこない限りはサイズより若干小さくなります。よって、row group のサイズが確実に 32 MB を超えるようにするには 32 MB より少し余裕を見た値を指定するのが良いです。
Presto についてもっと詳しく知りたい方は Amazon Elastic MapReduce (EMR) ではじめる Presto 入門 を参照してください。
Docker のログを fluentd 経由で Parquet にして S3 に送る設定
例えば全てのログを最大 5 分間隔で S3 に put しつつ、特定のパターンにマッチするログは別の output plugin(例えば stdout output plugin)にも流す設定は次のようになります。
<source>
@type forward
@label @mainstream
port 24224
</source>
<label @mainstream>
<filter docker.**>
@type record_transformer
enable_ruby
remove_keys FLUENTD_STDOUT_FILTER_PATTERN
<record>
filter_stdout ${record['source'] == 'stdout' && record['FLUENTD_STDOUT_FILTER_PATTERN'] && record['log'].match?(record['FLUENTD_STDOUT_FILTER_PATTERN'])}
</record>
</filter>
<match docker.**>
@type copy
<store>
@type relabel
@label @stdout
</store>
<store>
@type relabel
@label @s3
</store>
</match>
</label>
<label @stdout>
<filter docker.**>
@type grep
<exclude>
key filter_stdout
pattern /\Atrue\z/
</exclude>
</filter>
<filter docker.**>
@type record_transformer
remove_keys filter_stdout
</filter>
<match docker.**>
@type stdout
</match>
</label>
<label @s3>
<filter docker.**>
@type record_transformer
enable_ruby
remove_keys filter_stdout
<record>
log_time ${(time.to_r.truncate(3) * 1000).to_i}
</record>
</filter>
<match docker.**>
@type s3
s3_bucket <%= ENV['S3_BUCKET'] %>
s3_region <%= ENV['S3_REGION'] %>
path logs/${tag[1]}_parquet/dt=%Y-%m-%d/hour=%H/
s3_object_key_format %{path}%{time_slice}_%{index}_%{hex_random}.%{file_extension}
<buffer tag,time>
@type file
path /fluentd/log/s3-parquet
timekey 1h
timekey_wait 5m
timekey_use_utc true
flush_mode interval
flush_interval 5m
</buffer>
<format>
@type msgpack
</format>
store_as parquet
<compress>
schema_type avro
schema_file /fluentd/avsc/docker_log.avsc
record_type msgpack
parquet_row_group_size 35651584
</compress>
</match>
</label>
store_as parquet で fluent/fluent-plugin-s3#338 の compressor が使われるようにしています。docker_log.avsc は次のような内容です。
{
"type": "record",
"name": "DockerLog",
"fields" : [
{"name": "log_time", "type": "long"},
{"name": "container_id", "type": "string"},
{"name": "container_name", "type": "string"},
{"name": "source", "type": "string"},
{"name": "log", "type": "string"}
]
}
上記の設定のポイントは次のとおりです。
- S3 にアップロードするログには epoch milliseconds のフィールドを付与する (
log_time)- ログを検索する際にこのフィールドで時間を絞れば Parquet predicate pushdown の恩恵を受けられる
- epoch milliseconds の type は long にする
- Presto は Parquet の int64 のフィールドが Hive テーブルで timestamp として扱われていれば epoch milliseconds として処理する(logical type はサポートしていないように見える) 4
- S3 の key を日付と時間で分割する (dt=%Y-%m-%d/hour=%H)
- パーティションが多くなり過ぎないし、特定の時間帯のログだけを見たい場合に高速に検索できる
- s3_object_key_format に hex_random を付与する
- 複数の fluentd worker から put する場合、これがないと同時に同じ key に put して片方が消失することがある
- format に msgpack を使う
- format json に比べて、同じ
chunk_size_limitでもより多くのログを詰め込めるし、columnify 的にも若干パフォーマンスが高い
- format json に比べて、同じ
- 最終的に作成される Parquet データの row group が 32 MB を少し超えるように
parquet_row_group_sizeを調整する- row group が 32 MB を少し超えるようにすべき理由については前述したとおり
- S3 以外の output plugin がフィルターするための情報を各レコードに持たせる (FLUENTD_STDOUT_FILTER_PATTERN)
- アプリケーションのログが変わる度にいちいち fluentd の設定を更新したくないので
- アプリケーションコードを書く人がカジュアルに設定を更新できるのであれば不要
fluentd にログを送る docker コンテナの設定は次のようになります。
version: '3.7'
services:
web:
image: nginx
ports:
- "80:80"
environment:
# Don't output logs with status code 2XX to stdout
FLUENTD_STDOUT_FILTER_PATTERN: '\A[^ ]* [^ ]* [^ ] \[[^\]]*\] "\S+(?: +[^\"]*?(?: +\S*)?)?" 2'
logging:
driver: fluentd
options:
fluentd-address: host.docker.internal:24224
fluentd-sub-second-precision: "true"
tag: docker.nginx
env: FLUENTD_STDOUT_FILTER_PATTERN
ポイントは次のとおりです。
- 環境変数として S3 以外の output plugin がフィルターするための情報を定義する
- この情報をログに付与するために log driver の options.env を指定する
- fluentd-sub-second-precision を true にする
- false だと秒単位でしか時間がわからないので、Athena でログを見る時に時間でソートしても所望の結果が得られない
fluentd log driver にどのようなオプションがあるかは https://docs.docker.com/config/containers/logging/fluentd/ を参照してください。fluentd-request-ack のようにドキュメントには載っていないオプションも存在するようですが…。
なお、実際に試してみたい方は docker-log-and-fluent-plugin-s3-with-columnify-example#put-nginx-logs-to-s3 の手順で試すことができます。
他のフォーマットとのパフォーマンスの比較
せっかく Parquet で put しても、Athena で検索する際のパフォーマンスが低いと意味がありません。
Docker のログを fluentd-plugin-s3 で S3 に put し、それを Athena で検索する場合のパフォーマンスを次のケースで比較してみます。
- JSON Lines を GZIP 圧縮
- JSON Lines を LZO 圧縮
- Parquet(parquetRowGroupSize: 128 MB)
- Parquet(parquetRowGroupSize: 34 MB)
いずれも chunk_size_limit はデフォルトの 256 MB です。
また、それぞれの compressor が実行するコマンドのパフォーマンスも比較してみます。
事前準備
docker-log-and-fluent-plugin-s3-with-columnify-example#put-pseudo-docker-logs-to-s3 の手順で、1 時間に 1,000 万件の nginx ログが送られたものとして各フォーマットで S3 にログを put しました。
これによって、次のようなオブジェクトが生成されました。
size key
25843214 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_0.jsonl.gz
25841077 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_1.jsonl.gz
25841030 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_2.jsonl.gz
25823967 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_3.jsonl.gz
25842511 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_4.jsonl.gz
25820820 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_5.jsonl.gz
25831316 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_6.jsonl.gz
25828080 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_7.jsonl.gz
25842326 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_8.jsonl.gz
25844262 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_9.jsonl.gz
25832003 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_10.jsonl.gz
25822328 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_11.jsonl.gz
25841187 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_12.jsonl.gz
25841609 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_13.jsonl.gz
1615949 logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_14.jsonl.gz
53829225 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_0.jsonl.lzo
53822444 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_1.jsonl.lzo
53809759 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_3.jsonl.lzo
53813729 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_4.jsonl.lzo
53798350 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_5.jsonl.lzo
53805230 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_6.jsonl.lzo
53821871 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_7.jsonl.lzo
53833069 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_8.jsonl.lzo
53813293 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_9.jsonl.lzo
53795589 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_10.jsonl.lzo
53805779 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_11.jsonl.lzo
53814571 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_12.jsonl.lzo
53837281 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_13.jsonl.lzo
3358487 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_14.jsonl.lzo
53840009 logs/nginx_lzo/dt=2020-08-24/hour=12/2020082412_2.jsonl.lzo
28224512 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_0.msgpack.gz
28248073 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_1.msgpack.gz
28217170 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_10.msgpack.gz
28216812 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_11.msgpack.gz
25007893 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_12.msgpack.gz
28215453 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_2.msgpack.gz
28214808 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_3.msgpack.gz
28217830 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_4.msgpack.gz
28206484 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_5.msgpack.gz
28227419 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_6.msgpack.gz
28209093 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_7.msgpack.gz
28222797 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_8.msgpack.gz
28207289 logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_9.msgpack.gz
85073688 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_0.parquet
85269271 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_1.parquet
85043095 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_2.parquet
85074336 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_3.parquet
85116104 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_4.parquet
85120062 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_5.parquet
85132125 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_6.parquet
85208989 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_7.parquet
85060980 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_8.parquet
85119839 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_9.parquet
85107296 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_10.parquet
84937092 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_11.parquet
75447257 logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_12.parquet
85075319 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_0.parquet
85270911 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_1.parquet
85044753 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_2.parquet
85075998 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_3.parquet
85117745 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_4.parquet
85121660 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_5.parquet
85133790 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_6.parquet
85210581 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_7.parquet
85062578 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_8.parquet
85121424 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_9.parquet
85108990 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_10.parquet
84938696 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_11.parquet
75448890 logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_12.parquet
logs/nginx_parquet 以下のオブジェクトは parquet_row_group_size を指定しなかったもの(つまりデフォルトの 128 MB)、logs/nginx_parquet_optimized 以下のオブジェクトは 35,651,584 (34 MB) を指定したものです。
例えば、logs/nginx_parquet/dt=2020-08-24/hour=12/2020082412_0.parquet のメタ情報を parquet-inspect で確認すると、row group が 1 つしか存在しないことがわかります。
% ./parquet-inspect 2020082412_0.parquet
row group 0:
offset: 4
total_compressed_byte_size: 85072752
total_uncompressed_byte_size: 233784645
rows: 776061
sorting_columns: None
path: ['log_time']
min: 1598270400000
max: 1598270679381
total_compressed_size: 2273812
total_uncompressed_size: 6492828
path: ['container_id']
min: 02e62f7f71be05ebc449ace734ac2332f3888b67f002019acf9299a2755a5016
max: fbbbed4f1ffa53a7abf7f0ee408dd54cae16338c1f321261735f28a413a59ac3
total_compressed_size: 37986425
total_uncompressed_size: 53814948
path: ['container_name']
min: /test-container
max: /test-container
total_compressed_size: 1222266
total_uncompressed_size: 15124279
path: ['source']
min: stdout
max: stdout
total_compressed_size: 715160
total_uncompressed_size: 8017869
path: ['log']
min: 1.0.116.18 - - [24/Aug/2020:12:04:37 +0000] "GET /v1/foo HTTP/1.1" 200 153 "-" "Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16" "-"
max: 99.99.61.170 - - [24/Aug/2020:12:00:01 +0000] "GET /v1/baz HTTP/1.1" 200 177 "-" "Mozilla/5.0 (Windows NT x.y; Win64; x64; rv:10.0) Gecko/20100101 Firefox/10.0" "-"
total_compressed_size: 42875089
total_uncompressed_size: 150334721
一方で同じ chunk に相当する logs/nginx_parquet_optimized/dt=2020-08-24/hour=12/2020082412_0.parquet は 3 つの row gruop に分かれており、1 つ目と 2 つ目の row group に含まれるレコード数も同程度になっていることがわかります。
% ./parquet-inspect 2020082412_0.parquet
row group 0:
offset: 4
total_compressed_byte_size: 35621227
total_uncompressed_byte_size: 97897134
rows: 325018
sorting_columns: None
path: ['log_time']
min: 1598270400000
max: 1598270517006
total_compressed_size: 952578
total_uncompressed_size: 2719172
path: ['container_id']
min: 02e62f7f71be05ebc449ace734ac2332f3888b67f002019acf9299a2755a5016
max: fbbbed4f1ffa53a7abf7f0ee408dd54cae16338c1f321261735f28a413a59ac3
total_compressed_size: 15907704
total_uncompressed_size: 22537835
path: ['container_name']
min: /test-container
max: /test-container
total_compressed_size: 511757
total_uncompressed_size: 6334046
path: ['source']
min: stdout
max: stdout
total_compressed_size: 299487
total_uncompressed_size: 3357872
path: ['log']
min: 1.0.138.227 - - [24/Aug/2020:12:00:30 +0000] "GET /v1/bar HTTP/1.1" 200 720 "-" "Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16" "-"
max: 99.99.61.170 - - [24/Aug/2020:12:00:01 +0000] "GET /v1/baz HTTP/1.1" 200 177 "-" "Mozilla/5.0 (Windows NT x.y; Win64; x64; rv:10.0) Gecko/20100101 Firefox/10.0" "-"
total_compressed_size: 17949701
total_uncompressed_size: 62948209
row group 1:
offset: 35621231
total_compressed_byte_size: 35615344
total_uncompressed_byte_size: 97852546
rows: 324808
sorting_columns: None
path: ['log_time']
min: 1598270517006
max: 1598270633937
total_compressed_size: 951500
total_uncompressed_size: 2717492
path: ['container_id']
min: 02e62f7f71be05ebc449ace734ac2332f3888b67f002019acf9299a2755a5016
max: fbbbed4f1ffa53a7abf7f0ee408dd54cae16338c1f321261735f28a413a59ac3
total_compressed_size: 15905607
total_uncompressed_size: 22523414
path: ['container_name']
min: /test-container
max: /test-container
total_compressed_size: 511628
total_uncompressed_size: 6330056
path: ['source']
min: stdout
max: stdout
total_compressed_size: 299296
total_uncompressed_size: 3355772
path: ['log']
min: 1.0.24.64 - - [24/Aug/2020:12:03:01 +0000] "GET /v1/baz HTTP/1.1" 200 554 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/7046A194A" "-"
max: 99.99.255.27 - - [24/Aug/2020:12:02:46 +0000] "GET /v1/baz HTTP/1.1" 200 810 "-" "Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16" "-"
total_compressed_size: 17947313
total_uncompressed_size: 62925812
row group 2:
offset: 71236575
total_compressed_byte_size: 13836181
total_uncompressed_byte_size: 38034965
rows: 126235
sorting_columns: None
path: ['log_time']
min: 1598270633937
max: 1598270679381
total_compressed_size: 369734
total_uncompressed_size: 1056164
path: ['container_id']
min: 02e62f7f71be05ebc449ace734ac2332f3888b67f002019acf9299a2755a5016
max: fbbbed4f1ffa53a7abf7f0ee408dd54cae16338c1f321261735f28a413a59ac3
total_compressed_size: 6173114
total_uncompressed_size: 8753699
path: ['container_name']
min: /test-container
max: /test-container
total_compressed_size: 198881
total_uncompressed_size: 2460177
path: ['source']
min: stdout
max: stdout
total_compressed_size: 116377
total_uncompressed_size: 1304225
path: ['log']
min: 1.0.116.18 - - [24/Aug/2020:12:04:37 +0000] "GET /v1/foo HTTP/1.1" 200 153 "-" "Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16" "-"
max: 99.99.157.31 - - [24/Aug/2020:12:04:08 +0000] "GET /v1/foo HTTP/1.1" 200 582 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36" "-"
total_compressed_size: 6978075
total_uncompressed_size: 24460700
Athena のパフォーマンス
ログの中から status code 200 のログの数をカウントしてみます。ベースとなる SQL は次のとおりで、ここでは dt に 2020-08-24、hour に 12 を指定します。
SELECT
COUNT(1)
FROM
$ATHENA_DATABASE.$table
WHERE
dt = '$dt'
AND hour = '$hour'
AND log LIKE '%HTTP/1.1" 200%'
;
結果は次のとおりです。
| JSON Lines (GZIP) | JSON Lines (LZO) | Parquet (128 MB) | Parquet (34 MB) | |
|---|---|---|---|---|
| total_execution_time_in_millis | 7,058 | 7,119 | 4,872 | 2,739 |
| data_scanned_in_bytes | 363,310,611 | 756,799,241 | 552,599,550 | 552,599,550 |
実行時間は Parquet (34 MB) が最も速く、スキャンしたデータサイズは GZIP が最も少なくなりました。今回のデータだと log カラムの容量が支配的なので、Parquet がカラムナフォーマットとはいえ、スキャンするデータサイズの観点では GZIP に軍配が上がりました。
次に、ログの中でも 12:00:00 から 12:10:00 の status code 200 のログの数をカウントしてみます。ベースとなる SQL は次のとおりで、先程と同様 dt に 2020-08-24、hour に 12 を指定します。
SELECT
COUNT(1)
FROM
$ATHENA_DATABASE.$table
WHERE
dt = '$dt'
AND hour = '$hour'
AND log_time BETWEEN TIMESTAMP '$dt $hour:00:00' AND TIMESTAMP '$dt $hour:10:00'
AND log LIKE '%HTTP/1.1" 200%'
;
結果は次のとおりです。
| JSON Lines (GZIP) | JSON Lines (LZO) | Parquet (128 MB) | Parquet (34 MB) | |
|---|---|---|---|---|
| total_execution_time_in_millis | 7,190 | 8,731 | 5,854 | 2,595 |
| data_scanned_in_bytes | 363,310,611 | 756,799,241 | 135,486,504 | 109,240,647 |
実行時間は Parquet (34 MB) が最も速く、スキャンしたデータサイズも Parquet (34 MB) が最も少なくなりました。先程に比べて Parquet の data_scanned_in_bytes が 5 分の 1 程度になっているのは predicate pushdown の効果と考えられます。docker のログは大幅に遅延することはほぼないと考えられるため、log_time でほぼソートされている状態になります。よって、hour のパーティションで絞り込みつつ、さらに時間の範囲を限定すれば、かなりの row group の処理をスキップすることができます。Athena はスキャンしたデータに対する従量課金なので、利用料金にも影響が出てきます。
Compressor のパフォーマンス
compressor のパフォーマンスの比較には事前準備で生成したオブジェクトのうち、次のオブジェクトを展開したファイルを使います。
- logs/nginx_gz/dt=2020-08-24/hour=12/2020082412_0.jsonl.gz
- GZIP, LZO 用
- logs/nginx_msgpack/dt=2020-08-24/hour=12/2020082412_0.msgpack.gz
- Parquet 用
検証は abicky/docker-log-and-fluent-plugin-s3-with-columnify-example の generate_logs ディレクトリで行いました。
% docker-compose run --rm --entrypoint '' fluentd sh
/ $ # 起動後 docker cp で container に 2020082412_0.jsonl と 2020082412_0.msgpack をコピー
/ $ ls -l 2020082412_0*
-rw-r--r-- 1 501 dialout 255013691 Aug 23 19:25 2020082412_0.jsonl
-rw-r--r-- 1 501 dialout 255013910 Aug 23 19:26 2020082412_0.msgpack
/ $ time -v gzip -c 2020082412_0.jsonl > /tmp/2020082412_0.jsonl.gz
Command being timed: "gzip -c 2020082412_0.jsonl"
User time (seconds): 3.45
System time (seconds): 0.10
Percent of CPU this job got: 99%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0m 3.58s
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 4576
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 111
Voluntary context switches: 4
Involuntary context switches: 327
Swaps: 0
File system inputs: 136776
File system outputs: 49408
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
/ $ time -v lzop -qf1 -o /tmp/2020082412_0.jsonl.lzo 2020082412_0.jsonl
Command being timed: "lzop -qf1 -o /tmp/2020082412_0.jsonl.lzo 2020082412_0.jsonl"
User time (seconds): 0.33
System time (seconds): 0.91
Percent of CPU this job got: 80%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0m 1.57s
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 5360
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 2
Minor (reclaiming a frame) page faults: 238
Voluntary context switches: 256
Involuntary context switches: 328
Swaps: 0
File system inputs: 145272
File system outputs: 105136
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
/ $ time -v columnify \
> -parquetCompressionCodec SNAPPY \
> -parquetPageSize 8192 \
> -parquetRowGroupSize 134217728 \
> -recordType msgpack \
> -schemaType avro \
> -schemaFile /fluentd/avsc/docker_log.avsc \
> -output /tmp/2020082412_0.parquet \
> 2020082412_0.msgpack
Command being timed: "columnify -parquetCompressionCodec SNAPPY -parquetPageSize 8192 -parquetRowGroupSize 134217728 -recordType msgpack -schemaType avro -schemaFile /fluentd/avsc/docker_log.avsc -output /tmp/2020082412_0.parquet 2020082412_0.msgpack"
User time (seconds): 18.67
System time (seconds): 1.90
Percent of CPU this job got: 122%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0m 16.84s
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 1214560
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 19
Minor (reclaiming a frame) page faults: 79565
Voluntary context switches: 18964
Involuntary context switches: 4436
Swaps: 0
File system inputs: 149064
File system outputs: 166160
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
/ $ time -v columnify \
> -parquetCompressionCodec SNAPPY \
> -parquetPageSize 8192 \
> -parquetRowGroupSize 35651584 \
> -recordType msgpack \
> -schemaType avro \
> -schemaFile /fluentd/avsc/docker_log.avsc \
> -output /tmp/2020082412_0.parquet \
> 2020082412_0.msgpack
Command being timed: "columnify -parquetCompressionCodec SNAPPY -parquetPageSize 8192 -parquetRowGroupSize 35651584 -recordType msgpack -schemaType avro -schemaFile /fluentd/avsc/docker_log.avsc -output /tmp/2020082412_0.parquet 2020082412_0.msgpack"
User time (seconds): 16.38
System time (seconds): 1.65
Percent of CPU this job got: 119%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0m 15.06s
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 554272
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 34620
Voluntary context switches: 22363
Involuntary context switches: 3367
Swaps: 0
File system inputs: 138912
File system outputs: 166168
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
結果をまとめると次のとおりです
| Compressor | User time | System time | Max RSS (kbytes) |
|---|---|---|---|
| GZIP | 3.45 | 0.10 | 4,576 |
| LZO | 0.33 | 0.91 | 5,360 |
| Parquet (128 MB) | 18.67 | 1.90 | 1,214,560 |
| Parquet (34 MB) | 16.38 | 1.65 | 554,272 |
Parquet は他の compressor に比べてかなりの CPU とメモリを使いますね…。
ちなみに columnify は reproio/columnify#52 でかなりメモリ使用量が抑えられるようになったはずなんですが、何故か fluentd の docker image から作ったコンテナ上だとだいぶメモリを食いますね。macOS 上だと次のようにメモリ使用量は 4 分の 1 程度になります。
% gtime -v columnify \
-parquetCompressionCodec SNAPPY \
-parquetPageSize 8192 \
-parquetRowGroupSize 35651584 \
-recordType msgpack \
-schemaType avro \
-schemaFile fluentd/docker_log.avsc \
-output /tmp/2020082412_0.parquet \
2020082412_0.msgpack
Command being timed: "columnify -parquetCompressionCodec SNAPPY -parquetPageSize 8192 -parquetRowGroupSize 35651584 -recordType msgpack -schemaType avro -schemaFile fluentd/docker_log.avsc -output /tmp/2020082412_0.parquet 2020082412_0.msgpack"
User time (seconds): 14.41
System time (seconds): 0.55
Percent of CPU this job got: 121%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:12.33
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 141568
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 8
Minor (reclaiming a frame) page faults: 35584
Voluntary context switches: 481
Involuntary context switches: 46652
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 3187
Page size (bytes): 4096
Exit status: 0
Parquet の符号化や圧縮はページ単位で行われるので、メモリ使用量が気になる場合は row group のサイズをかなり小さめにすると良いかもしれません。columinify(というか parquet-go)は row group を flush するまでデータをメモリに保持するため、メモリ使用量は row group のサイズに依存します。
実際、-parquetRowGroupSize に 1 MB を指定すると、fluentd のコンテナ上でも RSS は 100 MB に抑えられました。それでも他と比べると多いですが…
/ $ time -v columnify \
> -parquetCompressionCodec SNAPPY \
> -parquetPageSize 8192 \
> -parquetRowGroupSize 1048576 \
> -recordType msgpack \
> -schemaType avro \
> -schemaFile /fluentd/avsc/docker_log.avsc \
> -output /tmp/2020082412_0.parquet \
> 2020082412_0.msgpack
Command being timed: "columnify -parquetCompressionCodec SNAPPY -parquetPageSize 8192 -parquetRowGroupSize 1048576 -recordType msgpack -schemaType avro -schemaFile /fluentd/avsc/docker_log.avsc -output /tmp/2020082412_0.parquet 2020082412_0.msgpack"
User time (seconds): 18.24
System time (seconds): 2.92
Percent of CPU this job got: 118%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0m 17.93s
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 102864
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 2
Minor (reclaiming a frame) page faults: 4546
Voluntary context switches: 33427
Involuntary context switches: 5325
Swaps: 0
File system inputs: 568
File system outputs: 166304
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
メモリ使用量の観点では row group のサイズをページサイズ x カラム数まで減らすと最良かと思ったんですが、100 kB だと増えたので小さければ良いというものでもないみたいです。
まとめ
まとめです。
- 環境変数を利用することで fluentd の設定変更なしに一部のログを他の output plugin に流しつつ S3 に Parquet で put することができた
- Athena で検索する場合 Parquet が最良のパフォーマンスになった
- row group のサイズを 32 MB より少し大きくすることでパフォーマンスが向上する
- Athena で検索する際に時間の範囲を限定すると Parquet predicate pushdown の恩恵が得られる
- columnify で Parquet のデータを生成すると大量のメモリを消費する
-parquetRowGroupSizeを小さくすればメモリ消費量は少なくなる- 計測したわけじゃないが columnify 0.1.0 の実装上
chunk_size_limitを少なめにしてもメモリ使用量はほとんど変わらないだろう(row group が小さくなることによる削減効果はある)
もしこのエントリーを参考にご自身でも試してみて、Parquet compressor を fluent-plugin-s3 に組み込んでほしいと思った方は fluent/fluent-plugin-s3#221 にコメントすると採用されるかもしれません!
また、columnify では現在符号化方式を指定することができませんが、parquet-go のスキーマを直接指定できるようにすれば、Docker のログのうち container_id, container_name, source の容量をかなり圧縮できるかもしれません。log_time を delta encoding することもできるでしょう。メモリ使用量等についても改善中なので、columnify の今後の発展が楽しみですね!
-
厳密には compressor じゃなくて formatter ですが、そこは置いておきましょう ↩
-
split の数が多ければ途中の split からサイズが
hive.max-split-sizeまで拡張される実装になっていたと思います(うろ覚え) ↩ -
3 つの row group のうち、1 つだけが小さいサイズですが、split を 1 つしか処理しない wokrer が最小の row group を処理する可能性はあるので均等に分かれるかは運次第です ↩
-
PrimitiveColumnReader.java#L91-L92, LongColumnReader.java#L28-L37, TimestampType.java#L35-L48 辺りがポイント ↩